 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAESTRO: Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization
Jan 12, 2026Group-Relative Policy Optimization (GRPO) has emerged as an efficient paradigm for aligning Large Language Models (LLMs), yet its efficacy is primarily confined to domains with verifiable ground truths. Extending GRPO to open-domain settings remains a critical challenge, as unconstrained generation entails multi-faceted and often conflicting objectives - such as creativity versus factuality - where rigid, static reward scalarization is inherently suboptimal. To address this, we propose MAESTRO (Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization), which introduces a meta-cognitive orchestration layer that treats reward scalarization as a dynamic latent policy, leveraging the model's terminal hidden states as a semantic bottleneck to perceive task-specific priorities. We formulate this as a contextual bandit problem within a bi-level optimization framework, where a lightweight Conductor network co-evolves with the policy by utilizing group-relative advantages as a meta-reward signal. Across seven benchmarks, MAESTRO consistently outperforms single-reward and static multi-objective baselines, while preserving the efficiency advantages of GRPO, and in some settings even reducing redundant generation.
Consolidation or Adaptation? PRISM: Disentangling SFT and RL Data via Gradient Concentration
Jan 12, 2026While Hybrid Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has become the standard paradigm for training LLM agents, effective mechanisms for data allocation between these stages remain largely underexplored. Current data arbitration strategies often rely on surface-level heuristics that fail to diagnose intrinsic learning needs. Since SFT targets pattern consolidation through imitation while RL drives structural adaptation via exploration, misaligning data with these functional roles causes severe optimization interference. We propose PRISM, a dynamics-aware framework grounded in Schema Theory that arbitrates data based on its degree of cognitive conflict with the model's existing knowledge. By analyzing the spatial geometric structure of gradients, PRISM identifies data triggering high spatial concentration as high-conflict signals that require RL for structural restructuring. In contrast, data yielding diffuse updates is routed to SFT for efficient consolidation. Extensive experiments on WebShop and ALFWorld demonstrate that PRISM achieves a Pareto improvement, outperforming state-of-the-art hybrid methods while reducing computational costs by up to 3.22$\times$. Our findings suggest that disentangling data based on internal optimization regimes is crucial for scalable and robust agent alignment.
Com$^2$: A Causal-Guided Benchmark for Exploring Complex Commonsense Reasoning in Large Language Models
Jun 08, 2025Large language models (LLMs) have mastered abundant simple and explicit commonsense knowledge through pre-training, enabling them to achieve human-like performance in simple commonsense reasoning. Nevertheless, LLMs struggle to reason with complex and implicit commonsense knowledge that is derived from simple ones (such as understanding the long-term effects of certain events), an aspect humans tend to focus on more. Existing works focus on complex tasks like math and code, while complex commonsense reasoning remains underexplored due to its uncertainty and lack of structure. To fill this gap and align with real-world concerns, we propose a benchmark Com$^2$ focusing on complex commonsense reasoning. We first incorporate causal event graphs to serve as structured complex commonsense. Then we adopt causal theory~(e.g., intervention) to modify the causal event graphs and obtain different scenarios that meet human concerns. Finally, an LLM is employed to synthesize examples with slow thinking, which is guided by the logical relationships in the modified causal graphs. Furthermore, we use detective stories to construct a more challenging subset. Experiments show that LLMs struggle in reasoning depth and breadth, while post-training and slow thinking can alleviate this. The code and data are available at https://github.com/Waste-Wood/Com2.
CrossICL: Cross-Task In-Context Learning via Unsupervised Demonstration Transfer
May 30, 2025In-Context Learning (ICL) enhances the performance of large language models (LLMs) with demonstrations. However, obtaining these demonstrations primarily relies on manual effort. In most real-world scenarios, users are often unwilling or unable to provide such demonstrations. Inspired by the human analogy, we explore a new ICL paradigm CrossICL to study how to utilize existing source task demonstrations in the ICL for target tasks, thereby obtaining reliable guidance without any additional manual effort. To explore this, we first design a two-stage alignment strategy to mitigate the interference caused by gaps across tasks, as the foundation for our experimental exploration. Based on it, we conduct comprehensive exploration of CrossICL, with 875 NLP tasks from the Super-NI benchmark and six types of LLMs, including GPT-4o. Experimental results demonstrate the effectiveness of CrossICL and provide valuable insights on questions like the criteria for selecting cross-task demonstrations, as well as the types of task-gap-induced interference in CrossICL.
