 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogits Poisoning Attack in Federated Distillation
Paper and Code
Jan 08, 2024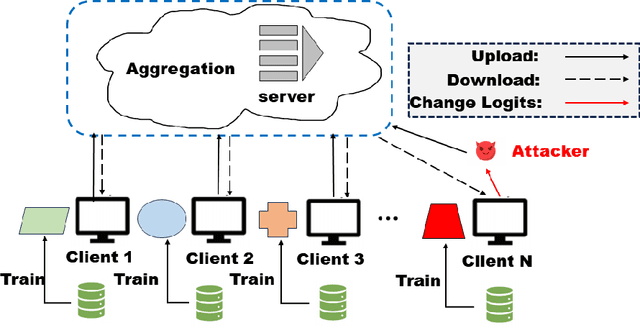
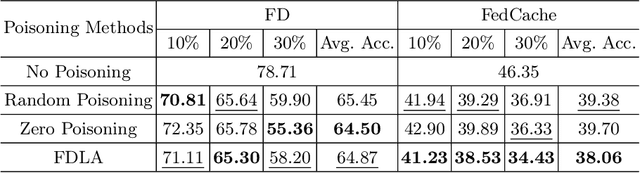
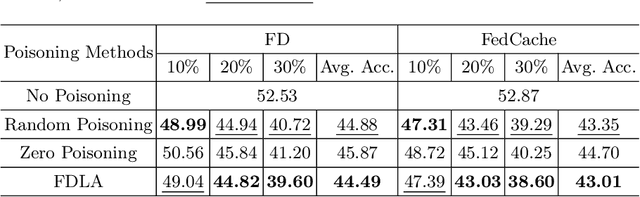
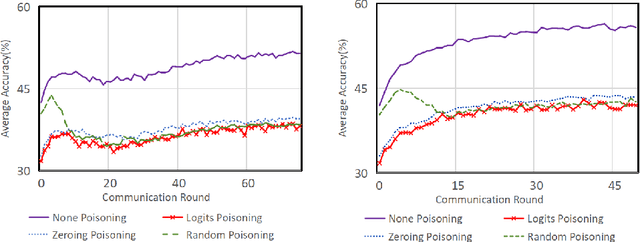
Federated Distillation (FD) is a novel and promising distributed machine learning paradigm, where knowledge distillation is leveraged to facilitate a more efficient and flexible cross-device knowledge transfer in federated learning. By optimizing local models with knowledge distillation, FD circumvents the necessity of uploading large-scale model parameters to the central server, simultaneously preserving the raw data on local clients. Despite the growing popularity of FD, there is a noticeable gap in previous works concerning the exploration of poisoning attacks within this framework. This can lead to a scant understanding of the vulnerabilities to potential adversarial actions. To this end, we introduce FDLA, a poisoning attack method tailored for FD. FDLA manipulates logit communications in FD, aiming to significantly degrade model performance on clients through misleading the discrimination of private samples. Through extensive simulation experiments across a variety of datasets, attack scenarios, and FD configurations, we demonstrate that LPA effectively compromises client model accuracy, outperforming established baseline algorithms in this regard. Our findings underscore the critical need for robust defense mechanisms in FD settings to mitigate such adversarial threats.