 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing: Robust Vision-Guided Cross-Modal Prompt Learning under Label Noise
Apr 10, 2026Prompt learning is a parameter-efficient approach for vision-language models, yet its robustness under label noise is less investigated. Visual content contains richer and more reliable semantic information, which remains more robust under label noise. However, the prompt itself is highly susceptible to label noise. Motivated by this intuition, we propose VisPrompt, a lightweight and robust vision-guided prompt learning framework for noisy-label settings. Specifically, we exploit a cross-modal attention mechanism to reversely inject visual semantics into prompt representations. This enables the prompt tokens to selectively aggregate visual information relevant to the current sample, thereby improving robustness by anchoring prompt learning to stable instance-level visual evidence and reducing the influence of noisy supervision. To address the instability caused by using the same way of injecting visual information for all samples, despite differences in the quality of their visual cues, we further introduce a lightweight conditional modulation mechanism to adaptively control the strength of visual information injection, which strikes a more robust balance between text-side semantic priors and image-side instance evidence. The proposed framework effectively suppresses the noise-induced disturbances, reduce instability in prompt updates, and alleviate memorization of mislabeled samples. VisPrompt significantly improves robustness while keeping the pretrained VLM backbone frozen and introducing only a small amount of additional trainable parameters. Extensive experiments under synthetic and real-world label noise demonstrate that VisPrompt generally outperforms existing baselines on seven benchmark datasets and achieves stronger robustness. Our code is publicly available at https://github.com/gezbww/Vis_Prompt.
FedRG: Unleashing the Representation Geometry for Federated Learning with Noisy Clients
Mar 20, 2026Federated learning (FL) suffers from performance degradation due to the inevitable presence of noisy annotations in distributed scenarios. Existing approaches have advanced in distinguishing noisy samples from the dataset for label correction by leveraging loss values. However, noisy samples recognition relying on scalar loss lacks reliability for FL under heterogeneous scenarios. In this paper, we rethink this paradigm from a representation perspective and propose \method~(\textbf{Fed}erated under \textbf{R}epresentation \textbf{G}emometry), which follows \textbf{the principle of ``representation geometry priority''} to recognize noisy labels. Firstly, \method~creates label-agnostic spherical representations by using self-supervision. It then iteratively fits a spherical von Mises-Fisher (vMF) mixture model to this geometry using previously identified clean samples to capture semantic clusters. This geometric evidence is integrated with a semantic-label soft mapping mechanism to derive a distribution divergence between the label-free and annotated label-conditioned feature space, which robustly identifies noisy samples and updates the vMF mixture model with the newly separated clean dataset. Lastly, we employ an additional personalized noise absorption matrix on noisy labels to achieve robust optimization. Extensive experimental results demonstrate that \method~significantly outperforms state-of-the-art methods for FL with data heterogeneity under diverse noisy clients scenarios.
Beyond Model Scale Limits: End-Edge-Cloud Federated Learning with Self-Rectified Knowledge Agglomeration
Jan 01, 2025



The rise of End-Edge-Cloud Collaboration (EECC) offers a promising paradigm for Artificial Intelligence (AI) model training across end devices, edge servers, and cloud data centers, providing enhanced reliability and reduced latency. Hierarchical Federated Learning (HFL) can benefit from this paradigm by enabling multi-tier model aggregation across distributed computing nodes. However, the potential of HFL is significantly constrained by the inherent heterogeneity and dynamic characteristics of EECC environments. Specifically, the uniform model structure bounded by the least powerful end device across all computing nodes imposes a performance bottleneck. Meanwhile, coupled heterogeneity in data distributions and resource capabilities across tiers disrupts hierarchical knowledge transfer, leading to biased updates and degraded performance. Furthermore, the mobility and fluctuating connectivity of computing nodes in EECC environments introduce complexities in dynamic node migration, further compromising the robustness of the training process. To address multiple challenges within a unified framework, we propose End-Edge-Cloud Federated Learning with Self-Rectified Knowledge Agglomeration (FedEEC), which is a novel EECC-empowered FL framework that allows the trained models from end, edge, to cloud to grow larger in size and stronger in generalization ability. FedEEC introduces two key innovations: (1) Bridge Sample Based Online Distillation Protocol (BSBODP), which enables knowledge transfer between neighboring nodes through generated bridge samples, and (2) Self-Knowledge Rectification (SKR), which refines the transferred knowledge to prevent suboptimal cloud model optimization. The proposed framework effectively handles both cross-tier resource heterogeneity and effective knowledge transfer between neighboring nodes, while satisfying the migration-resilient requirements of EECC.
Peak-Controlled Logits Poisoning Attack in Federated Distillation
Jul 25, 2024Federated Distillation (FD) offers an innovative approach to distributed machine learning, leveraging knowledge distillation for efficient and flexible cross-device knowledge transfer without necessitating the upload of extensive model parameters to a central server. While FD has gained popularity, its vulnerability to poisoning attacks remains underexplored. To address this gap, we previously introduced FDLA (Federated Distillation Logits Attack), a method that manipulates logits communication to mislead and degrade the performance of client models. However, the impact of FDLA on participants with different identities and the effects of malicious modifications at various stages of knowledge transfer remain unexplored. To this end, we present PCFDLA (Peak-Controlled Federated Distillation Logits Attack), an advanced and more stealthy logits poisoning attack method for FD. PCFDLA enhances the effectiveness of FDLA by carefully controlling the peak values of logits to create highly misleading yet inconspicuous modifications. Furthermore, we introduce a novel metric for better evaluating attack efficacy, demonstrating that PCFDLA maintains stealth while being significantly more disruptive to victim models compared to its predecessors. Experimental results across various datasets confirm the superior impact of PCFDLA on model accuracy, solidifying its potential threat in federated distillation systems.
