 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Distributed Knowledge Congruence in Proxy-data-free Federated Distillation
Paper and Code
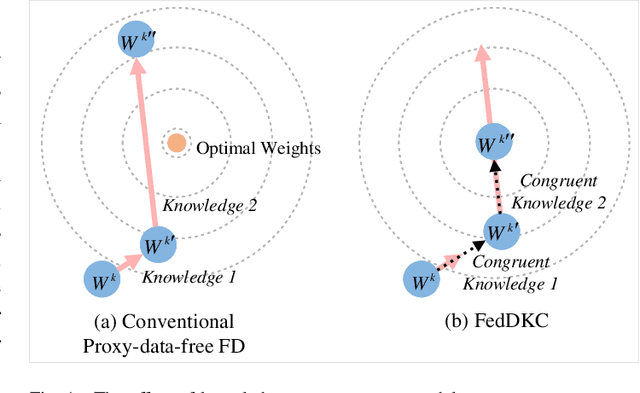
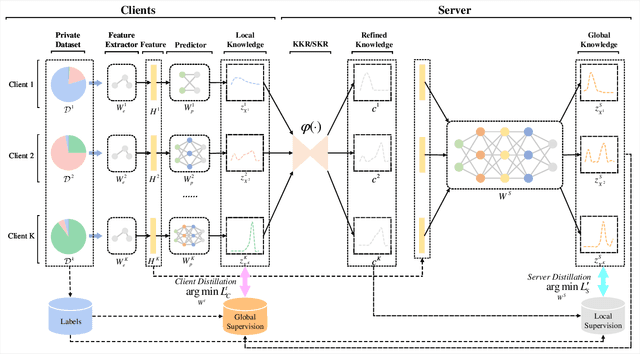
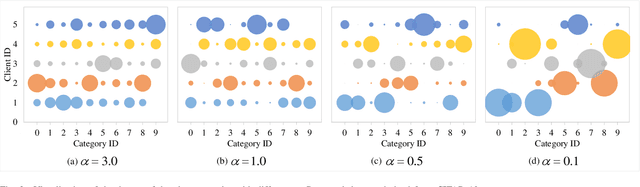

Federated learning (FL) is a distributed machine learning paradigm in which the server periodically aggregates local model parameters from clients without assembling their private data. Constrained communication and personalization requirements pose severe challenges to FL. Federated distillation (FD) is proposed to simultaneously address the above two problems, which exchanges knowledge between the server and clients, supporting heterogeneous local models while significantly reducing communication overhead. However, most existing FD methods require a proxy dataset, which is often unavailable in reality. A few recent proxy-data-free FD approaches can eliminate the need for additional public data, but suffer from remarkable discrepancy among local knowledge due to model heterogeneity, leading to ambiguous representation on the server and inevitable accuracy degradation. To tackle this issue, we propose a proxy-data-free FD algorithm based on distributed knowledge congruence (FedDKC). FedDKC leverages well-designed refinement strategies to narrow local knowledge differences into an acceptable upper bound, so as to mitigate the negative effects of knowledge incongruence. Specifically, from perspectives of peak probability and Shannon entropy of local knowledge, we design kernel-based knowledge refinement (KKR) and searching-based knowledge refinement (SKR) respectively, and theoretically guarantee that the refined-local knowledge can satisfy an approximately-similar distribution and be regarded as congruent. Extensive experiments conducted on three common datasets demonstrate that our proposed FedDKC significantly outperforms the state-of-the-art (accuracy boosts in 93.33% comparisons, Top-1 accuracy boosts by up to 4.38%, and Top-5 accuracy boosts by up to 10.31%) on various heterogeneous settings while evidently improving the convergence speed.