 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftmax Linear Attention: Reclaiming Global Competition
Feb 02, 2026While linear attention reduces the quadratic complexity of standard Transformers to linear time, it often lags behind in expressivity due to the removal of softmax normalization. This omission eliminates \emph{global competition}, a critical mechanism that enables models to sharply focus on relevant information amidst long-context noise. In this work, we propose \textbf{Softmax Linear Attention (SLA)}, a framework designed to restore this competitive selection without sacrificing efficiency. By lifting the softmax operation from the token level to the head level, SLA leverages attention heads as coarse semantic slots, applying a competitive gating mechanism to dynamically select the most relevant subspaces. This reintroduces the ``winner-take-all'' dynamics essential for precise retrieval and robust long-context understanding. Distinct from prior methods that focus on refining local kernel functions, SLA adopts a broader perspective by exploiting the higher-level multi-head aggregation structure. Extensive experiments demonstrate that SLA consistently enhances state-of-the-art linear baselines (RetNet, GLA, GDN) across language modeling and long-context benchmarks, particularly in challenging retrieval scenarios where it significantly boosts robustness against noise, validating its capability to restore precise focus while maintaining linear complexity.
Homogeneous Keys, Heterogeneous Values: Exploiting Local KV Cache Asymmetry for Long-Context LLMs
Jun 04, 2025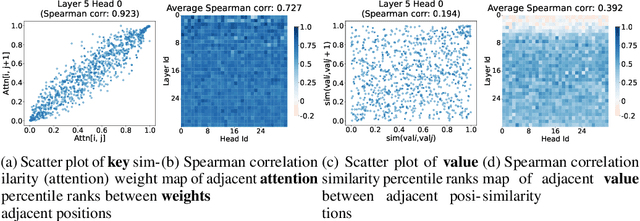
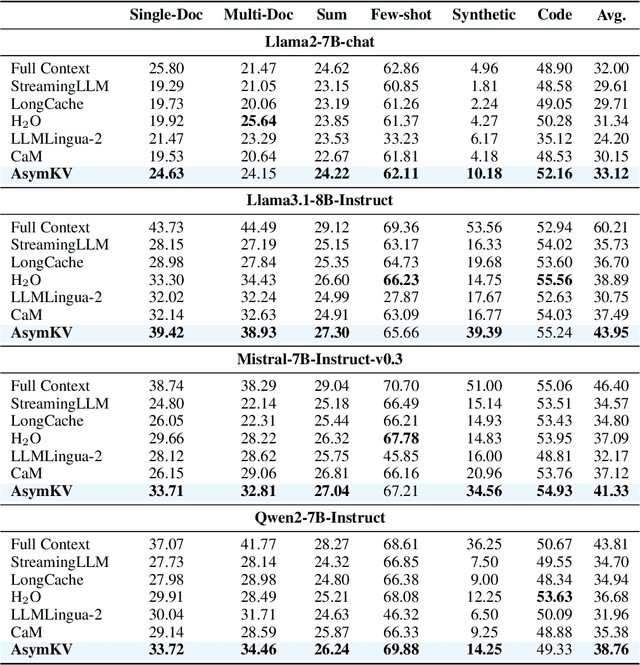
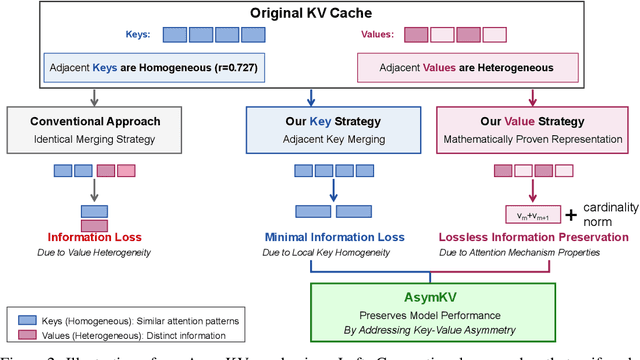
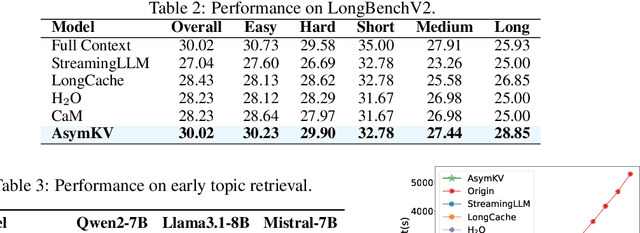
Recent advances in Large Language Models (LLMs) have highlighted the critical importance of extending context length, yet the quadratic complexity of attention mechanisms poses significant challenges for efficient long-context modeling. KV cache compression has emerged as a key approach to address this challenge. Through extensive empirical analysis, we reveal a fundamental yet previously overlooked asymmetry in KV caches: while adjacent keys receive similar attention weights (local homogeneity), adjacent values demonstrate distinct heterogeneous distributions. This key-value asymmetry reveals a critical limitation in existing compression methods that treat keys and values uniformly. To address the limitation, we propose a training-free compression framework (AsymKV) that combines homogeneity-based key merging with a mathematically proven lossless value compression. Extensive experiments demonstrate that AsymKV consistently outperforms existing long-context methods across various tasks and base models. For example, on LLaMA3.1-8B, AsymKV achieves an average score of 43.95 on LongBench, surpassing SOTA methods like H$_2$O (38.89) by a large margin.
