 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthCropSeg++: Scaling a Crop Segmentation Foundation Model With Depth-Labeled Data
Jan 18, 2026DepthCropSeg++: a foundation model for crop segmentation, capable of segmenting different crop species under open in-field environment. Crop segmentation is a fundamental task for modern agriculture, which closely relates to many downstream tasks such as plant phenotyping, density estimation, and weed control. In the era of foundation models, a number of generic large language and vision models have been developed. These models have demonstrated remarkable real world generalization due to significant model capacity and largescale datasets. However, current crop segmentation models mostly learn from limited data due to expensive pixel-level labelling cost, often performing well only under specific crop types or controlled environment. In this work, we follow the vein of our previous work DepthCropSeg, an almost unsupervised approach to crop segmentation, to scale up a cross-species and crossscene crop segmentation dataset, with 28,406 images across 30+ species and 15 environmental conditions. We also build upon a state-of-the-art semantic segmentation architecture ViT-Adapter architecture, enhance it with dynamic upsampling for improved detail awareness, and train the model with a two-stage selftraining pipeline. To systematically validate model performance, we conduct comprehensive experiments to justify the effectiveness and generalization capabilities across multiple crop datasets. Results demonstrate that DepthCropSeg++ achieves 93.11% mIoU on a comprehensive testing set, outperforming both supervised baselines and general-purpose vision foundation models like Segmentation Anything Model (SAM) by significant margins (+0.36% and +48.57% respectively). The model particularly excels in challenging scenarios including night-time environment (86.90% mIoU), high-density canopies (90.09% mIoU), and unseen crop varieties (90.09% mIoU), indicating a new state of the art for crop segmentation.
* 13 pages, 15 figures and 7 tables
Investigating Large Language Models for Code Vulnerability Detection: An Experimental Study
Dec 24, 2024



Code vulnerability detection (CVD) is essential for addressing and preventing system security issues, playing a crucial role in ensuring software security. Previous learning-based vulnerability detection methods rely on either fine-tuning medium-size sequence models or training smaller neural networks from scratch. Recent advancements in large pre-trained language models (LLMs) have showcased remarkable capabilities in various code intelligence tasks including code understanding and generation. However, the effectiveness of LLMs in detecting code vulnerabilities is largely under-explored. This work aims to investigate the gap by fine-tuning LLMs for the CVD task, involving four widely-used open-source LLMs. We also implement other five previous graph-based or medium-size sequence models for comparison. Experiments are conducted on five commonly-used CVD datasets, including both the part of short samples and long samples. In addition, we conduct quantitative experiments to investigate the class imbalance issue and the model's performance on samples of different lengths, which are rarely studied in previous works. To better facilitate communities, we open-source all codes and resources of this study in https://github.com/SakiRinn/LLM4CVD and https://huggingface.co/datasets/xuefen/VulResource.
