Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Communication Efficiency of Federated Distillation via Accumulating Local Updates
Paper and Code
Dec 07, 2023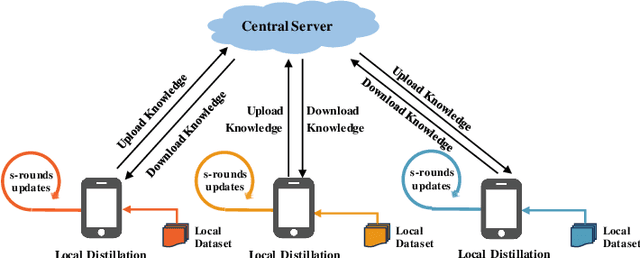
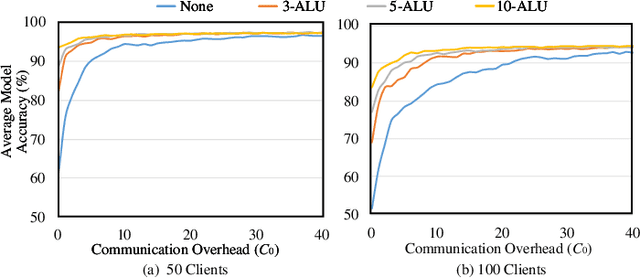
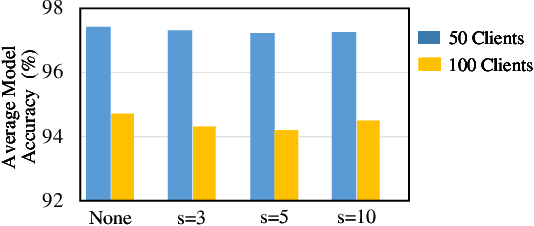
As an emerging federated learning paradigm, federated distillation enables communication-efficient model training by transmitting only small-scale knowledge during the learning process. To further improve the communication efficiency of federated distillation, we propose a novel technique, ALU, which accumulates multiple rounds of local updates before transferring the knowledge to the central server. ALU drastically decreases the frequency of communication in federated distillation, thereby significantly reducing the communication overhead during the training process. Empirical experiments demonstrate the substantial effect of ALU in improving the communication efficiency of federated distillation.
* 2 pages, 3 figures
View paper on