 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Difficulty Study: Do machines behave the same as humans regarding text difficulty?
Paper and Code
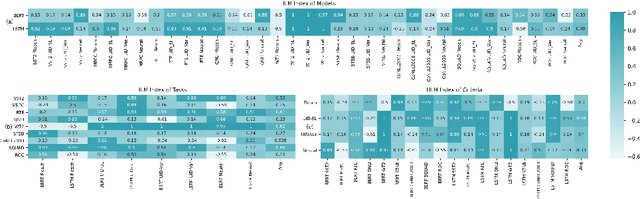
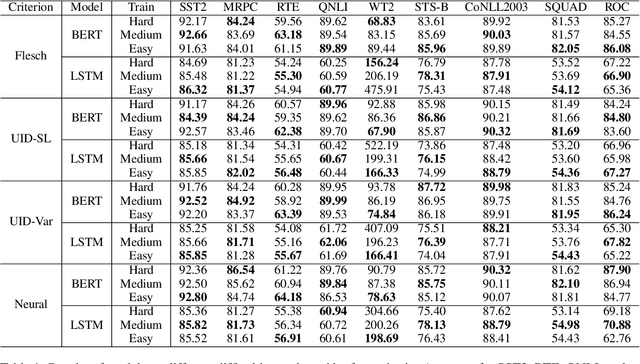
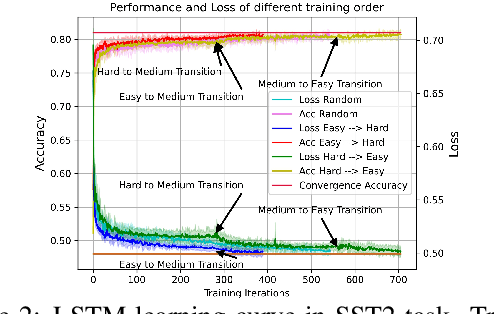
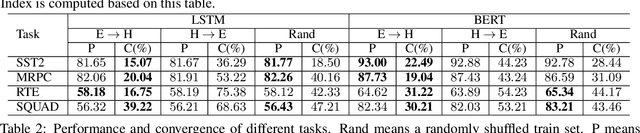
Given a task, human learns from easy to hard, whereas the model learns randomly. Undeniably, difficulty insensitive learning leads to great success in NLP, but little attention has been paid to the effect of text difficulty in NLP. In this research, we propose the Human Learning Matching Index (HLM Index) to investigate the effect of text difficulty. Experiment results show: (1) LSTM has more human-like learning behavior than BERT. (2) UID-SuperLinear gives the best evaluation of text difficulty among four text difficulty criteria. (3) Among nine tasks, some tasks' performance is related to text difficulty, whereas some are not. (4) Model trained on easy data performs best in easy and medium data, whereas trains on a hard level only perform well on hard data. (5) Training the model from easy to hard leads to fast convergence.