Retinal Vessel Segmentation via Neuron Programming
Nov 17, 2024
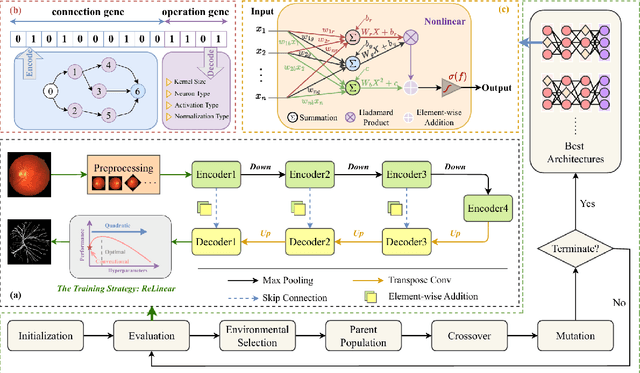
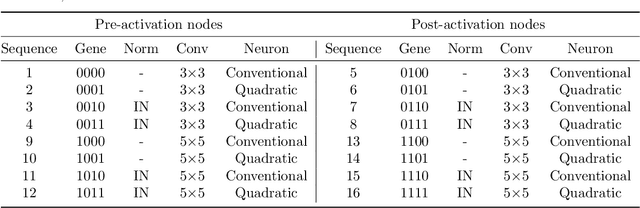
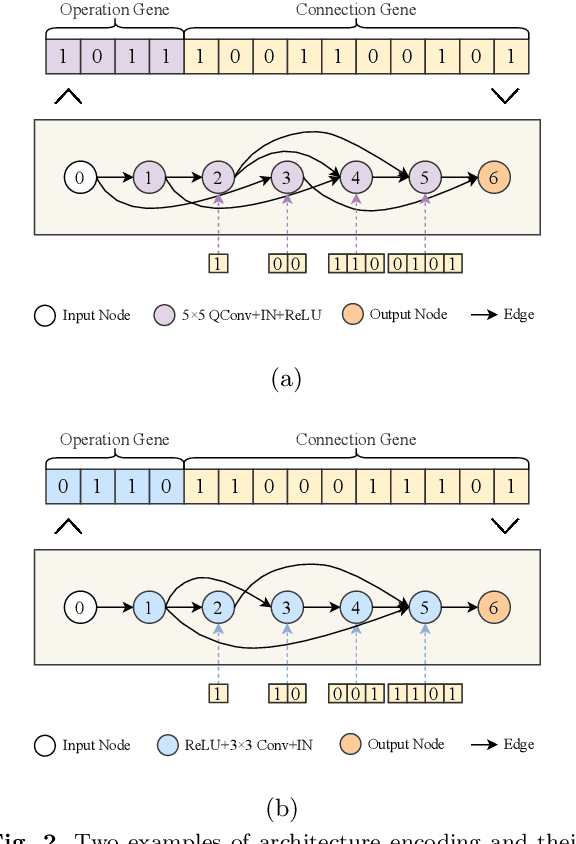
The accurate segmentation of retinal blood vessels plays a crucial role in the early diagnosis and treatment of various ophthalmic diseases. Designing a network model for this task requires meticulous tuning and extensive experimentation to handle the tiny and intertwined morphology of retinal blood vessels. To tackle this challenge, Neural Architecture Search (NAS) methods are developed to fully explore the space of potential network architectures and go after the most powerful one. Inspired by neuronal diversity which is the biological foundation of all kinds of intelligent behaviors in our brain, this paper introduces a novel and foundational approach to neural network design, termed ``neuron programming'', to automatically search neuronal types into a network to enhance a network's representation ability at the neuronal level, which is complementary to architecture-level enhancement done by NAS. Additionally, to mitigate the time and computational intensity of neuron programming, we develop a hypernetwork that leverages the search-derived architectural information to predict optimal neuronal configurations. Comprehensive experiments validate that neuron programming can achieve competitive performance in retinal blood segmentation, demonstrating the strong potential of neuronal diversity in medical image analysis.
A New Cross-Space Total Variation Regularization Model for Color Image Restoration with Quaternion Blur Operator
May 20, 2024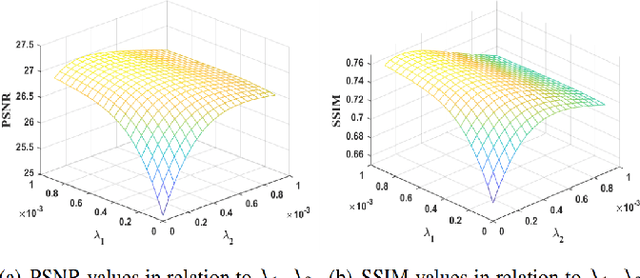

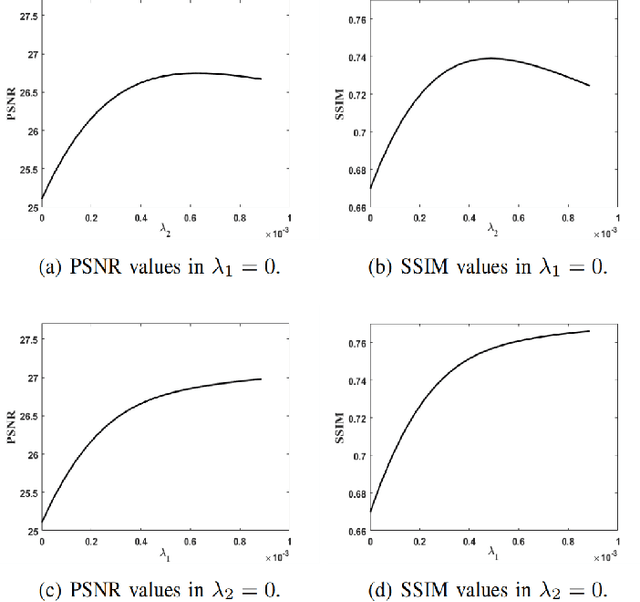
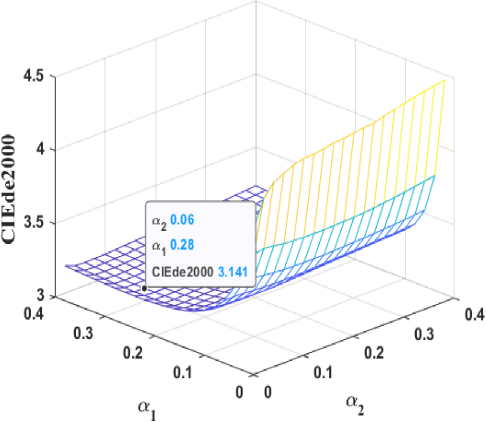
The cross-channel deblurring problem in color image processing is difficult to solve due to the complex coupling and structural blurring of color pixels. Until now, there are few efficient algorithms that can reduce color infection in deblurring process. To solve this challenging problem, we present a novel cross-space total variation (CSTV) regularization model for color image deblurring by introducing a quaternion blur operator and a cross-color space regularization functional. The existence and uniqueness of the solution is proved and a new L-curve method is proposed to find a sweet balance of regularization functionals on different color spaces. The Euler-Lagrange equation is derived to show that CSTV has taken into account the coupling of all color channels and the local smoothing within each color channel. A quaternion operator splitting method is firstly proposed to enhance the ability of color infection reduction of the CSTV regularization model. This strategy also applies to the well-known color deblurring models. Numerical experiments on color image databases illustrate the efficiency and manoeuvrability of the new model and algorithms. The color images restored by them successfully maintain the color and spatial information and are of higher quality in terms of PSNR, SSIM, MSE and CIEde2000 than the restorations of the-state-of-the-art methods.