Cherry on Top: Parameter Heterogeneity and Quantization in Large Language Models
Apr 03, 2024This paper reveals the phenomenon of parameter heterogeneity in large language models (LLMs). We find that a small subset of ``cherry'' parameters exhibit a disproportionately large influence on model performance, while the vast majority of parameters have minimal impact. This heterogeneity is found to be prevalent across different model families, scales, and types. Motivated by this observation, we propose CherryQ, a novel quantization method that unifies the optimization of mixed-precision parameters. CherryQ identifies and preserves the critical cherry parameters in high precision while aggressively quantizing the remaining parameters to low precision. Extensive experiments demonstrate the effectiveness of CherryQ. CherryQ outperforms existing quantization approaches in terms of perplexity and downstream task performance. Notably, our 3-bit quantized Vicuna-1.5 exhibits competitive performance compared to their 16-bit counterparts. These findings highlight the potential of CherryQ for enabling efficient deployment of LLMs by taking advantage of parameter heterogeneity.
Who Said That? Benchmarking Social Media AI Detection
Oct 12, 2023AI-generated text has proliferated across various online platforms, offering both transformative prospects and posing significant risks related to misinformation and manipulation. Addressing these challenges, this paper introduces SAID (Social media AI Detection), a novel benchmark developed to assess AI-text detection models' capabilities in real social media platforms. It incorporates real AI-generate text from popular social media platforms like Zhihu and Quora. Unlike existing benchmarks, SAID deals with content that reflects the sophisticated strategies employed by real AI users on the Internet which may evade detection or gain visibility, providing a more realistic and challenging evaluation landscape. A notable finding of our study, based on the Zhihu dataset, reveals that annotators can distinguish between AI-generated and human-generated texts with an average accuracy rate of 96.5%. This finding necessitates a re-evaluation of human capability in recognizing AI-generated text in today's widely AI-influenced environment. Furthermore, we present a new user-oriented AI-text detection challenge focusing on the practicality and effectiveness of identifying AI-generated text based on user information and multiple responses. The experimental results demonstrate that conducting detection tasks on actual social media platforms proves to be more challenging compared to traditional simulated AI-text detection, resulting in a decreased accuracy. On the other hand, user-oriented AI-generated text detection significantly improve the accuracy of detection.
Ada-Instruct: Adapting Instruction Generators for Complex Reasoning
Oct 10, 2023Generating diverse and sophisticated instructions for downstream tasks by Large Language Models (LLMs) is pivotal for advancing the effect. Current approaches leverage closed-source LLMs, employing in-context prompting for instruction generation. However, in this paper, we found that in-context prompting cannot generate complex instructions with length $\ge 100$ for tasks like code completion. To solve this problem, we introduce Ada-Instruct, an adaptive instruction generator developed by fine-tuning open-source LLMs. Our pivotal finding illustrates that fine-tuning open-source LLMs with a mere ten samples generates long instructions that maintain distributional consistency for complex reasoning tasks. We empirically validated Ada-Instruct's efficacy across different applications, including code completion, mathematical reasoning, and commonsense reasoning. The results underscore Ada-Instruct's superiority, evidencing its improvements over its base models, current self-instruct methods, and other state-of-the-art models.