ExpeTrans: LLMs Are Experiential Transfer Learners
May 29, 2025Recent studies provide large language models (LLMs) with textual task-solving experiences via prompts to improve their performance. However, previous methods rely on substantial human labor or time to gather such experiences for each task, which is impractical given the growing variety of task types in user queries to LLMs. To address this issue, we design an autonomous experience transfer framework to explore whether LLMs can mimic human cognitive intelligence to autonomously transfer experience from existing source tasks to newly encountered target tasks. This not only allows the acquisition of experience without extensive costs of previous methods, but also offers a novel path for the generalization of LLMs. Experimental results on 13 datasets demonstrate that our framework effectively improves the performance of LLMs. Furthermore, we provide a detailed analysis of each module in the framework.
Enhancing Complex Causality Extraction via Improved Subtask Interaction and Knowledge Fusion
Aug 06, 2024

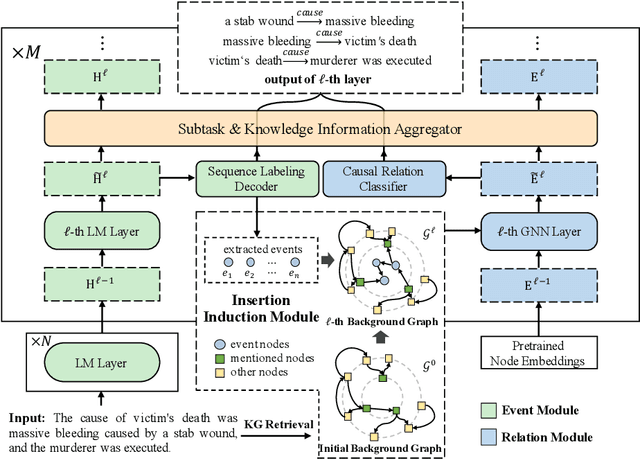
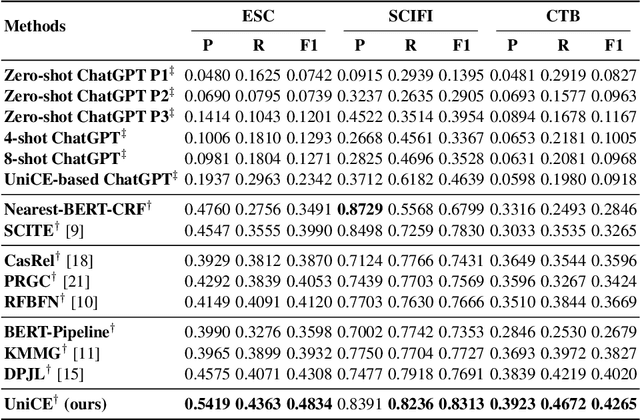
Event Causality Extraction (ECE) aims at extracting causal event pairs from texts. Despite ChatGPT's recent success, fine-tuning small models remains the best approach for the ECE task. However, existing fine-tuning based ECE methods cannot address all three key challenges in ECE simultaneously: 1) Complex Causality Extraction, where multiple causal-effect pairs occur within a single sentence; 2) Subtask~ Interaction, which involves modeling the mutual dependence between the two subtasks of ECE, i.e., extracting events and identifying the causal relationship between extracted events; and 3) Knowledge Fusion, which requires effectively fusing the knowledge in two modalities, i.e., the expressive pretrained language models and the structured knowledge graphs. In this paper, we propose a unified ECE framework (UniCE to address all three issues in ECE simultaneously. Specifically, we design a subtask interaction mechanism to enable mutual interaction between the two ECE subtasks. Besides, we design a knowledge fusion mechanism to fuse knowledge in the two modalities. Furthermore, we employ separate decoders for each subtask to facilitate complex causality extraction. Experiments on three benchmark datasets demonstrate that our method achieves state-of-the-art performance and outperforms ChatGPT with a margin of at least 30% F1-score. More importantly, our model can also be used to effectively improve the ECE performance of ChatGPT via in-context learning.
