 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsRoute:Consistency-Aware Adaptive Query Routing for Cloud-Edge-Device Large Language Models
Mar 22, 2026Large language models (LLMs) deliver impressive capabilities but incur substantial inference latency and cost, which hinders their deployment in latency-sensitive and resource-constrained scenarios. Cloud-edge-device collaborative inference has emerged as a promising paradigm by dynamically routing queries to models of different capacities across tiers. In this paper, we propose ConsRoute, a lightweight, semantic-aware, and adaptive routing framework that significantly improves inference efficiency while minimizing impact on response quality. Unlike prior routing methods that rely on predicting coarse-grained output quality gaps, ConsRoute leverages a reranker to directly assess the semantic consistency between responses generated by models at different tiers, yielding fine-grained soft supervision signals for routing. To minimize device-side overhead, ConsRoute reuses hidden states from the LLM prefilling stage as compact query representations, avoiding additional encoders or inference passes. Furthermore, these representations are clustered, and Bayesian optimization is employed to learn cluster-specific routing thresholds that dynamically balance quality, latency, and cost under heterogeneous query distributions. Extensive experiments demonstrate that ConsRoute achieves near-cloud performance (>=95%) while reducing end-to-end latency and inference cost by nearly 40%, consistently outperforming existing routing baselines in both response quality and system efficiency.
CCFL: Computationally Customized Federated Learning
Dec 28, 2022Federated learning (FL) is a method to train model with distributed data from numerous participants such as IoT devices. It inherently assumes a uniform capacity among participants. However, participants have diverse computational resources in practice due to different conditions such as different energy budgets or executing parallel unrelated tasks. It is necessary to reduce the computation overhead for participants with inefficient computational resources, otherwise they would be unable to finish the full training process. To address the computation heterogeneity, in this paper we propose a strategy for estimating local models without computationally intensive iterations. Based on it, we propose Computationally Customized Federated Learning (CCFL), which allows each participant to determine whether to perform conventional local training or model estimation in each round based on its current computational resources. Both theoretical analysis and exhaustive experiments indicate that CCFL has the same convergence rate as FedAvg without resource constraints. Furthermore, CCFL can be viewed of a computation-efficient extension of FedAvg that retains model performance while considerably reducing computation overhead.
FedCos: A Scene-adaptive Federated Optimization Enhancement for Performance Improvement
Apr 07, 2022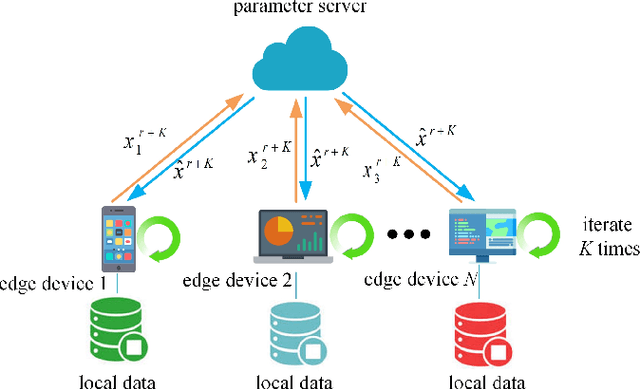
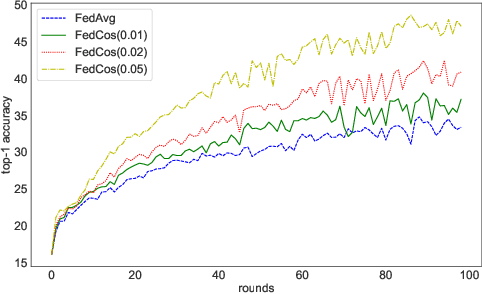
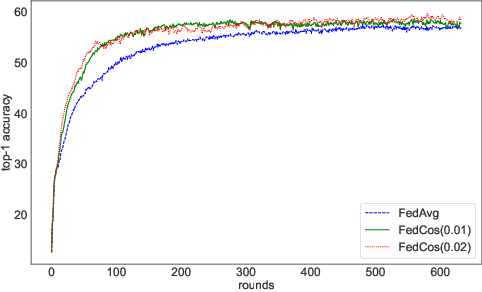
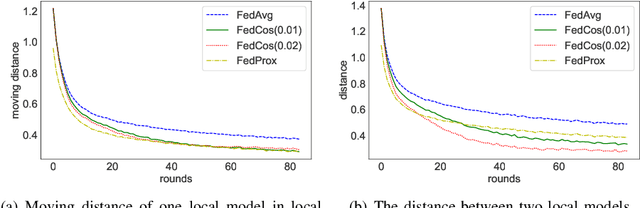
As an emerging technology, federated learning (FL) involves training machine learning models over distributed edge devices, which attracts sustained attention and has been extensively studied. However, the heterogeneity of client data severely degrades the performance of FL compared with that in centralized training. It causes the locally trained models of clients to move in different directions. On the one hand, it slows down or even stalls the global updates, leading to inefficient communication. On the other hand, it enlarges the distances between local models, resulting in an aggregated global model with poor performance. Fortunately, these shortcomings can be mitigated by reducing the angle between the directions that local models move in. Based on this fact, we propose FedCos, which reduces the directional inconsistency of local models by introducing a cosine-similarity penalty. It promotes the local model iterations towards an auxiliary global direction. Moreover, our approach is auto-adapt to various non-IID settings without an elaborate selection of hyperparameters. The experimental results show that FedCos outperforms the well-known baselines and can enhance them under a variety of FL scenes, including varying degrees of data heterogeneity, different number of participants, and cross-silo and cross-device settings. Besides, FedCos improves communication efficiency by 2 to 5 times. With the help of FedCos, multiple FL methods require significantly fewer communication rounds than before to obtain a model with comparable performance.