 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCherry on Top: Parameter Heterogeneity and Quantization in Large Language Models
Apr 03, 2024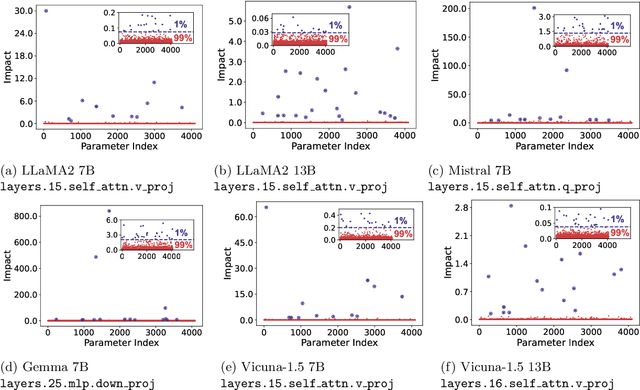
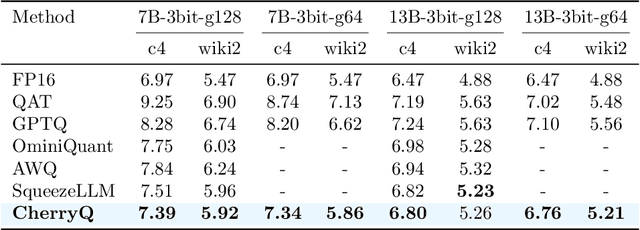
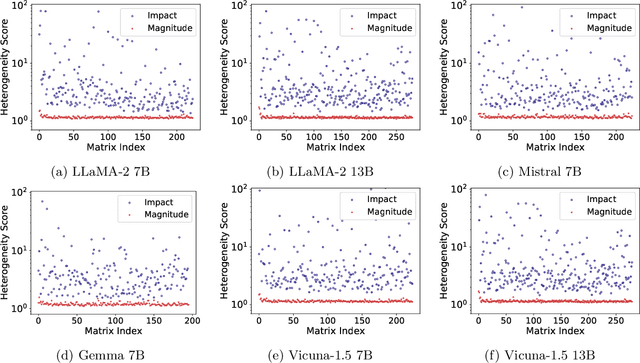
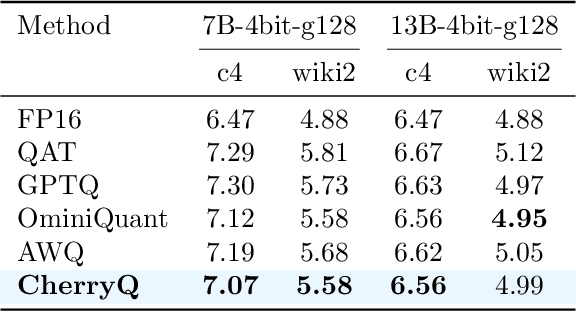
This paper reveals the phenomenon of parameter heterogeneity in large language models (LLMs). We find that a small subset of ``cherry'' parameters exhibit a disproportionately large influence on model performance, while the vast majority of parameters have minimal impact. This heterogeneity is found to be prevalent across different model families, scales, and types. Motivated by this observation, we propose CherryQ, a novel quantization method that unifies the optimization of mixed-precision parameters. CherryQ identifies and preserves the critical cherry parameters in high precision while aggressively quantizing the remaining parameters to low precision. Extensive experiments demonstrate the effectiveness of CherryQ. CherryQ outperforms existing quantization approaches in terms of perplexity and downstream task performance. Notably, our 3-bit quantized Vicuna-1.5 exhibits competitive performance compared to their 16-bit counterparts. These findings highlight the potential of CherryQ for enabling efficient deployment of LLMs by taking advantage of parameter heterogeneity.
