 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInnovator: Triggering the Innovative Capabilities of LLMs
Feb 21, 2026The application of Large Language Models (LLMs) in accelerating scientific discovery has garnered increasing attention, with a key focus on constructing research agents endowed with innovative capability, i.e., the ability to autonomously generate novel and significant research ideas. Existing approaches predominantly rely on sophisticated prompt engineering and lack a systematic training paradigm. To address this, we propose DeepInnovator, a training framework designed to trigger the innovative capability of LLMs. Our approach comprises two core components. (1) ``Standing on the shoulders of giants''. We construct an automated data extraction pipeline to extract and organize structured research knowledge from a vast corpus of unlabeled scientific literature. (2) ``Conjectures and refutations''. We introduce a ``Next Idea Prediction'' training paradigm, which models the generation of research ideas as an iterative process of continuously predicting, evaluating, and refining plausible and novel next idea. Both automatic and expert evaluations demonstrate that our DeepInnovator-14B significantly outperforms untrained baselines, achieving win rates of 80.53\%-93.81\%, and attains performance comparable to that of current leading LLMs. This work provides a scalable training pathway toward building research agents with genuine, originative innovative capability, and will open-source the dataset to foster community advancement. Source code and data are available at: https://github.com/HKUDS/DeepInnovator.
Why Your Deep Research Agent Fails? On Hallucination Evaluation in Full Research Trajectory
Jan 30, 2026Diagnosing the failure mechanisms of Deep Research Agents (DRAs) remains a critical challenge. Existing benchmarks predominantly rely on end-to-end evaluation, obscuring critical intermediate hallucinations, such as flawed planning, that accumulate throughout the research trajectory. To bridge this gap, we propose a shift from outcome-based to process-aware evaluation by auditing the full research trajectory. We introduce the PIES Taxonomy to categorize hallucinations along functional components (Planning vs. Summarization) and error properties (Explicit vs. Implicit). We instantiate this taxonomy into a fine-grained evaluation framework that decomposes the trajectory to rigorously quantify these hallucinations. Leveraging this framework to isolate 100 distinctively hallucination-prone tasks including adversarial scenarios, we curate DeepHalluBench. Experiments on six state-of-theart DRAs reveal that no system achieves robust reliability. Furthermore, our diagnostic analysis traces the etiology of these failures to systemic deficits, specifically hallucination propagation and cognitive biases, providing foundational insights to guide future architectural optimization. Data and code are available at https://github.com/yuhao-zhan/DeepHalluBench.
Needle in the Web: A Benchmark for Retrieving Targeted Web Pages in the Wild
Dec 18, 2025Large Language Models (LLMs) have evolved from simple chatbots into sophisticated agents capable of automating complex real-world tasks, where browsing and reasoning over live web content is key to assessing retrieval and cognitive skills. Existing benchmarks like BrowseComp and xBench-DeepSearch emphasize complex reasoning searches requiring multi-hop synthesis but neglect Fuzzy Exploratory Search, namely queries that are vague and multifaceted, where users seek the most relevant webpage rather than a single factual answer. To address this gap, we introduce Needle in the Web, a novel benchmark specifically designed to evaluate modern search agents and LLM-based systems on their ability to retrieve and reason over real-world web content in response to ambiguous, exploratory queries under varying levels of difficulty. Needle in the Web comprises 663 questions spanning seven distinct domains. To ensure high query quality and answer uniqueness, we employ a flexible methodology that reliably generates queries of controllable difficulty based on factual claims of web contents. We benchmark three leading LLMs and three agent-based search systems on Needle in the Web, finding that most models struggle: many achieve below 35% accuracy, and none consistently excel across domains or difficulty levels. These findings reveal that Needle in the Web presents a significant challenge for current search systems and highlights the open problem of effective fuzzy retrieval under semantic ambiguity.