VDIP-TGV: Blind Image Deconvolution via Variational Deep Image Prior Empowered by Total Generalized Variation
Oct 30, 2023



Recovering clear images from blurry ones with an unknown blur kernel is a challenging problem. Deep image prior (DIP) proposes to use the deep network as a regularizer for a single image rather than as a supervised model, which achieves encouraging results in the nonblind deblurring problem. However, since the relationship between images and the network architectures is unclear, it is hard to find a suitable architecture to provide sufficient constraints on the estimated blur kernels and clean images. Also, DIP uses the sparse maximum a posteriori (MAP), which is insufficient to enforce the selection of the recovery image. Recently, variational deep image prior (VDIP) was proposed to impose constraints on both blur kernels and recovery images and take the standard deviation of the image into account during the optimization process by the variational principle. However, we empirically find that VDIP struggles with processing image details and tends to generate suboptimal results when the blur kernel is large. Therefore, we combine total generalized variational (TGV) regularization with VDIP in this paper to overcome these shortcomings of VDIP. TGV is a flexible regularization that utilizes the characteristics of partial derivatives of varying orders to regularize images at different scales, reducing oil painting artifacts while maintaining sharp edges. The proposed VDIP-TGV effectively recovers image edges and details by supplementing extra gradient information through TGV. Additionally, this model is solved by the alternating direction method of multipliers (ADMM), which effectively combines traditional algorithms and deep learning methods. Experiments show that our proposed VDIP-TGV surpasses various state-of-the-art models quantitatively and qualitatively.
Dipole-Spread Function Engineering for 6D Super-Resolution Microscopy
Oct 09, 2023Fluorescent molecules are versatile nanoscale emitters that enable detailed observations of biophysical processes with nanoscale resolution. Because they are well-approximated as electric dipoles, imaging systems can be designed to visualize their 3D positions and 3D orientations, so-called dipole-spread function (DSF) engineering, for 6D super-resolution single-molecule orientation-localization microscopy (SMOLM). We review fundamental image-formation theory for fluorescent di-poles, as well as how phase and polarization modulation can be used to change the image of a dipole emitter produced by a microscope, called its DSF. We describe several methods for designing these modulations for optimum performance, as well as compare recently developed techniques, including the double-helix, tetrapod, crescent, and DeepSTORM3D learned point-spread functions (PSFs), in addition to the tri-spot, vortex, pixOL, raPol, CHIDO, and MVR DSFs. We also cover common imaging system designs and techniques for implementing engineered DSFs. Finally, we discuss recent biological applications of 6D SMOLM and future challenges for pushing the capabilities and utility of the technology.
