 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntidoteRT: Run-time Detection and Correction of Poison Attacks on Neural Networks
Paper and Code
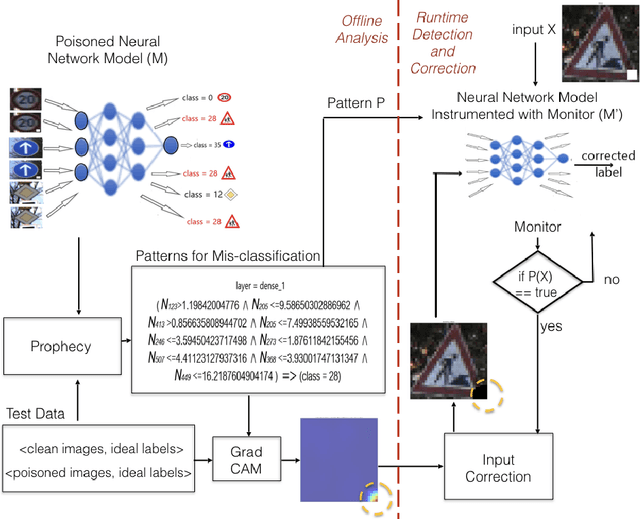



We study backdoor poisoning attacks against image classification networks, whereby an attacker inserts a trigger into a subset of the training data, in such a way that at test time, this trigger causes the classifier to predict some target class. %There are several techniques proposed in the literature that aim to detect the attack but only a few also propose to defend against it, and they typically involve retraining the network which is not always possible in practice. We propose lightweight automated detection and correction techniques against poisoning attacks, which are based on neuron patterns mined from the network using a small set of clean and poisoned test samples with known labels. The patterns built based on the mis-classified samples are used for run-time detection of new poisoned inputs. For correction, we propose an input correction technique that uses a differential analysis to identify the trigger in the detected poisoned images, which is then reset to a neutral color. Our detection and correction are performed at run-time and input level, which is in contrast to most existing work that is focused on offline model-level defenses. We demonstrate that our technique outperforms existing defenses such as NeuralCleanse and STRIP on popular benchmarks such as MNIST, CIFAR-10, and GTSRB against the popular BadNets attack and the more complex DFST attack.