Understanding DeepResearch via Reports
Oct 09, 2025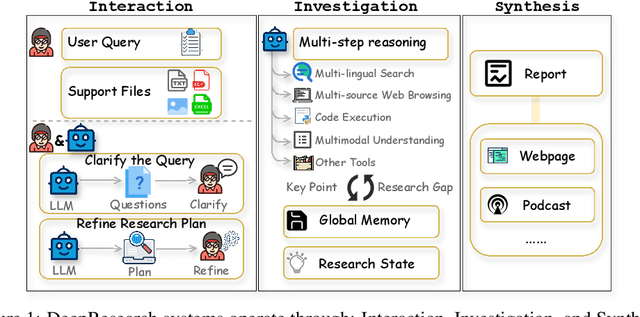

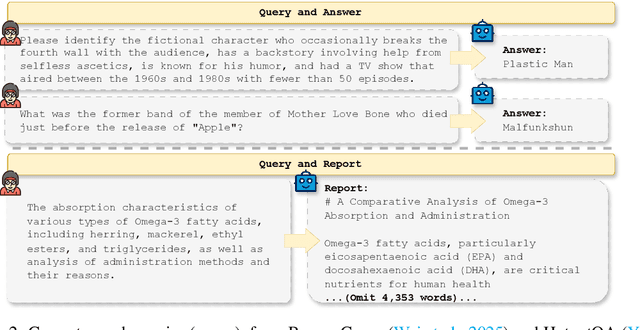

DeepResearch agents represent a transformative AI paradigm, conducting expert-level research through sophisticated reasoning and multi-tool integration. However, evaluating these systems remains critically challenging due to open-ended research scenarios and existing benchmarks that focus on isolated capabilities rather than holistic performance. Unlike traditional LLM tasks, DeepResearch systems must synthesize diverse sources, generate insights, and present coherent findings, which are capabilities that resist simple verification. To address this gap, we introduce DeepResearch-ReportEval, a comprehensive framework designed to assess DeepResearch systems through their most representative outputs: research reports. Our approach systematically measures three dimensions: quality, redundancy, and factuality, using an innovative LLM-as-a-Judge methodology achieving strong expert concordance. We contribute a standardized benchmark of 100 curated queries spanning 12 real-world categories, enabling systematic capability comparison. Our evaluation of four leading commercial systems reveals distinct design philosophies and performance trade-offs, establishing foundational insights as DeepResearch evolves from information assistants toward intelligent research partners. Source code and data are available at: https://github.com/HKUDS/DeepResearch-Eval.
Speech Enhancement Using Continuous Embeddings of Neural Audio Codec
Feb 22, 2025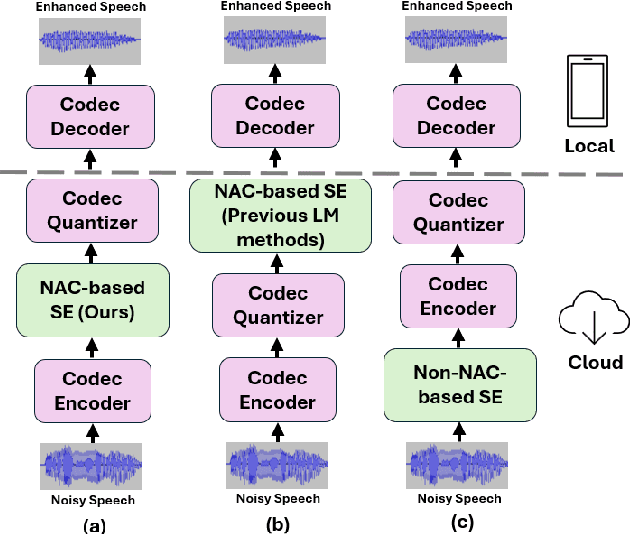
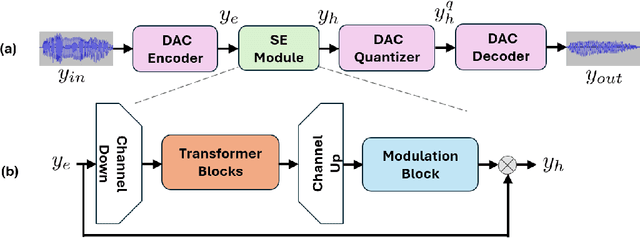

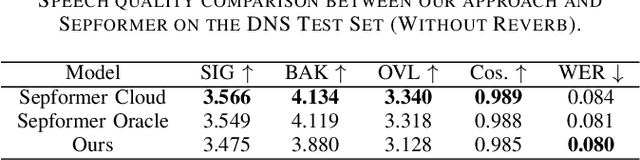
Recent advancements in Neural Audio Codec (NAC) models have inspired their use in various speech processing tasks, including speech enhancement (SE). In this work, we propose a novel, efficient SE approach by leveraging the pre-quantization output of a pretrained NAC encoder. Unlike prior NAC-based SE methods, which process discrete speech tokens using Language Models (LMs), we perform SE within the continuous embedding space of the pretrained NAC, which is highly compressed along the time dimension for efficient representation. Our lightweight SE model, optimized through an embedding-level loss, delivers results comparable to SE baselines trained on larger datasets, with a significantly lower real-time factor of 0.005. Additionally, our method achieves a low GMAC of 3.94, reducing complexity 18-fold compared to Sepformer in a simulated cloud-based audio transmission environment. This work highlights a new, efficient NAC-based SE solution, particularly suitable for cloud applications where NAC is used to compress audio before transmission. Copyright 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
MetaChain: A Fully-Automated and Zero-Code Framework for LLM Agents
Feb 09, 2025Large Language Model (LLM) Agents have demonstrated remarkable capabilities in task automation and intelligent decision-making, driving the widespread adoption of agent development frameworks such as LangChain and AutoGen. However, these frameworks predominantly serve developers with extensive technical expertise - a significant limitation considering that only 0.03 % of the global population possesses the necessary programming skills. This stark accessibility gap raises a fundamental question: Can we enable everyone, regardless of technical background, to build their own LLM agents using natural language alone? To address this challenge, we introduce MetaChain-a Fully-Automated and highly Self-Developing framework that enables users to create and deploy LLM agents through Natural Language Alone. Operating as an autonomous Agent Operating System, MetaChain