NoisywikiHow: A Benchmark for Learning with Real-world Noisy Labels in Natural Language Processing
May 18, 2023
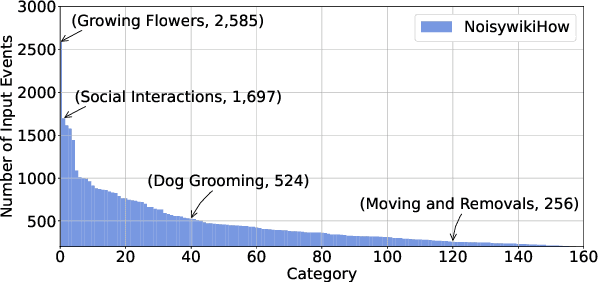
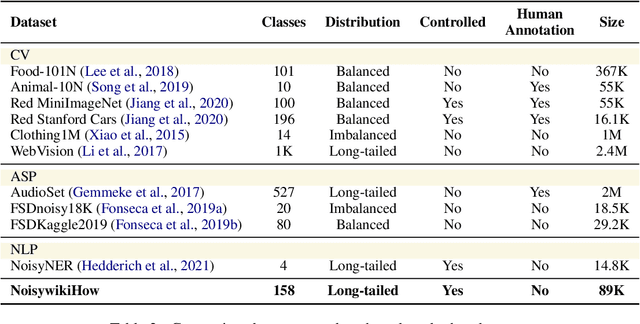
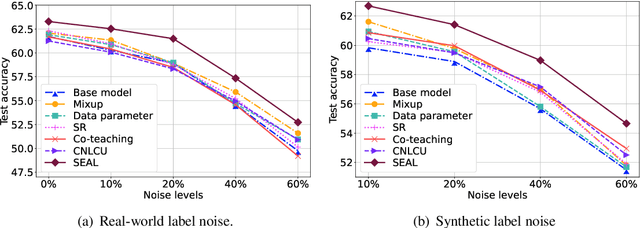
Large-scale datasets in the real world inevitably involve label noise. Deep models can gradually overfit noisy labels and thus degrade model generalization. To mitigate the effects of label noise, learning with noisy labels (LNL) methods are designed to achieve better generalization performance. Due to the lack of suitable datasets, previous studies have frequently employed synthetic label noise to mimic real-world label noise. However, synthetic noise is not instance-dependent, making this approximation not always effective in practice. Recent research has proposed benchmarks for learning with real-world noisy labels. However, the noise sources within may be single or fuzzy, making benchmarks different from data with heterogeneous label noises in the real world. To tackle these issues, we contribute NoisywikiHow, the largest NLP benchmark built with minimal supervision. Specifically, inspired by human cognition, we explicitly construct multiple sources of label noise to imitate human errors throughout the annotation, replicating real-world noise, whose corruption is affected by both ground-truth labels and instances. Moreover, we provide a variety of noise levels to support controlled experiments on noisy data, enabling us to evaluate LNL methods systematically and comprehensively. After that, we conduct extensive multi-dimensional experiments on a broad range of LNL methods, obtaining new and intriguing findings.
CCFL: Computationally Customized Federated Learning
Dec 28, 2022Federated learning (FL) is a method to train model with distributed data from numerous participants such as IoT devices. It inherently assumes a uniform capacity among participants. However, participants have diverse computational resources in practice due to different conditions such as different energy budgets or executing parallel unrelated tasks. It is necessary to reduce the computation overhead for participants with inefficient computational resources, otherwise they would be unable to finish the full training process. To address the computation heterogeneity, in this paper we propose a strategy for estimating local models without computationally intensive iterations. Based on it, we propose Computationally Customized Federated Learning (CCFL), which allows each participant to determine whether to perform conventional local training or model estimation in each round based on its current computational resources. Both theoretical analysis and exhaustive experiments indicate that CCFL has the same convergence rate as FedAvg without resource constraints. Furthermore, CCFL can be viewed of a computation-efficient extension of FedAvg that retains model performance while considerably reducing computation overhead.
