 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable and Faithful Logic Reasoning over Natural Language via Resolution Refutation
Apr 03, 2024



Large language models (LLMs) have achieved significant performance in various natural language reasoning tasks. However, they still struggle with performing first-order logic reasoning over formal logical theories expressed in natural language. This is because the previous LLMs-based reasoning systems have the theoretical incompleteness issue. As a result, it can only address a limited set of simple reasoning problems, which significantly decreases their generalization ability. To address this issue, we propose a novel framework, named Generalizable and Faithful Reasoner (GFaiR), which introduces the paradigm of resolution refutation. Resolution refutation has the capability to solve all first-order logic reasoning problems by extending reasoning rules and employing the principle of proof by contradiction, so our system's completeness can be improved by introducing resolution refutation. Experimental results demonstrate that our system outperforms previous works by achieving state-of-the-art performances in complex scenarios while maintaining performances in simple scenarios. Besides, we observe that GFaiR is faithful to its reasoning process.
Text Difficulty Study: Do machines behave the same as humans regarding text difficulty?
Aug 14, 2022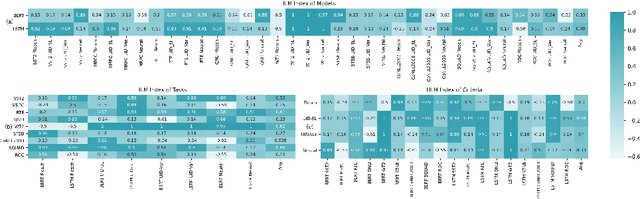
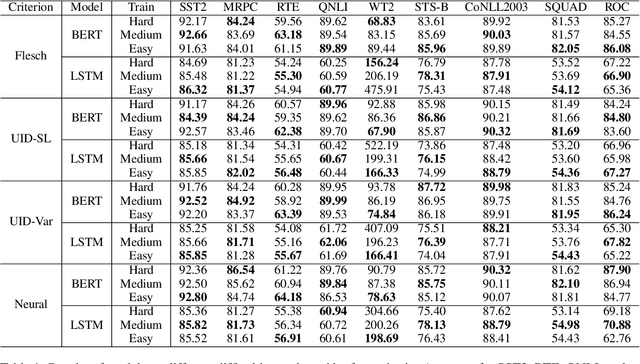
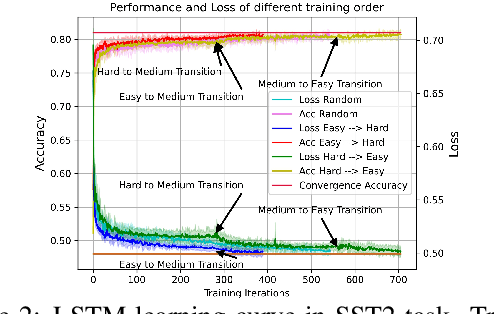
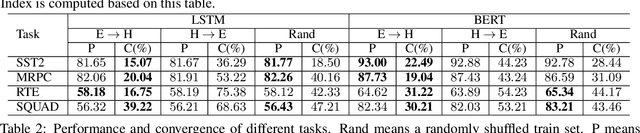
Given a task, human learns from easy to hard, whereas the model learns randomly. Undeniably, difficulty insensitive learning leads to great success in NLP, but little attention has been paid to the effect of text difficulty in NLP. In this research, we propose the Human Learning Matching Index (HLM Index) to investigate the effect of text difficulty. Experiment results show: (1) LSTM has more human-like learning behavior than BERT. (2) UID-SuperLinear gives the best evaluation of text difficulty among four text difficulty criteria. (3) Among nine tasks, some tasks' performance is related to text difficulty, whereas some are not. (4) Model trained on easy data performs best in easy and medium data, whereas trains on a hard level only perform well on hard data. (5) Training the model from easy to hard leads to fast convergence.
Domain-Specific Sentiment Word Extraction by Seed Expansion and Pattern Generation
Sep 26, 2013



This paper focuses on the automatic extraction of domain-specific sentiment word (DSSW), which is a fundamental subtask of sentiment analysis. Most previous work utilizes manual patterns for this task. However, the performance of those methods highly relies on the labelled patterns or selected seeds. In order to overcome the above problem, this paper presents an automatic framework to detect large-scale domain-specific patterns for DSSW extraction. To this end, sentiment seeds are extracted from massive dataset of user comments. Subsequently, these sentiment seeds are expanded by synonyms using a bootstrapping mechanism. Simultaneously, a synonymy graph is built and the graph propagation algorithm is applied on the built synonymy graph. Afterwards, syntactic and sequential relations between target words and high-ranked sentiment words are extracted automatically to construct large-scale patterns, which are further used to extracte DSSWs. The experimental results in three domains reveal the effectiveness of our method.