comprises four key components: i) Agentic System Utilities, ii) LLM-powered Actionable Engine, iii) Self-Managing File System, and iv) Self-Play Agent Customization module. This lightweight yet powerful system enables efficient and dynamic creation and modification of tools, agents, and workflows without coding requirements or manual intervention. Beyond its code-free agent development capabilities, MetaChain also serves as a versatile multi-agent system for General AI Assistants. Comprehensive evaluations on the GAIA benchmark demonstrate MetaChain's effectiveness in generalist multi-agent tasks, surpassing existing state-of-the-art methods. Furthermore, MetaChain's Retrieval-Augmented Generation (RAG)-related capabilities have shown consistently superior performance compared to many alternative LLM-based solutions.
Tumor Detection, Segmentation and Classification Challenge on Automated 3D Breast Ultrasound: The TDSC-ABUS Challenge
Jan 26, 2025



Breast cancer is one of the most common causes of death among women worldwide. Early detection helps in reducing the number of deaths. Automated 3D Breast Ultrasound (ABUS) is a newer approach for breast screening, which has many advantages over handheld mammography such as safety, speed, and higher detection rate of breast cancer. Tumor detection, segmentation, and classification are key components in the analysis of medical images, especially challenging in the context of 3D ABUS due to the significant variability in tumor size and shape, unclear tumor boundaries, and a low signal-to-noise ratio. The lack of publicly accessible, well-labeled ABUS datasets further hinders the advancement of systems for breast tumor analysis. Addressing this gap, we have organized the inaugural Tumor Detection, Segmentation, and Classification Challenge on Automated 3D Breast Ultrasound 2023 (TDSC-ABUS2023). This initiative aims to spearhead research in this field and create a definitive benchmark for tasks associated with 3D ABUS image analysis. In this paper, we summarize the top-performing algorithms from the challenge and provide critical analysis for ABUS image examination. We offer the TDSC-ABUS challenge as an open-access platform at https://tdsc-abus2023.grand-challenge.org/ to benchmark and inspire future developments in algorithmic research.
MiniRAG: Towards Extremely Simple Retrieval-Augmented Generation
Jan 14, 2025



The growing demand for efficient and lightweight Retrieval-Augmented Generation (RAG) systems has highlighted significant challenges when deploying Small Language Models (SLMs) in existing RAG frameworks. Current approaches face severe performance degradation due to SLMs' limited semantic understanding and text processing capabilities, creating barriers for widespread adoption in resource-constrained scenarios. To address these fundamental limitations, we present MiniRAG, a novel RAG system designed for extreme simplicity and efficiency. MiniRAG introduces two key technical innovations: (1) a semantic-aware heterogeneous graph indexing mechanism that combines text chunks and named entities in a unified structure, reducing reliance on complex semantic understanding, and (2) a lightweight topology-enhanced retrieval approach that leverages graph structures for efficient knowledge discovery without requiring advanced language capabilities. Our extensive experiments demonstrate that MiniRAG achieves comparable performance to LLM-based methods even when using SLMs while requiring only 25\% of the storage space. Additionally, we contribute a comprehensive benchmark dataset for evaluating lightweight RAG systems under realistic on-device scenarios with complex queries. We fully open-source our implementation and datasets at: https://github.com/HKUDS/MiniRAG.
