 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrimLoss: A Universal Loss for Hard Samples and Incorrect Samples Discrimination
Paper and Code
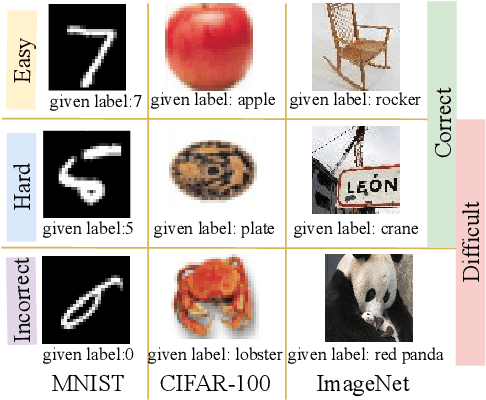
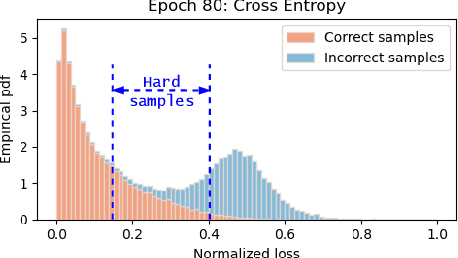
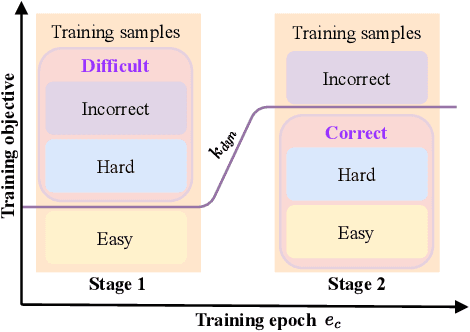
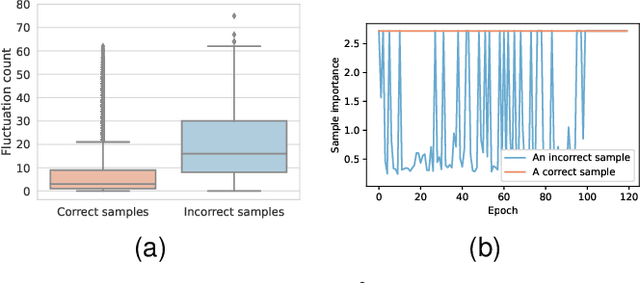
Given data with label noise (i.e., incorrect data), deep neural networks would gradually memorize the label noise and impair model performance. To relieve this issue, curriculum learning is proposed to improve model performance and generalization by ordering training samples in a meaningful (e.g., easy to hard) sequence. Previous work takes incorrect samples as generic hard ones without discriminating between hard samples (i.e., hard samples in correct data) and incorrect samples. Indeed, a model should learn from hard samples to promote generalization rather than overfit to incorrect ones. In this paper, we address this problem by appending a novel loss function DiscrimLoss, on top of the existing task loss. Its main effect is to automatically and stably estimate the importance of easy samples and difficult samples (including hard and incorrect samples) at the early stages of training to improve the model performance. Then, during the following stages, DiscrimLoss is dedicated to discriminating between hard and incorrect samples to improve the model generalization. Such a training strategy can be formulated dynamically in a self-supervised manner, effectively mimicking the main principle of curriculum learning. Experiments on image classification, image regression, text sequence regression, and event relation reasoning demonstrate the versatility and effectiveness of our method, particularly in the presence of diversified noise levels.