 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Matrix Factorization Based Graph Contrastive Learning for Recommendation System
Sep 05, 2025In recent years, methods that combine contrastive learning with graph neural networks have emerged to address the challenges of recommendation systems, demonstrating powerful performance and playing a significant role in this domain. Contrastive learning primarily tackles the issue of data sparsity by employing data augmentation strategies, effectively alleviating this problem and showing promising results. Although existing research has achieved favorable outcomes, most current graph contrastive learning methods are based on two types of data augmentation strategies: the first involves perturbing the graph structure, such as by randomly adding or removing edges; and the second applies clustering techniques. We believe that the interactive information obtained through these two strategies does not fully capture the user-item interactions. In this paper, we propose a novel method called HMFGCL (Hybrid Matrix Factorization Based Graph Contrastive Learning), which integrates two distinct matrix factorization techniques-low-rank matrix factorization (MF) and singular value decomposition (SVD)-to complementarily acquire global collaborative information, thereby constructing enhanced views. Experimental results on multiple public datasets demonstrate that our model outperforms existing baselines, particularly on small-scale datasets.
Effectively Prompting Small-sized Language Models for Cross-lingual Tasks via Winning Tickets
Apr 01, 2024



Current soft prompt methods yield limited performance when applied to small-sized models (fewer than a billion parameters). Deep prompt-tuning, which entails prepending parameters in each layer for enhanced efficacy, presents a solution for prompting small-sized models, albeit requiring carefully designed implementation. In this paper, we introduce the Lottery Ticket Prompt-learning (LTP) framework that integrates winning tickets with soft prompts. The LTP offers a simpler implementation and requires only a one-time execution. We demonstrate LTP on cross-lingual tasks, where prior works rely on external tools like human-designed multilingual templates and bilingual dictionaries, which may not be feasible in a low-resource regime. Specifically, we select a subset of parameters that have been changed the most during the fine-tuning with the Masked Language Modeling objective. Then, we prepend soft prompts to the original pre-trained language model and only update the selected parameters together with prompt-related parameters when adapting to the downstream tasks. We verify the effectiveness of our LTP framework on cross-lingual tasks, specifically targeting low-resource languages. Our approach outperforms the baselines by only updating 20\% of the original parameters.
Multi-level Distillation of Semantic Knowledge for Pre-training Multilingual Language Model
Nov 02, 2022



Pre-trained multilingual language models play an important role in cross-lingual natural language understanding tasks. However, existing methods did not focus on learning the semantic structure of representation, and thus could not optimize their performance. In this paper, we propose Multi-level Multilingual Knowledge Distillation (MMKD), a novel method for improving multilingual language models. Specifically, we employ a teacher-student framework to adopt rich semantic representation knowledge in English BERT. We propose token-, word-, sentence-, and structure-level alignment objectives to encourage multiple levels of consistency between source-target pairs and correlation similarity between teacher and student models. We conduct experiments on cross-lingual evaluation benchmarks including XNLI, PAWS-X, and XQuAD. Experimental results show that MMKD outperforms other baseline models of similar size on XNLI and XQuAD and obtains comparable performance on PAWS-X. Especially, MMKD obtains significant performance gains on low-resource languages.
Segmentation with Multiple Acceptable Annotations: A Case Study of Myocardial Segmentation in Contrast Echocardiography
Jun 29, 2021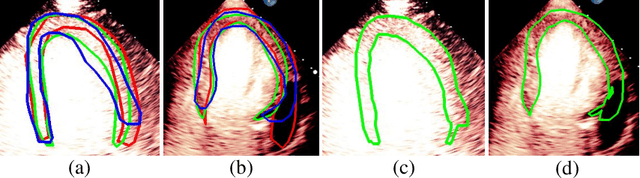
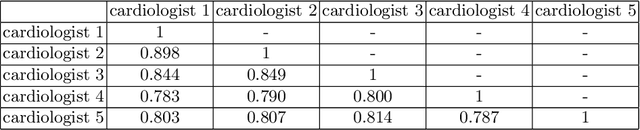
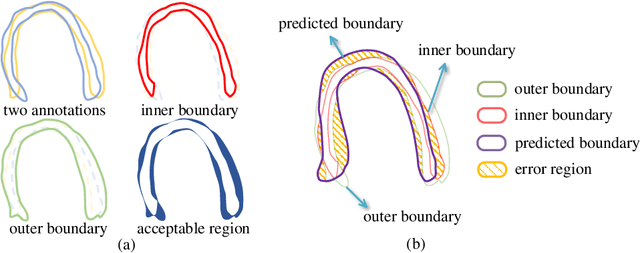
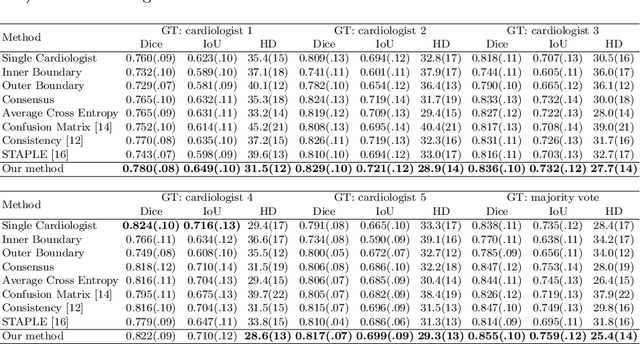
Most existing deep learning-based frameworks for image segmentation assume that a unique ground truth is known and can be used for performance evaluation. This is true for many applications, but not all. Myocardial segmentation of Myocardial Contrast Echocardiography (MCE), a critical task in automatic myocardial perfusion analysis, is an example. Due to the low resolution and serious artifacts in MCE data, annotations from different cardiologists can vary significantly, and it is hard to tell which one is the best. In this case, how can we find a good way to evaluate segmentation performance and how do we train the neural network? In this paper, we address the first problem by proposing a new extended Dice to effectively evaluate the segmentation performance when multiple accepted ground truth is available. Then based on our proposed metric, we solve the second problem by further incorporating the new metric into a loss function that enables neural networks to flexibly learn general features of myocardium. Experiment results on our clinical MCE data set demonstrate that the neural network trained with the proposed loss function outperforms those existing ones that try to obtain a unique ground truth from multiple annotations, both quantitatively and qualitatively. Finally, our grading study shows that using extended Dice as an evaluation metric can better identify segmentation results that need manual correction compared with using Dice.