 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorJoin: A New Cardinality Estimation Framework for Join Queries
Dec 11, 2022
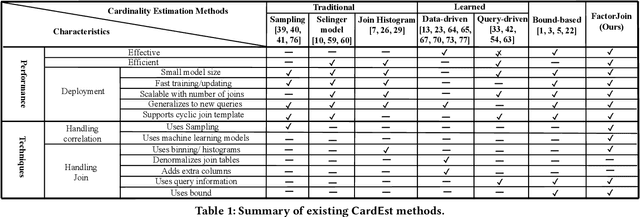
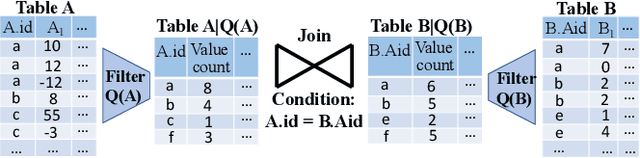
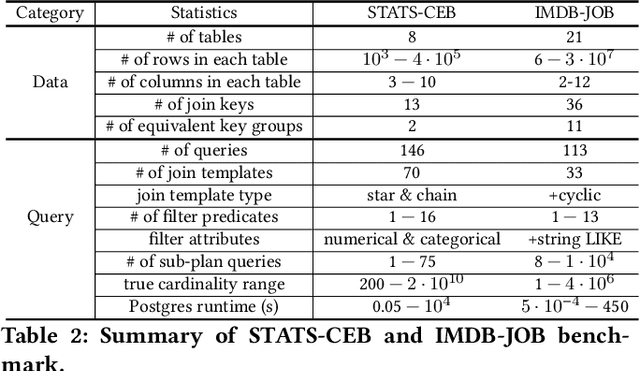
Cardinality estimation is one of the most fundamental and challenging problems in query optimization. Neither classical nor learning-based methods yield satisfactory performance when estimating the cardinality of the join queries. They either rely on simplified assumptions leading to ineffective cardinality estimates or build large models to understand the data distributions, leading to long planning times and a lack of generalizability across queries. In this paper, we propose a new framework FactorJoin for estimating join queries. FactorJoin combines the idea behind the classical join-histogram method to efficiently handle joins with the learning-based methods to accurately capture attribute correlation. Specifically, FactorJoin scans every table in a DB and builds single-table conditional distributions during an offline preparation phase. When a join query comes, FactorJoin translates it into a factor graph model over the learned distributions to effectively and efficiently estimate its cardinality. Unlike existing learning-based methods, FactorJoin does not need to de-normalize joins upfront or require executed query workloads to train the model. Since it only relies on single-table statistics, FactorJoin has small space overhead and is extremely easy to train and maintain. In our evaluation, FactorJoin can produce more effective estimates than the previous state-of-the-art learning-based methods, with 40x less estimation latency, 100x smaller model size, and 100x faster training speed at comparable or better accuracy. In addition, FactorJoin can estimate 10,000 sub-plan queries within one second to optimize the query plan, which is very close to the traditional cardinality estimators in commercial DBMS.