 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePencil: Private and Extensible Collaborative Learning without the Non-Colluding Assumption
Mar 17, 2024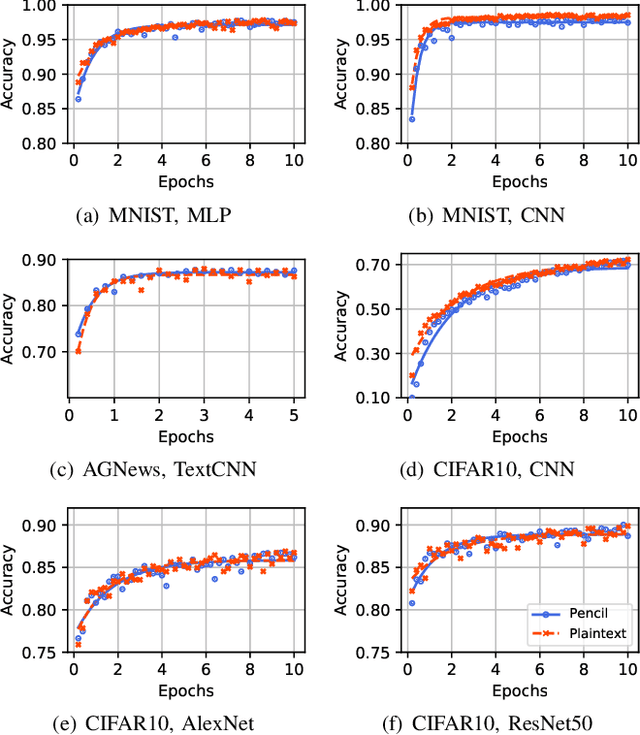
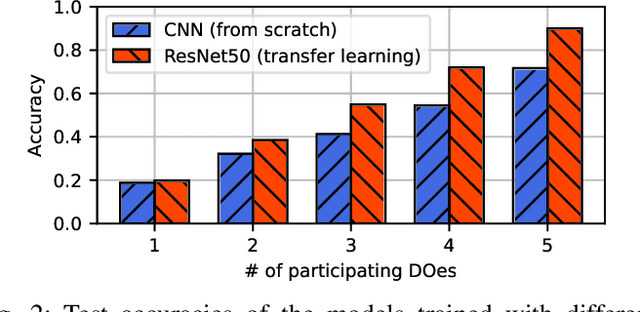


The escalating focus on data privacy poses significant challenges for collaborative neural network training, where data ownership and model training/deployment responsibilities reside with distinct entities. Our community has made substantial contributions to addressing this challenge, proposing various approaches such as federated learning (FL) and privacy-preserving machine learning based on cryptographic constructs like homomorphic encryption (HE) and secure multiparty computation (MPC). However, FL completely overlooks model privacy, and HE has limited extensibility (confined to only one data provider). While the state-of-the-art MPC frameworks provide reasonable throughput and simultaneously ensure model/data privacy, they rely on a critical non-colluding assumption on the computing servers, and relaxing this assumption is still an open problem. In this paper, we present Pencil, the first private training framework for collaborative learning that simultaneously offers data privacy, model privacy, and extensibility to multiple data providers, without relying on the non-colluding assumption. Our fundamental design principle is to construct the n-party collaborative training protocol based on an efficient two-party protocol, and meanwhile ensuring that switching to different data providers during model training introduces no extra cost. We introduce several novel cryptographic protocols to realize this design principle and conduct a rigorous security and privacy analysis. Our comprehensive evaluations of Pencil demonstrate that (i) models trained in plaintext and models trained privately using Pencil exhibit nearly identical test accuracies; (ii) The training overhead of Pencil is greatly reduced: Pencil achieves 10 ~ 260x higher throughput and 2 orders of magnitude less communication than prior art; (iii) Pencil is resilient against both existing and adaptive (white-box) attacks.
* Network and Distributed System Security Symposium (NDSS) 2024
LLMs Can Understand Encrypted Prompt: Towards Privacy-Computing Friendly Transformers
May 28, 2023Prior works have attempted to build private inference frameworks for transformer-based large language models (LLMs) in a server-client setting, where the server holds the model parameters and the client inputs the private data for inference. However, these frameworks impose significant overhead when the private inputs are forward propagated through the original LLMs. In this paper, we show that substituting the computation- and communication-heavy operators in the transformer architecture with privacy-computing friendly approximations can greatly reduce the private inference costs with minor impact on model performance. Compared to the state-of-the-art Iron (NeurIPS 2022), our privacy-computing friendly model inference pipeline achieves a $5\times$ acceleration in computation and an 80\% reduction in communication overhead, while retaining nearly identical accuracy.
Computer Vision and Metrics Learning for Hypothesis Testing: An Application of Q-Q Plot for Normality Test
Jan 23, 2019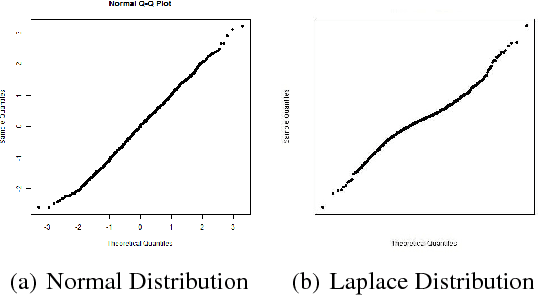



This paper proposes a new procedure to construct test statistics for hypothesis testing by computer vision and metrics learning. The application highlighted in this paper is applying computer vision on Q-Q plot to construct a new test statistic for normality test. Traditionally, there are two families of approaches for verifying the probability distribution of a random variable. Researchers either subjectively assess the Q-Q plot or objectively use a mathematical formula, such as Kolmogorov-Smirnov test, to formally conduct a normality test. Graphical assessment by human beings is not rigorous whereas normality test statistics may not be accurate enough when the uniformly most powerful test does not exist. It may take tens of years for statistician to develop a new and more powerful test statistic. The first step of the proposed method is to apply computer vision techniques, such as pre-trained ResNet, to convert a Q-Q plot into a numerical vector. Next step is to apply metric learning to find an appropriate distance function between a Q-Q plot and the centroid of all Q-Q plots under the null hypothesis, which assumes the target variable is normally distributed. This distance metric is the new test statistic for normality test. Our experimentation results show that the machine-learning-based test statistics can outperform traditional normality tests in all cases, particularly when the sample size is small. This study provides convincing evidence that the proposed method could objectively create a powerful test statistic based on Q-Q plots and this method could be modified to construct many more powerful test statistics for other applications in the future.