Who Said That? Benchmarking Social Media AI Detection
Oct 12, 2023



AI-generated text has proliferated across various online platforms, offering both transformative prospects and posing significant risks related to misinformation and manipulation. Addressing these challenges, this paper introduces SAID (Social media AI Detection), a novel benchmark developed to assess AI-text detection models' capabilities in real social media platforms. It incorporates real AI-generate text from popular social media platforms like Zhihu and Quora. Unlike existing benchmarks, SAID deals with content that reflects the sophisticated strategies employed by real AI users on the Internet which may evade detection or gain visibility, providing a more realistic and challenging evaluation landscape. A notable finding of our study, based on the Zhihu dataset, reveals that annotators can distinguish between AI-generated and human-generated texts with an average accuracy rate of 96.5%. This finding necessitates a re-evaluation of human capability in recognizing AI-generated text in today's widely AI-influenced environment. Furthermore, we present a new user-oriented AI-text detection challenge focusing on the practicality and effectiveness of identifying AI-generated text based on user information and multiple responses. The experimental results demonstrate that conducting detection tasks on actual social media platforms proves to be more challenging compared to traditional simulated AI-text detection, resulting in a decreased accuracy. On the other hand, user-oriented AI-generated text detection significantly improve the accuracy of detection.
Ada-Instruct: Adapting Instruction Generators for Complex Reasoning
Oct 10, 2023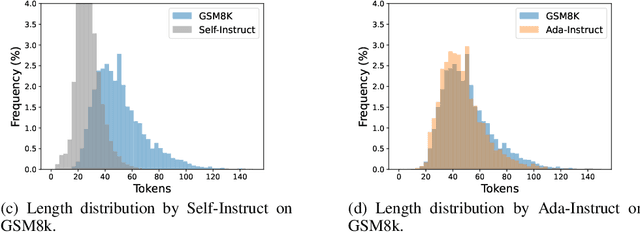
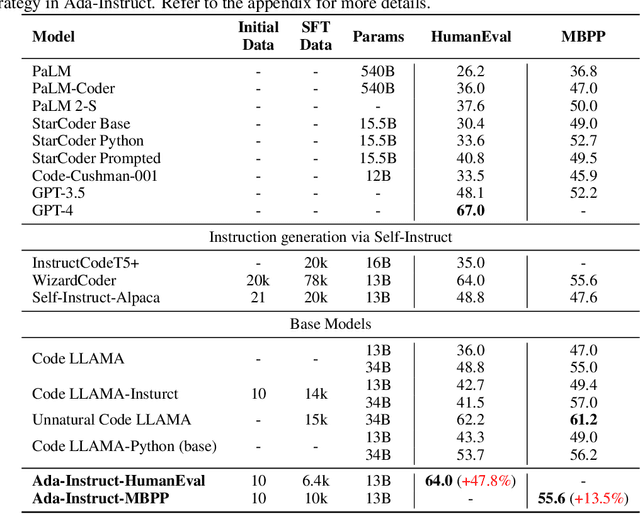
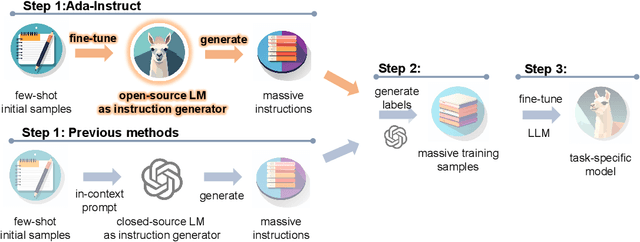

Generating diverse and sophisticated instructions for downstream tasks by Large Language Models (LLMs) is pivotal for advancing the effect. Current approaches leverage closed-source LLMs, employing in-context prompting for instruction generation. However, in this paper, we found that in-context prompting cannot generate complex instructions with length $\ge 100$ for tasks like code completion. To solve this problem, we introduce Ada-Instruct, an adaptive instruction generator developed by fine-tuning open-source LLMs. Our pivotal finding illustrates that fine-tuning open-source LLMs with a mere ten samples generates long instructions that maintain distributional consistency for complex reasoning tasks. We empirically validated Ada-Instruct's efficacy across different applications, including code completion, mathematical reasoning, and commonsense reasoning. The results underscore Ada-Instruct's superiority, evidencing its improvements over its base models, current self-instruct methods, and other state-of-the-art models.