Decoupling Weighing and Selecting for Integrating Multiple Graph Pre-training Tasks
Mar 03, 2024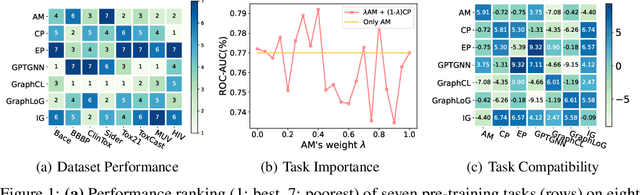
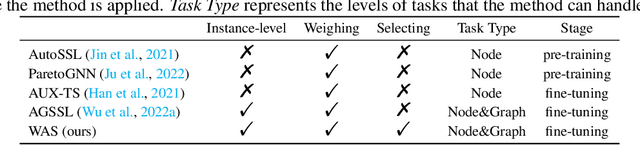
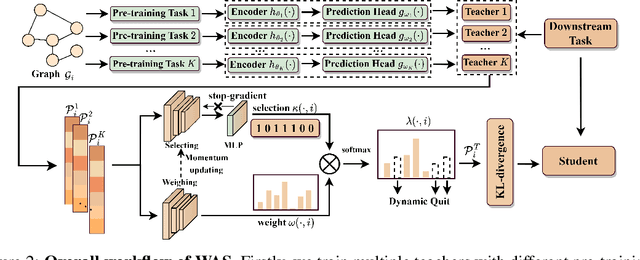
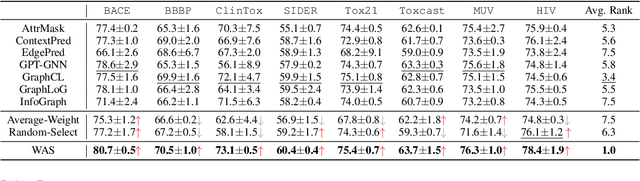
Recent years have witnessed the great success of graph pre-training for graph representation learning. With hundreds of graph pre-training tasks proposed, integrating knowledge acquired from multiple pre-training tasks has become a popular research topic. In this paper, we identify two important collaborative processes for this topic: (1) select: how to select an optimal task combination from a given task pool based on their compatibility, and (2) weigh: how to weigh the selected tasks based on their importance. While there currently has been a lot of work focused on weighing, comparatively little effort has been devoted to selecting. This paper proposes a novel instance-level framework for integrating multiple graph pre-training tasks, Weigh And Select (WAS), where the two collaborative processes, weighing and selecting, are combined by decoupled siamese networks. Specifically, it first adaptively learns an optimal combination of tasks for each instance from a given task pool, based on which a customized instance-level task weighing strategy is learned. Extensive experiments on 16 graph datasets across node-level and graph-level downstream tasks have demonstrated that by combining a few simple but classical tasks, WAS can achieve comparable performance to other leading counterparts. The code is available at https://github.com/TianyuFan0504/WAS.
Fine-tuning Graph Neural Networks by Preserving Graph Generative Patterns
Dec 21, 2023Recently, the paradigm of pre-training and fine-tuning graph neural networks has been intensively studied and applied in a wide range of graph mining tasks. Its success is generally attributed to the structural consistency between pre-training and downstream datasets, which, however, does not hold in many real-world scenarios. Existing works have shown that the structural divergence between pre-training and downstream graphs significantly limits the transferability when using the vanilla fine-tuning strategy. This divergence leads to model overfitting on pre-training graphs and causes difficulties in capturing the structural properties of the downstream graphs. In this paper, we identify the fundamental cause of structural divergence as the discrepancy of generative patterns between the pre-training and downstream graphs. Furthermore, we propose G-Tuning to preserve the generative patterns of downstream graphs. Given a downstream graph G, the core idea is to tune the pre-trained GNN so that it can reconstruct the generative patterns of G, the graphon W. However, the exact reconstruction of a graphon is known to be computationally expensive. To overcome this challenge, we provide a theoretical analysis that establishes the existence of a set of alternative graphons called graphon bases for any given graphon. By utilizing a linear combination of these graphon bases, we can efficiently approximate W. This theoretical finding forms the basis of our proposed model, as it enables effective learning of the graphon bases and their associated coefficients. Compared with existing algorithms, G-Tuning demonstrates an average improvement of 0.5% and 2.6% on in-domain and out-of-domain transfer learning experiments, respectively.