 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Basics: Let Conversational Agents Remember with Just Retrieval and Generation
Apr 13, 2026Existing conversational memory systems rely on complex hierarchical summarization or reinforcement learning to manage long-term dialogue history, yet remain vulnerable to context dilution as conversations grow. In this work, we offer a different perspective: the primary bottleneck may lie not in memory architecture, but in the \textit{Signal Sparsity Effect} within the latent knowledge manifold. Through controlled experiments, we identify two key phenomena: \textit{Decisive Evidence Sparsity}, where relevant signals become increasingly isolated with longer sessions, leading to sharp degradation in aggregation-based methods; and \textit{Dual-Level Redundancy}, where both inter-session interference and intra-session conversational filler introduce large amounts of non-informative content, hindering effective generation. Motivated by these insights, we propose \method, a minimalist framework that brings conversational memory back to basics, relying solely on retrieval and generation via Turn Isolation Retrieval (TIR) and Query-Driven Pruning (QDP). TIR replaces global aggregation with a max-activation strategy to capture turn-level signals, while QDP removes redundant sessions and conversational filler to construct a compact, high-density evidence set. Extensive experiments on multiple benchmarks demonstrate that \method achieves robust performance across diverse settings, consistently outperforming strong baselines while maintaining high efficiency in tokens and latency, establishing a new minimalist baseline for conversational memory.
Discrete Prototypical Memories for Federated Time Series Foundation Models
Apr 06, 2026Leveraging Large Language Models (LLMs) as federated learning (FL)-based time series foundation models offers a promising way to transfer the generalization capabilities of LLMs to time series data while preserving access to private data. However, the semantic misalignment between time-series data and the text-centric latent space of existing LLMs often leads to degraded performance. Meanwhile, the parameter-sharing mechanism in existing FL methods model heterogeneous cross-domain time-series data into a unified continuous latent space, which contradicts the fact that time-series semantics frequently manifest as discrete and recurring regimes. To address these limitations, we propose \textsc{FeDPM}, a federated framework for time-series foundation models based on discrete prototypical memories. Specifically, we learn local prototypical memory priors for intra-domain time-series data. We then align cross-domain memories to promote a unified discrete latent space and introduce a domain-specific memory update mechanism to balance shared and personalized prototypical knowledge. Extensive experiments demonstrate the efficiency and effectiveness of \textsc{FeDPM}. The code is publicly available at https://anonymous.4open.science/r/FedUnit-64D1.
TS-Memory: Plug-and-Play Memory for Time Series Foundation Models
Feb 12, 2026Time Series Foundation Models (TSFMs) achieve strong zero-shot forecasting through large-scale pre-training, but adapting them to downstream domains under distribution shift remains challenging. Existing solutions face a trade-off: Parametric Adaptation can cause catastrophic forgetting and requires costly multi-domain maintenance, while Non-Parametric Retrieval improves forecasts but incurs high inference latency due to datastore search. We propose Parametric Memory Distillation and implement it as TS-Memory, a lightweight memory adapter that augments frozen TSFMs. TS-Memory is trained in two stages. First, we construct an offline, leakage-safe kNN teacher that synthesizes confidence-aware quantile targets from retrieved futures. Second, we distill this retrieval-induced distributional correction into a lightweight memory adapter via confidence-gated supervision. During inference, TS-Memory fuses memory and backbone predictions with constant-time overhead, enabling retrieval-free deployment. Experiments across diverse TSFMs and benchmarks demonstrate consistent improvements in both point and probabilistic forecasting over representative adaptation methods, with efficiency comparable to the frozen backbone.
Rationale-Grounded In-Context Learning for Time Series Reasoning with Multimodal Large Language Models
Jan 06, 2026The underperformance of existing multimodal large language models for time series reasoning lies in the absence of rationale priors that connect temporal observations to their downstream outcomes, which leads models to rely on superficial pattern matching rather than principled reasoning. We therefore propose the rationale-grounded in-context learning for time series reasoning, where rationales work as guiding reasoning units rather than post-hoc explanations, and develop the RationaleTS method. Specifically, we firstly induce label-conditioned rationales, composed of reasoning paths from observable evidence to the potential outcomes. Then, we design the hybrid retrieval by balancing temporal patterns and semantic contexts to retrieve correlated rationale priors for the final in-context inference on new samples. We conduct extensive experiments to demonstrate the effectiveness and efficiency of our proposed RationaleTS on three-domain time series reasoning tasks. We will release our code for reproduction.
