 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Lunch for Efficient Textual Commonsense Integration in Language Models
Paper and Code
May 24, 2023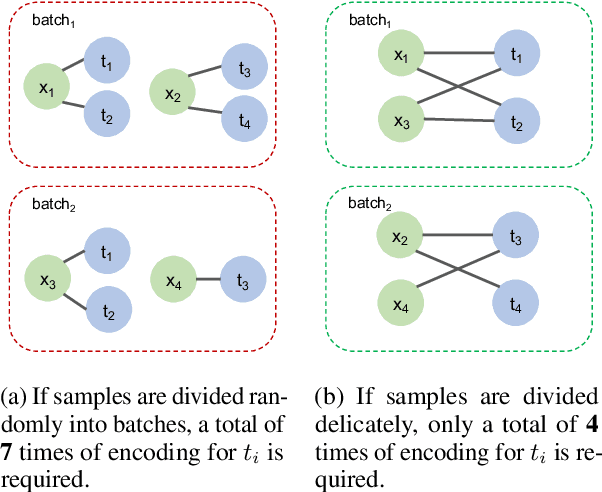

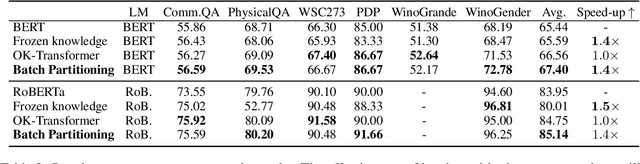
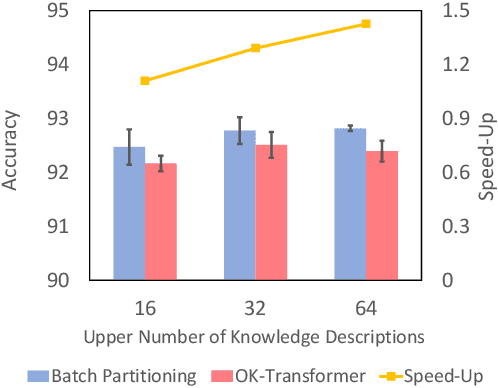
Recent years have witnessed the emergence of textual commonsense knowledge bases, aimed at providing more nuanced and context-rich knowledge. The integration of external commonsense into language models has been shown to be a key enabler in advancing the state-of-the-art for a wide range of NLP tasks. However, incorporating textual commonsense descriptions is computationally expensive, as compared to encoding conventional symbolic knowledge. In this paper, we propose a method to improve its efficiency without modifying the model. We group training samples with similar commonsense descriptions into a single batch, thus reusing the encoded description across multiple samples. One key observation is that the upper bound of batch partitioning can be reduced to the classic {\it graph k-cut problem}. Consequently, we propose a spectral clustering-based algorithm to solve this problem. Extensive experiments illustrate that the proposed batch partitioning approach effectively reduces the computational cost while preserving performance. The efficiency improvement is more pronounced on larger datasets and on devices with more memory capacity, attesting to its practical utility for large-scale applications.