Retinex Image Enhancement Based on Sequential Decomposition With a Plug-and-Play Framework
Oct 11, 2022


The Retinex model is one of the most representative and effective methods for low-light image enhancement. However, the Retinex model does not explicitly tackle the noise problem, and shows unsatisfactory enhancing results. In recent years, due to the excellent performance, deep learning models have been widely used in low-light image enhancement. However, these methods have two limitations: i) The desirable performance can only be achieved by deep learning when a large number of labeled data are available. However, it is not easy to curate massive low/normal-light paired data; ii) Deep learning is notoriously a black-box model [1]. It is difficult to explain their inner-working mechanism and understand their behaviors. In this paper, using a sequential Retinex decomposition strategy, we design a plug-and-play framework based on the Retinex theory for simultaneously image enhancement and noise removal. Meanwhile, we develop a convolutional neural network-based (CNN-based) denoiser into our proposed plug-and-play framework to generate a reflectance component. The final enhanced image is produced by integrating the illumination and reflectance with gamma correction. The proposed plug-and-play framework can facilitate both post hoc and ad hoc interpretability. Extensive experiments on different datasets demonstrate that our framework outcompetes the state-of-the-art methods in both image enhancement and denoising.
DiscrimLoss: A Universal Loss for Hard Samples and Incorrect Samples Discrimination
Aug 21, 2022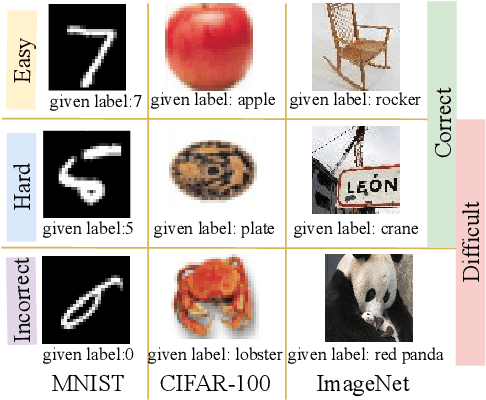
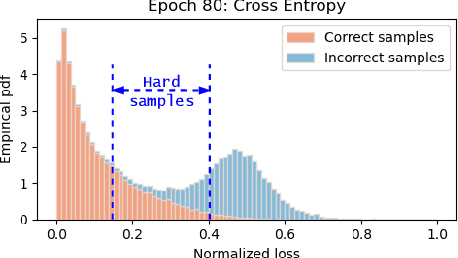
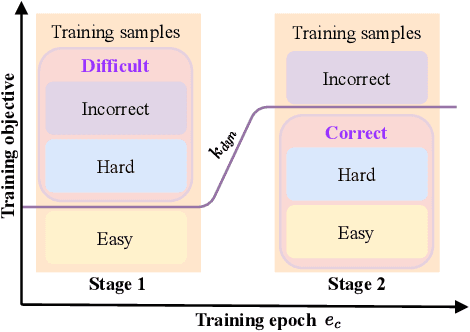
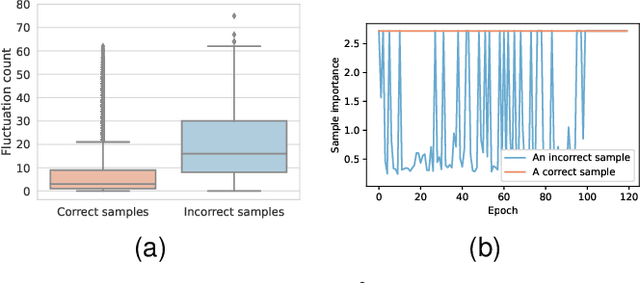
Given data with label noise (i.e., incorrect data), deep neural networks would gradually memorize the label noise and impair model performance. To relieve this issue, curriculum learning is proposed to improve model performance and generalization by ordering training samples in a meaningful (e.g., easy to hard) sequence. Previous work takes incorrect samples as generic hard ones without discriminating between hard samples (i.e., hard samples in correct data) and incorrect samples. Indeed, a model should learn from hard samples to promote generalization rather than overfit to incorrect ones. In this paper, we address this problem by appending a novel loss function DiscrimLoss, on top of the existing task loss. Its main effect is to automatically and stably estimate the importance of easy samples and difficult samples (including hard and incorrect samples) at the early stages of training to improve the model performance. Then, during the following stages, DiscrimLoss is dedicated to discriminating between hard and incorrect samples to improve the model generalization. Such a training strategy can be formulated dynamically in a self-supervised manner, effectively mimicking the main principle of curriculum learning. Experiments on image classification, image regression, text sequence regression, and event relation reasoning demonstrate the versatility and effectiveness of our method, particularly in the presence of diversified noise levels.