AnyDepth: Depth Estimation Made Easy
Jan 06, 2026Monocular depth estimation aims to recover the depth information of 3D scenes from 2D images. Recent work has made significant progress, but its reliance on large-scale datasets and complex decoders has limited its efficiency and generalization ability. In this paper, we propose a lightweight and data-centric framework for zero-shot monocular depth estimation. We first adopt DINOv3 as the visual encoder to obtain high-quality dense features. Secondly, to address the inherent drawbacks of the complex structure of the DPT, we design the Simple Depth Transformer (SDT), a compact transformer-based decoder. Compared to the DPT, it uses a single-path feature fusion and upsampling process to reduce the computational overhead of cross-scale feature fusion, achieving higher accuracy while reducing the number of parameters by approximately 85%-89%. Furthermore, we propose a quality-based filtering strategy to filter out harmful samples, thereby reducing dataset size while improving overall training quality. Extensive experiments on five benchmarks demonstrate that our framework surpasses the DPT in accuracy. This work highlights the importance of balancing model design and data quality for achieving efficient and generalizable zero-shot depth estimation. Code: https://github.com/AIGeeksGroup/AnyDepth. Website: https://aigeeksgroup.github.io/AnyDepth.
Augur: Modeling Covariate Causal Associations in Time Series via Large Language Models
Oct 09, 2025Large language models (LLM) have emerged as a promising avenue for time series forecasting, offering the potential to integrate multimodal data. However, existing LLM-based approaches face notable limitations-such as marginalized role in model architectures, reliance on coarse statistical text prompts, and lack of interpretability. In this work, we introduce Augur, a fully LLM driven time series forecasting framework that exploits LLM causal reasoning to discover and use directed causal associations among covariates. Augur uses a two stage teacher student architecture where a powerful teacher LLM infers a directed causal graph from time series using heuristic search together with pairwise causality testing. A lightweight student agent then refines the graph and fine tune on high confidence causal associations that are encoded as rich textual prompts to perform forecasting. This design improves predictive accuracy while yielding transparent, traceable reasoning about variable interactions. Extensive experiments on real-world datasets with 25 baselines demonstrate that Augur achieves competitive performance and robust zero-shot generalization.
GDformer: Going Beyond Subsequence Isolation for Multivariate Time Series Anomaly Detection
Jan 30, 2025



Unsupervised anomaly detection of multivariate time series is a challenging task, given the requirements of deriving a compact detection criterion without accessing the anomaly points. The existing methods are mainly based on reconstruction error or association divergence, which are both confined to isolated subsequences with limited horizons, hardly promising unified series-level criterion. In this paper, we propose the Global Dictionary-enhanced Transformer (GDformer) with a renovated dictionary-based cross attention mechanism to cultivate the global representations shared by all normal points in the entire series. Accordingly, the cross-attention maps reflect the correlation weights between the point and global representations, which naturally leads to the representation-wise similarity-based detection criterion. To foster more compact detection boundary, prototypes are introduced to capture the distribution of normal point-global correlation weights. GDformer consistently achieves state-of-the-art unsupervised anomaly detection performance on five real-world benchmark datasets. Further experiments validate the global dictionary has great transferability among various datasets. The code is available at https://github.com/yuppielqx/GDformer.