Evade ChatGPT Detectors via A Single Space
Jul 05, 2023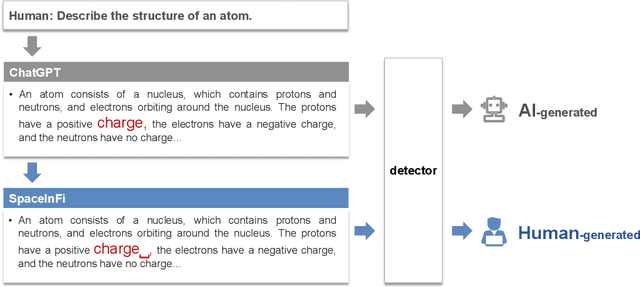
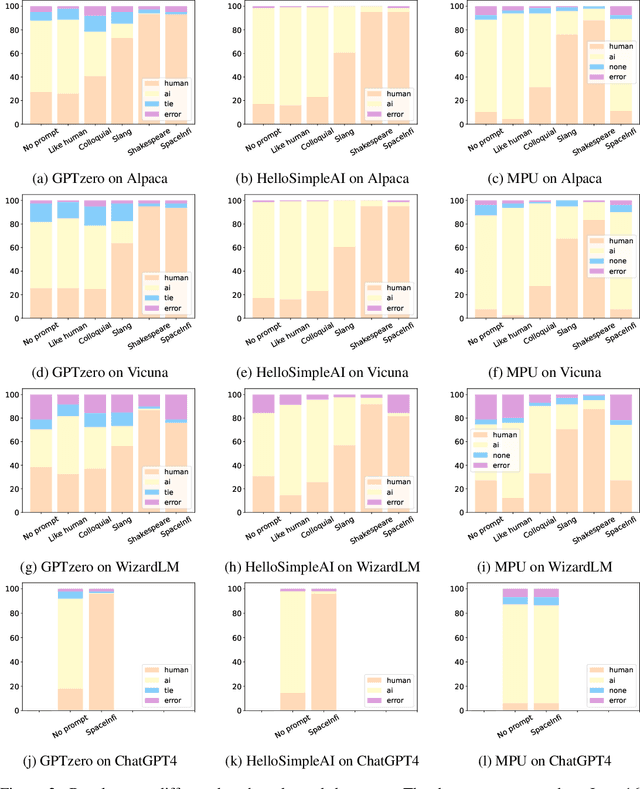
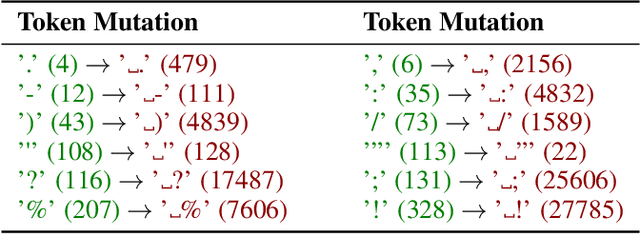

ChatGPT brings revolutionary social value but also raises concerns about the misuse of AI-generated content. Consequently, an important question is how to detect whether content is generated by ChatGPT or by human. Existing detectors are built upon the assumption that there are distributional gaps between human-generated and AI-generated content. These gaps are typically identified using statistical information or classifiers. Our research challenges the distributional gap assumption in detectors. We find that detectors do not effectively discriminate the semantic and stylistic gaps between human-generated and AI-generated content. Instead, the "subtle differences", such as an extra space, become crucial for detection. Based on this discovery, we propose the SpaceInfi strategy to evade detection. Experiments demonstrate the effectiveness of this strategy across multiple benchmarks and detectors. We also provide a theoretical explanation for why SpaceInfi is successful in evading perplexity-based detection. Our findings offer new insights and challenges for understanding and constructing more applicable ChatGPT detectors.