Logits Poisoning Attack in Federated Distillation
Jan 08, 2024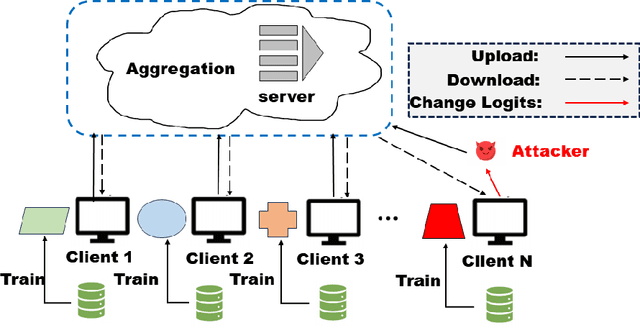
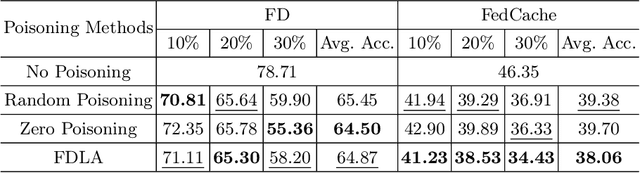
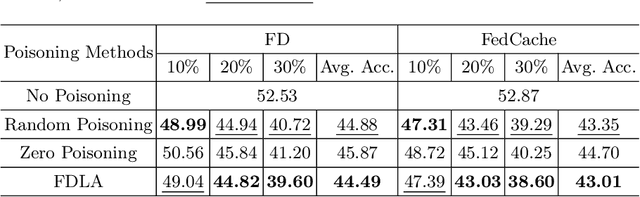
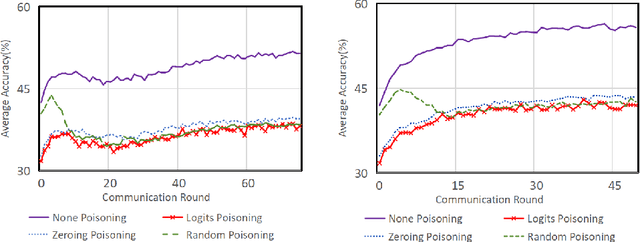
Federated Distillation (FD) is a novel and promising distributed machine learning paradigm, where knowledge distillation is leveraged to facilitate a more efficient and flexible cross-device knowledge transfer in federated learning. By optimizing local models with knowledge distillation, FD circumvents the necessity of uploading large-scale model parameters to the central server, simultaneously preserving the raw data on local clients. Despite the growing popularity of FD, there is a noticeable gap in previous works concerning the exploration of poisoning attacks within this framework. This can lead to a scant understanding of the vulnerabilities to potential adversarial actions. To this end, we introduce FDLA, a poisoning attack method tailored for FD. FDLA manipulates logit communications in FD, aiming to significantly degrade model performance on clients through misleading the discrimination of private samples. Through extensive simulation experiments across a variety of datasets, attack scenarios, and FD configurations, we demonstrate that LPA effectively compromises client model accuracy, outperforming established baseline algorithms in this regard. Our findings underscore the critical need for robust defense mechanisms in FD settings to mitigate such adversarial threats.
Improving Communication Efficiency of Federated Distillation via Accumulating Local Updates
Dec 07, 2023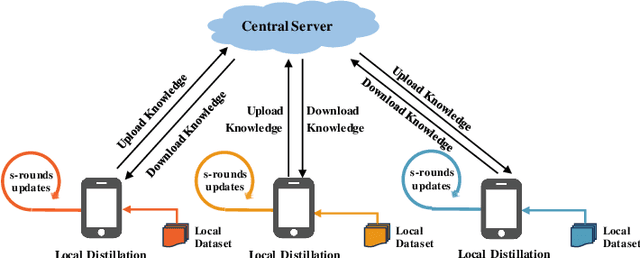
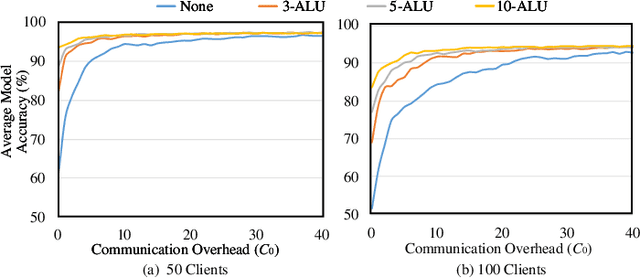
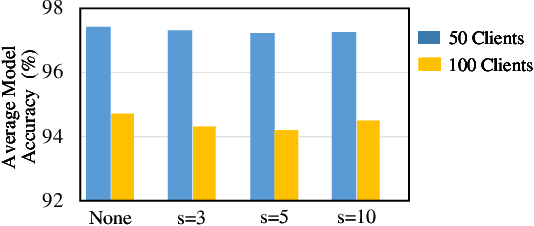
As an emerging federated learning paradigm, federated distillation enables communication-efficient model training by transmitting only small-scale knowledge during the learning process. To further improve the communication efficiency of federated distillation, we propose a novel technique, ALU, which accumulates multiple rounds of local updates before transferring the knowledge to the central server. ALU drastically decreases the frequency of communication in federated distillation, thereby significantly reducing the communication overhead during the training process. Empirical experiments demonstrate the substantial effect of ALU in improving the communication efficiency of federated distillation.