Self-Evolving GPT: A Lifelong Autonomous Experiential Learner
Jul 12, 2024
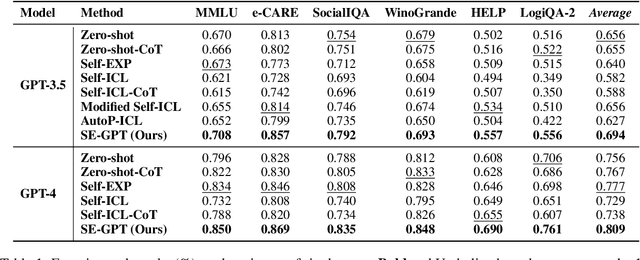
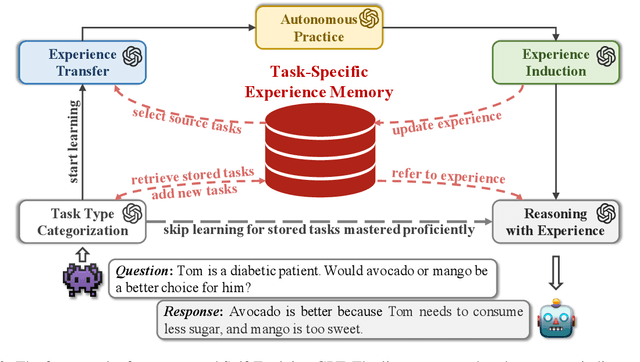
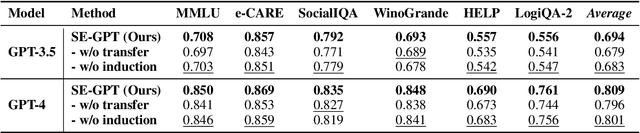
To improve the performance of large language models (LLMs), researchers have explored providing LLMs with textual task-solving experience via prompts. However, they rely on manual efforts to acquire and apply such experience for each task, which is not feasible for the growing demand for LLMs and the variety of user questions. To address this issue, we design a lifelong autonomous experiential learning framework based on LLMs to explore whether LLMs can imitate human ability for learning and utilizing experience. It autonomously learns and accumulates experience through experience transfer and induction, categorizing the types of input questions to select which accumulated experience to employ for them. Experimental results on six widely used NLP datasets show that our framework performs reliably in each intermediate step and effectively improves the performance of GPT-3.5 and GPT-4. This validates the feasibility of using LLMs to mimic human experiential learning and application capabilities. Additionally, we provide a detailed analysis of the behavior of our framework at each step.
Towards Generalizable and Faithful Logic Reasoning over Natural Language via Resolution Refutation
Apr 03, 2024



Large language models (LLMs) have achieved significant performance in various natural language reasoning tasks. However, they still struggle with performing first-order logic reasoning over formal logical theories expressed in natural language. This is because the previous LLMs-based reasoning systems have the theoretical incompleteness issue. As a result, it can only address a limited set of simple reasoning problems, which significantly decreases their generalization ability. To address this issue, we propose a novel framework, named Generalizable and Faithful Reasoner (GFaiR), which introduces the paradigm of resolution refutation. Resolution refutation has the capability to solve all first-order logic reasoning problems by extending reasoning rules and employing the principle of proof by contradiction, so our system's completeness can be improved by introducing resolution refutation. Experimental results demonstrate that our system outperforms previous works by achieving state-of-the-art performances in complex scenarios while maintaining performances in simple scenarios. Besides, we observe that GFaiR is faithful to its reasoning process.
