 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Graph Self-supervised Learning via Multi-teacher Knowledge Distillation
Paper and Code
Oct 05, 2022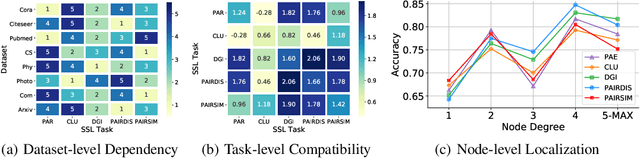
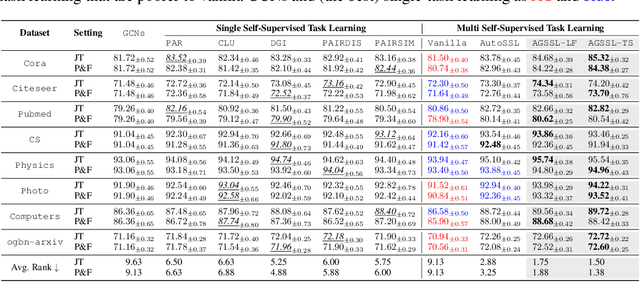

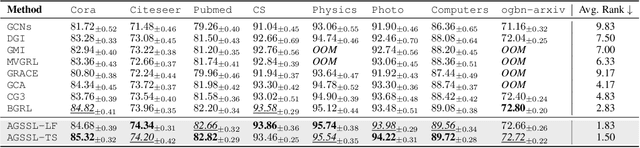
Self-supervised learning on graphs has recently achieved remarkable success in graph representation learning. With hundreds of self-supervised pretext tasks proposed over the past few years, the research community has greatly developed, and the key is no longer to design more powerful but complex pretext tasks, but to make more effective use of those already on hand. This paper studies the problem of how to automatically, adaptively, and dynamically learn instance-level self-supervised learning strategies for each node from a given pool of pretext tasks. In this paper, we propose a novel multi-teacher knowledge distillation framework for Automated Graph Self-Supervised Learning (AGSSL), which consists of two main branches: (i) Knowledge Extraction: training multiple teachers with different pretext tasks, so as to extract different levels of knowledge with different inductive biases; (ii) Knowledge Integration: integrating different levels of knowledge and distilling them into the student model. Without simply treating different teachers as equally important, we provide a provable theoretical guideline for how to integrate the knowledge of different teachers, i.e., the integrated teacher probability should be close to the true Bayesian class-probability. To approach the theoretical optimum in practice, two adaptive knowledge integration strategies are proposed to construct a relatively "good" integrated teacher. Extensive experiments on eight datasets show that AGSSL can benefit from multiple pretext tasks, outperforming the corresponding individual tasks; by combining a few simple but classical pretext tasks, the resulting performance is comparable to other leading counterparts.