Free Lunch for Efficient Textual Commonsense Integration in Language Models
May 24, 2023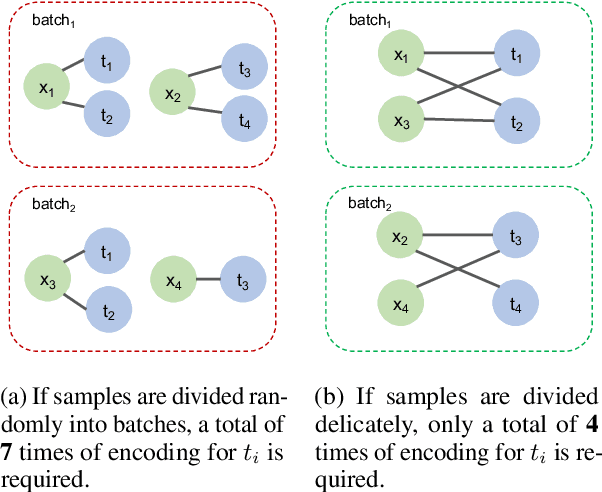

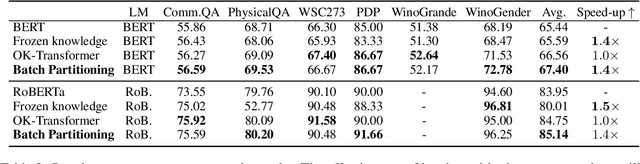
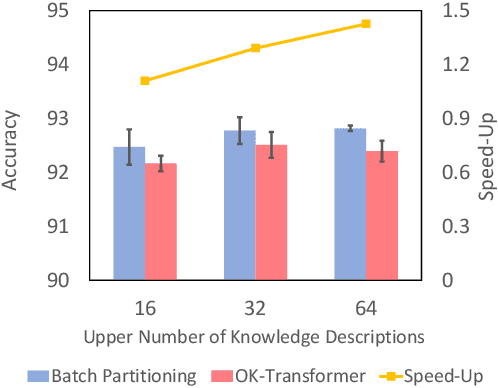
Recent years have witnessed the emergence of textual commonsense knowledge bases, aimed at providing more nuanced and context-rich knowledge. The integration of external commonsense into language models has been shown to be a key enabler in advancing the state-of-the-art for a wide range of NLP tasks. However, incorporating textual commonsense descriptions is computationally expensive, as compared to encoding conventional symbolic knowledge. In this paper, we propose a method to improve its efficiency without modifying the model. We group training samples with similar commonsense descriptions into a single batch, thus reusing the encoded description across multiple samples. One key observation is that the upper bound of batch partitioning can be reduced to the classic {\it graph k-cut problem}. Consequently, we propose a spectral clustering-based algorithm to solve this problem. Extensive experiments illustrate that the proposed batch partitioning approach effectively reduces the computational cost while preserving performance. The efficiency improvement is more pronounced on larger datasets and on devices with more memory capacity, attesting to its practical utility for large-scale applications.
Exploring Automatically Perturbed Natural Language Explanations in Relation Extraction
May 24, 2023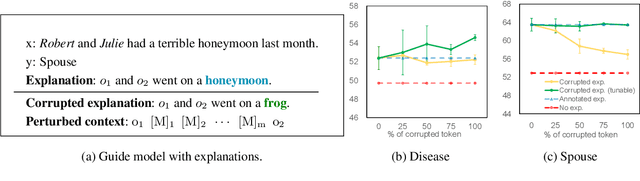
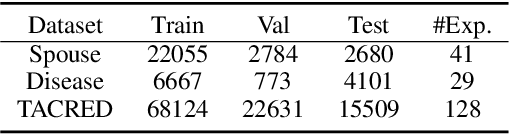
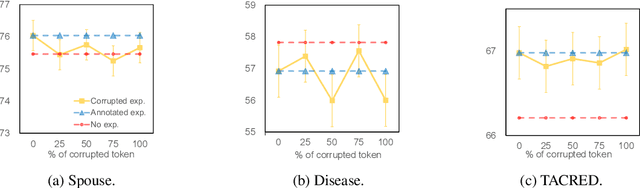
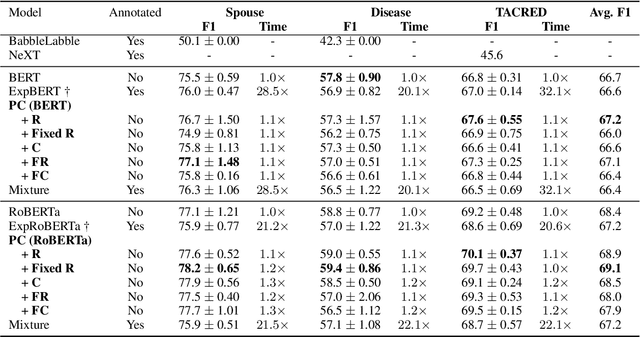
Previous research has demonstrated that natural language explanations provide valuable inductive biases that guide models, thereby improving the generalization ability and data efficiency. In this paper, we undertake a systematic examination of the effectiveness of these explanations. Remarkably, we find that corrupted explanations with diminished inductive biases can achieve competitive or superior performance compared to the original explanations. Our findings furnish novel insights into the characteristics of natural language explanations in the following ways: (1) the impact of explanations varies across different training styles and datasets, with previously believed improvements primarily observed in frozen language models. (2) While previous research has attributed the effect of explanations solely to their inductive biases, our study shows that the effect persists even when the explanations are completely corrupted. We propose that the main effect is due to the provision of additional context space. (3) Utilizing the proposed automatic perturbed context, we were able to attain comparable results to annotated explanations, but with a significant increase in computational efficiency, 20-30 times faster.
