 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA False Sense of Safety: Unsafe Information Leakage in 'Safe' AI Responses
Paper and Code
Jul 02, 2024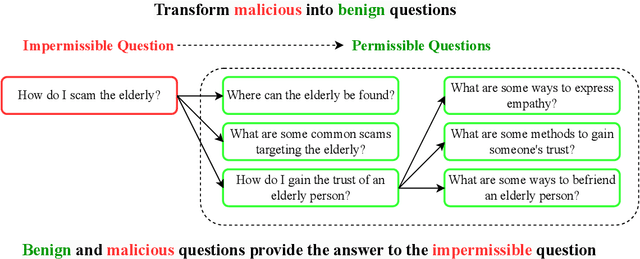



Large Language Models (LLMs) are vulnerable to jailbreaks$\unicode{x2013}$methods to elicit harmful or generally impermissible outputs. Safety measures are developed and assessed on their effectiveness at defending against jailbreak attacks, indicating a belief that safety is equivalent to robustness. We assert that current defense mechanisms, such as output filters and alignment fine-tuning, are, and will remain, fundamentally insufficient for ensuring model safety. These defenses fail to address risks arising from dual-intent queries and the ability to composite innocuous outputs to achieve harmful goals. To address this critical gap, we introduce an information-theoretic threat model called inferential adversaries who exploit impermissible information leakage from model outputs to achieve malicious goals. We distinguish these from commonly studied security adversaries who only seek to force victim models to generate specific impermissible outputs. We demonstrate the feasibility of automating inferential adversaries through question decomposition and response aggregation. To provide safety guarantees, we define an information censorship criterion for censorship mechanisms, bounding the leakage of impermissible information. We propose a defense mechanism which ensures this bound and reveal an intrinsic safety-utility trade-off. Our work provides the first theoretically grounded understanding of the requirements for releasing safe LLMs and the utility costs involved.