 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRallying Adversarial Techniques against Deep Learning for Network Security
Paper and Code
Mar 27, 2019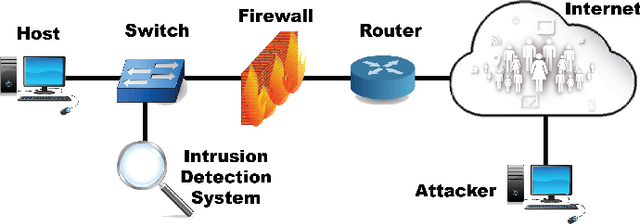
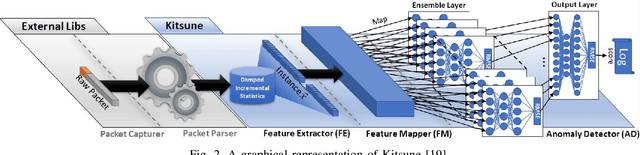
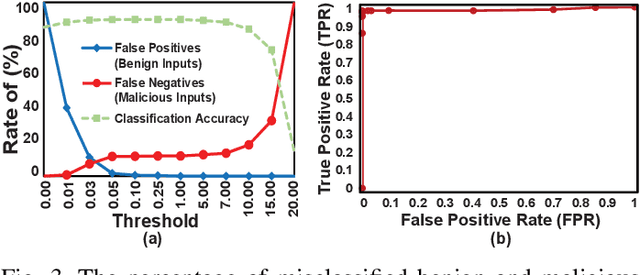
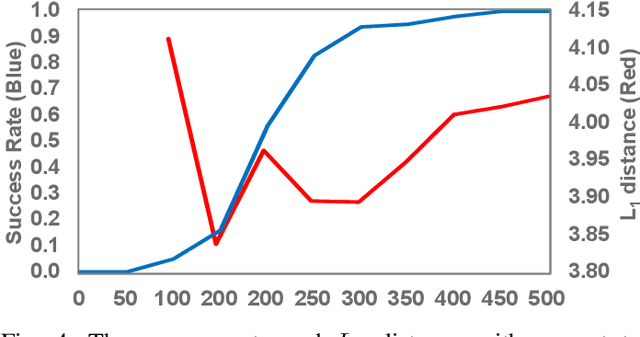
Recent advances in artificial intelligence and the increasing need for powerful defensive measures in the domain of network security, have led to the adoption of deep learning approaches for use in network intrusion detection systems. These methods have achieved superior performance against conventional network attacks, which enable the deployment of practical security systems to unique and dynamic sectors. Adversarial machine learning, unfortunately, has recently shown that deep learning models are inherently vulnerable to adversarial modifications on their input data. Because of this susceptibility, the deep learning models deployed to power a network defense could in fact be the weakest entry point for compromising a network system. In this paper, we show that by modifying on average as little as 1.38 of the input features, an adversary can generate malicious inputs which effectively fool a deep learning based NIDS. Therefore, when designing such systems, it is crucial to consider the performance from not only the conventional network security perspective but also the adversarial machine learning domain.