 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Knowledge Distillation
Paper and Code
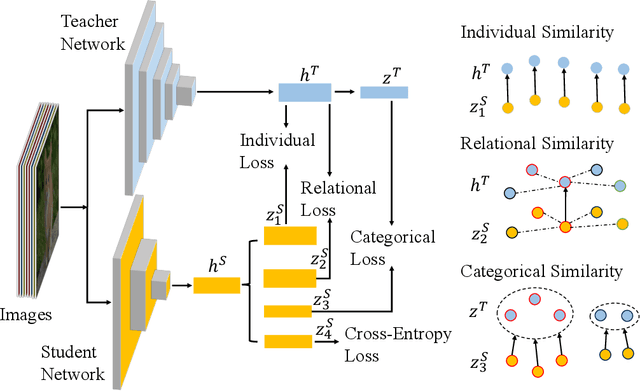
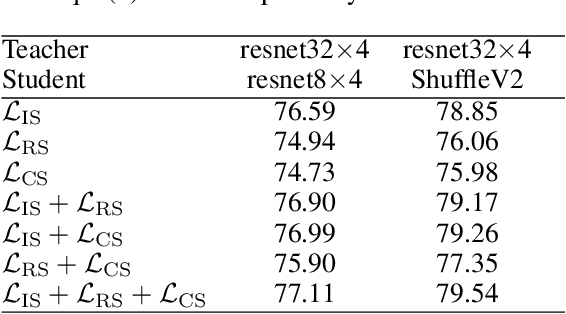
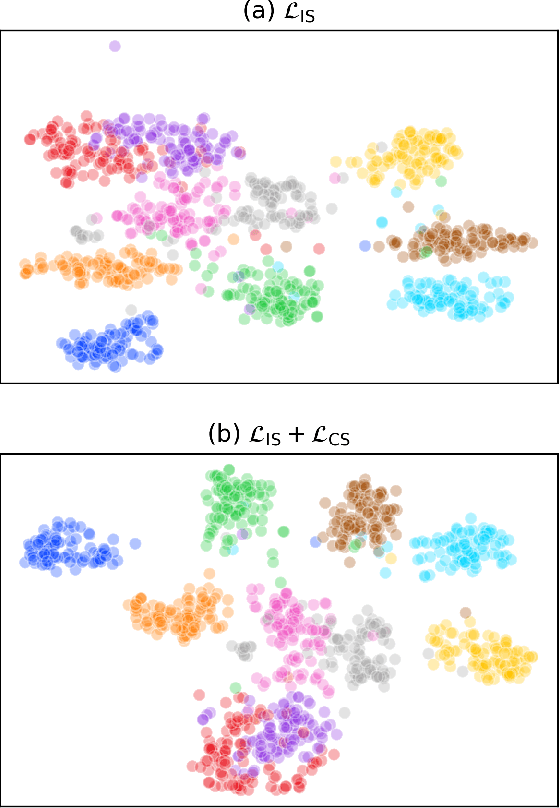
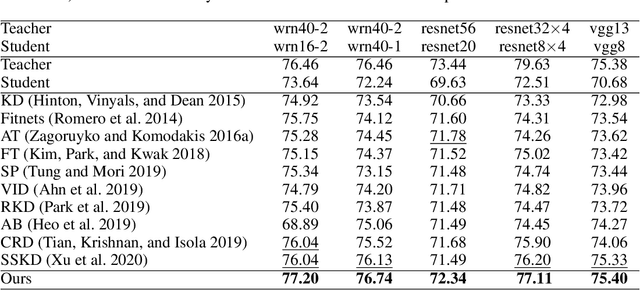
Knowledge distillation has become an important technique for model compression and acceleration. The conventional knowledge distillation approaches aim to transfer knowledge from teacher to student networks by minimizing the KL-divergence between their probabilistic outputs, which only consider the mutual relationship between individual representations of teacher and student networks. Recently, the contrastive loss-based knowledge distillation is proposed to enable a student to learn the instance discriminative knowledge of a teacher by mapping the same image close and different images far away in the representation space. However, all of these methods ignore that the teacher's knowledge is multi-level, e.g., individual, relational and categorical level. These different levels of knowledge cannot be effectively captured by only one kind of supervisory signal. Here, we introduce Multi-level Knowledge Distillation (MLKD) to transfer richer representational knowledge from teacher to student networks. MLKD employs three novel teacher-student similarities: individual similarity, relational similarity, and categorical similarity, to encourage the student network to learn sample-wise, structure-wise and category-wise knowledge in the teacher network. Experiments demonstrate that MLKD outperforms other state-of-the-art methods on both similar-architecture and cross-architecture tasks. We further show that MLKD can improve the transferability of learned representations in the student network.