REFOL: Resource-Efficient Federated Online Learning for Traffic Flow Forecasting
Nov 21, 2024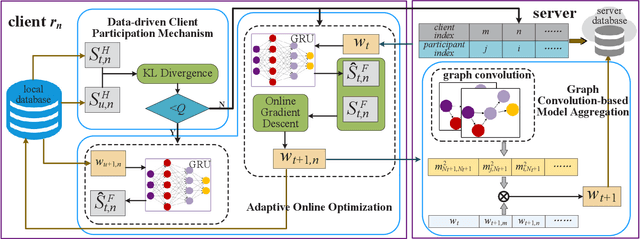
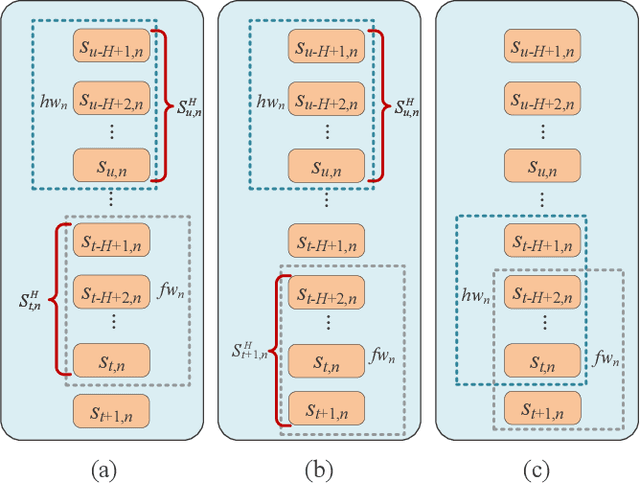
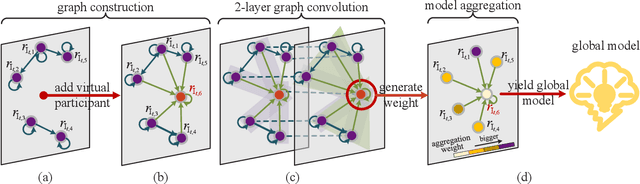
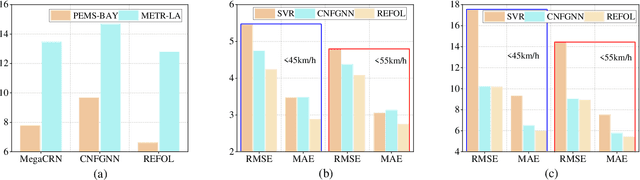
Multiple federated learning (FL) methods are proposed for traffic flow forecasting (TFF) to avoid heavy-transmission and privacy-leaking concerns resulting from the disclosure of raw data in centralized methods. However, these FL methods adopt offline learning which may yield subpar performance, when concept drift occurs, i.e., distributions of historical and future data vary. Online learning can detect concept drift during model training, thus more applicable to TFF. Nevertheless, the existing federated online learning method for TFF fails to efficiently solve the concept drift problem and causes tremendous computing and communication overhead. Therefore, we propose a novel method named Resource-Efficient Federated Online Learning (REFOL) for TFF, which guarantees prediction performance in a communication-lightweight and computation-efficient way. Specifically, we design a data-driven client participation mechanism to detect the occurrence of concept drift and determine clients' participation necessity. Subsequently, we propose an adaptive online optimization strategy, which guarantees prediction performance and meanwhile avoids meaningless model updates. Then, a graph convolution-based model aggregation mechanism is designed, aiming to assess participants' contribution based on spatial correlation without importing extra communication and computing consumption on clients. Finally, we conduct extensive experiments on real-world datasets to demonstrate the superiority of REFOL in terms of prediction improvement and resource economization.