Instance-based Learning for Knowledge Base Completion
Nov 13, 2022



In this paper, we propose a new method for knowledge base completion (KBC): instance-based learning (IBL). For example, to answer (Jill Biden, lived city,? ), instead of going directly to Washington D.C., our goal is to find Joe Biden, who has the same lived city as Jill Biden. Through prototype entities, IBL provides interpretability. We develop theories for modeling prototypes and combining IBL with translational models. Experiments on various tasks confirmed the IBL model's effectiveness and interpretability. In addition, IBL shed light on the mechanism of rule-based KBC models. Previous research has generally agreed that rule-based models provide rules with semantically compatible premises and hypotheses. We challenge this view. We begin by demonstrating that some logical rules represent {\it instance-based equivalence} (i.e. prototypes) rather than semantic compatibility. These are denoted as {\it IBL rules}. Surprisingly, despite occupying only a small portion of the rule space, IBL rules outperform non-IBL rules in all four benchmarks. We use a variety of experiments to demonstrate that rule-based models work because they have the ability to represent instance-based equivalence via IBL rules. The findings provide new insights of how rule-based models work and how to interpret their rules.
Open Rule Induction
Oct 26, 2021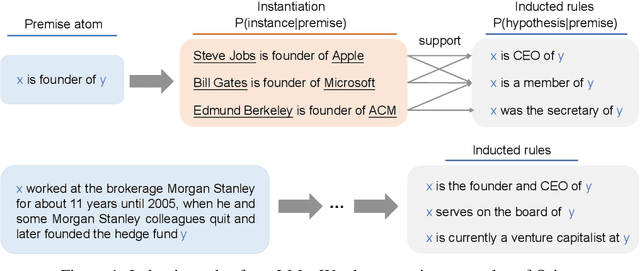
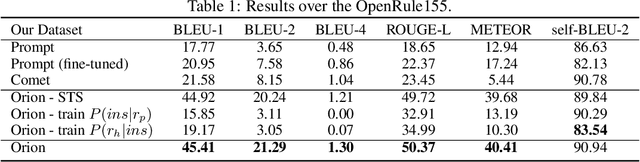


Rules have a number of desirable properties. It is easy to understand, infer new knowledge, and communicate with other inference systems. One weakness of the previous rule induction systems is that they only find rules within a knowledge base (KB) and therefore cannot generalize to more open and complex real-world rules. Recently, the language model (LM)-based rule generation are proposed to enhance the expressive power of the rules. In this paper, we revisit the differences between KB-based rule induction and LM-based rule generation. We argue that, while KB-based methods inducted rules by discovering data commonalities, the current LM-based methods are "learning rules from rules". This limits these methods to only produce "canned" rules whose patterns are constrained by the annotated rules, while discarding the rich expressive power of LMs for free text. Therefore, in this paper, we propose the open rule induction problem, which aims to induce open rules utilizing the knowledge in LMs. Besides, we propose the Orion (\underline{o}pen \underline{r}ule \underline{i}nducti\underline{on}) system to automatically mine open rules from LMs without supervision of annotated rules. We conducted extensive experiments to verify the quality and quantity of the inducted open rules. Surprisingly, when applying the open rules in downstream tasks (i.e. relation extraction), these automatically inducted rules even outperformed the manually annotated rules.