Is ChatGPT a Good Causal Reasoner? A Comprehensive Evaluation
May 18, 2023Causal reasoning ability is crucial for numerous NLP applications. Despite the impressive emerging ability of ChatGPT in various NLP tasks, it is unclear how well ChatGPT performs in causal reasoning. In this paper, we conduct the first comprehensive evaluation of the ChatGPT's causal reasoning capabilities. Experiments show that ChatGPT is not a good causal reasoner, but a good causal interpreter. Besides, ChatGPT has a serious hallucination on causal reasoning, possibly due to the reporting biases between causal and non-causal relationships in natural language, as well as ChatGPT's upgrading processes, such as RLHF. The In-Context Learning (ICL) and Chain-of-Though (COT) techniques can further exacerbate such causal hallucination. Additionally, the causal reasoning ability of ChatGPT is sensitive to the words used to express the causal concept in prompts, and close-ended prompts perform better than open-ended prompts. For events in sentences, ChatGPT excels at capturing explicit causality rather than implicit causality, and performs better in sentences with lower event density and smaller lexical distance between events.
DiscrimLoss: A Universal Loss for Hard Samples and Incorrect Samples Discrimination
Aug 21, 2022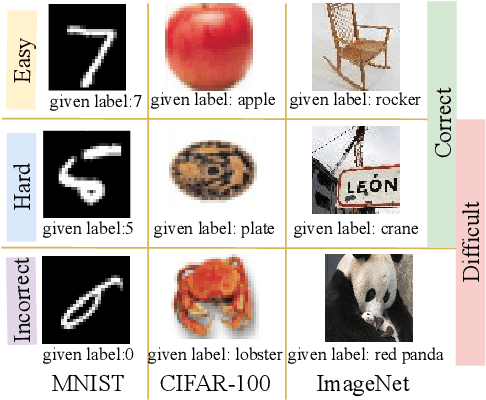
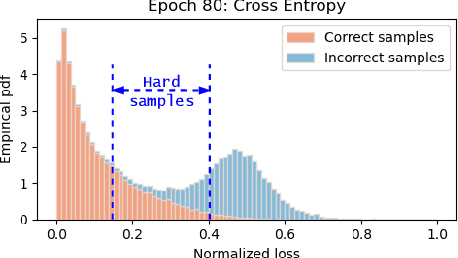
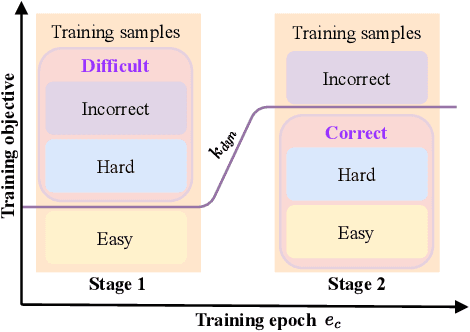
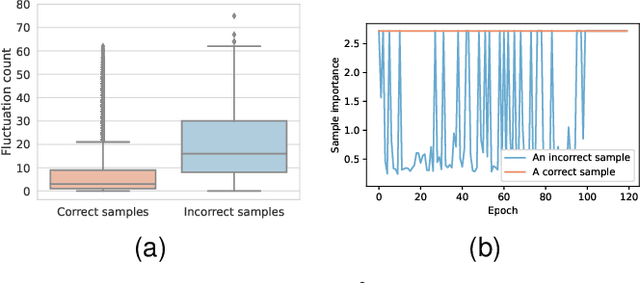
Given data with label noise (i.e., incorrect data), deep neural networks would gradually memorize the label noise and impair model performance. To relieve this issue, curriculum learning is proposed to improve model performance and generalization by ordering training samples in a meaningful (e.g., easy to hard) sequence. Previous work takes incorrect samples as generic hard ones without discriminating between hard samples (i.e., hard samples in correct data) and incorrect samples. Indeed, a model should learn from hard samples to promote generalization rather than overfit to incorrect ones. In this paper, we address this problem by appending a novel loss function DiscrimLoss, on top of the existing task loss. Its main effect is to automatically and stably estimate the importance of easy samples and difficult samples (including hard and incorrect samples) at the early stages of training to improve the model performance. Then, during the following stages, DiscrimLoss is dedicated to discriminating between hard and incorrect samples to improve the model generalization. Such a training strategy can be formulated dynamically in a self-supervised manner, effectively mimicking the main principle of curriculum learning. Experiments on image classification, image regression, text sequence regression, and event relation reasoning demonstrate the versatility and effectiveness of our method, particularly in the presence of diversified noise levels.