 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsolidation or Adaptation? PRISM: Disentangling SFT and RL Data via Gradient Concentration
Jan 12, 2026While Hybrid Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has become the standard paradigm for training LLM agents, effective mechanisms for data allocation between these stages remain largely underexplored. Current data arbitration strategies often rely on surface-level heuristics that fail to diagnose intrinsic learning needs. Since SFT targets pattern consolidation through imitation while RL drives structural adaptation via exploration, misaligning data with these functional roles causes severe optimization interference. We propose PRISM, a dynamics-aware framework grounded in Schema Theory that arbitrates data based on its degree of cognitive conflict with the model's existing knowledge. By analyzing the spatial geometric structure of gradients, PRISM identifies data triggering high spatial concentration as high-conflict signals that require RL for structural restructuring. In contrast, data yielding diffuse updates is routed to SFT for efficient consolidation. Extensive experiments on WebShop and ALFWorld demonstrate that PRISM achieves a Pareto improvement, outperforming state-of-the-art hybrid methods while reducing computational costs by up to 3.22$\times$. Our findings suggest that disentangling data based on internal optimization regimes is crucial for scalable and robust agent alignment.
MAESTRO: Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization
Jan 12, 2026Group-Relative Policy Optimization (GRPO) has emerged as an efficient paradigm for aligning Large Language Models (LLMs), yet its efficacy is primarily confined to domains with verifiable ground truths. Extending GRPO to open-domain settings remains a critical challenge, as unconstrained generation entails multi-faceted and often conflicting objectives - such as creativity versus factuality - where rigid, static reward scalarization is inherently suboptimal. To address this, we propose MAESTRO (Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization), which introduces a meta-cognitive orchestration layer that treats reward scalarization as a dynamic latent policy, leveraging the model's terminal hidden states as a semantic bottleneck to perceive task-specific priorities. We formulate this as a contextual bandit problem within a bi-level optimization framework, where a lightweight Conductor network co-evolves with the policy by utilizing group-relative advantages as a meta-reward signal. Across seven benchmarks, MAESTRO consistently outperforms single-reward and static multi-objective baselines, while preserving the efficiency advantages of GRPO, and in some settings even reducing redundant generation.
Self-Evolving GPT: A Lifelong Autonomous Experiential Learner
Jul 12, 2024
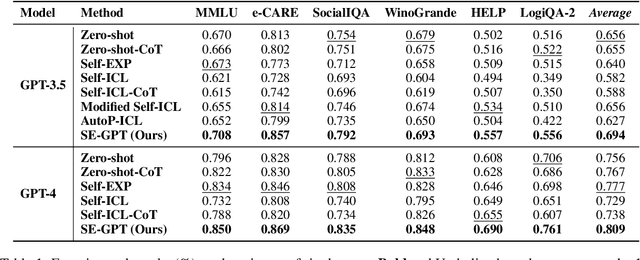
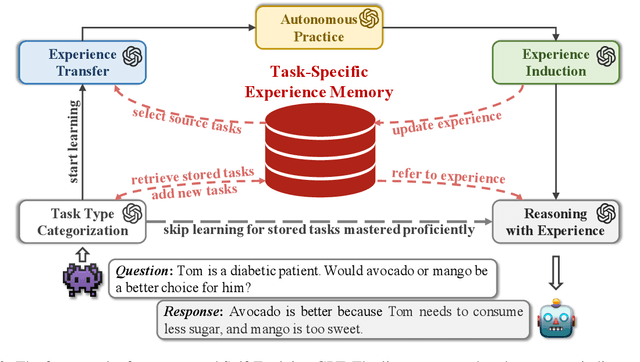
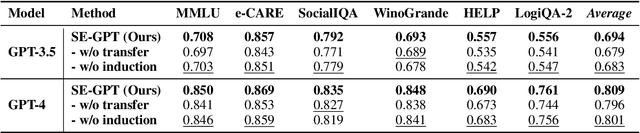
To improve the performance of large language models (LLMs), researchers have explored providing LLMs with textual task-solving experience via prompts. However, they rely on manual efforts to acquire and apply such experience for each task, which is not feasible for the growing demand for LLMs and the variety of user questions. To address this issue, we design a lifelong autonomous experiential learning framework based on LLMs to explore whether LLMs can imitate human ability for learning and utilizing experience. It autonomously learns and accumulates experience through experience transfer and induction, categorizing the types of input questions to select which accumulated experience to employ for them. Experimental results on six widely used NLP datasets show that our framework performs reliably in each intermediate step and effectively improves the performance of GPT-3.5 and GPT-4. This validates the feasibility of using LLMs to mimic human experiential learning and application capabilities. Additionally, we provide a detailed analysis of the behavior of our framework at each step.