Time-FFM: Towards LM-Empowered Federated Foundation Model for Time Series Forecasting
May 23, 2024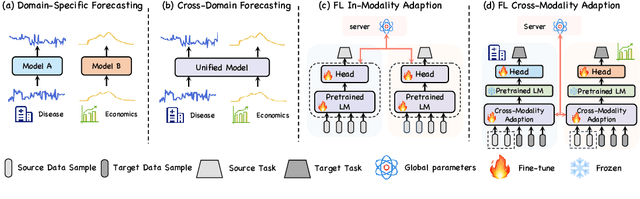
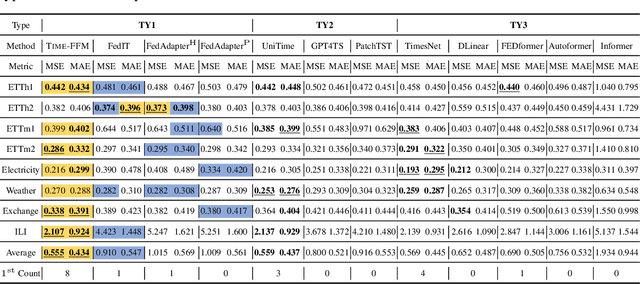
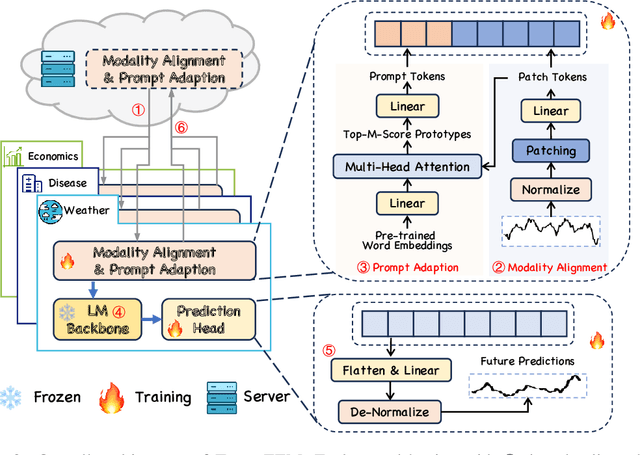
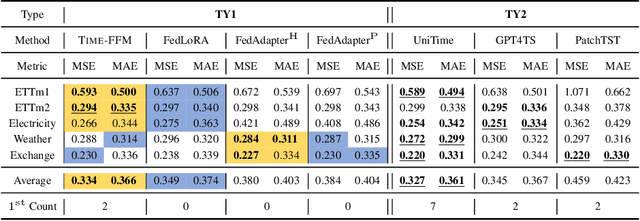
Unlike natural language processing and computer vision, the development of Foundation Models (FMs) for time series forecasting is blocked due to data scarcity. While recent efforts are focused on building such FMs by unlocking the potential of language models (LMs) for time series analysis, dedicated parameters for various downstream forecasting tasks need training, which hinders the common knowledge sharing across domains. Moreover, data owners may hesitate to share the access to local data due to privacy concerns and copyright protection, which makes it impossible to simply construct a FM on cross-domain training instances. To address these issues, we propose Time-FFM, a Federated Foundation Model for Time series forecasting by leveraging pretrained LMs. Specifically, we begin by transforming time series into the modality of text tokens. To bootstrap LMs for time series reasoning, we propose a prompt adaption module to determine domain-customized prompts dynamically instead of artificially. Given the data heterogeneity across domains, we design a personalized federated training strategy by learning global encoders and local prediction heads. Our comprehensive experiments indicate that Time-FFM outperforms state-of-the-arts and promises effective few-shot and zero-shot forecaster.
Personalized Federated Learning for Spatio-Temporal Forecasting: A Dual Semantic Alignment-Based Contrastive Approach
Apr 04, 2024



The existing federated learning (FL) methods for spatio-temporal forecasting fail to capture the inherent spatio-temporal heterogeneity, which calls for personalized FL (PFL) methods to model the spatio-temporally variant patterns. While contrastive learning approach is promising in addressing spatio-temporal heterogeneity, the existing methods are noneffective in determining negative pairs and can hardly apply to PFL paradigm. To tackle this limitation, we propose a novel PFL method, named Federated dUal sEmantic aLignment-based contraStive learning (FUELS), which can adaptively align positive and negative pairs based on semantic similarity, thereby injecting precise spatio-temporal heterogeneity into the latent representation space by auxiliary contrastive tasks. From temporal perspective, a hard negative filtering module is introduced to dynamically align heterogeneous temporal representations for the supplemented intra-client contrastive task. From spatial perspective, we design lightweight-but-efficient prototypes as client-level semantic representations, based on which the server evaluates spatial similarity and yields client-customized global prototypes for the supplemented inter-client contrastive task. Extensive experiments demonstrate that FUELS outperforms state-of-the-art methods, with communication cost decreasing by around 94%.