 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOViT: Vision Transformer for Multi-objective Design and Characterization of Nanophotonic Devices
May 17, 2022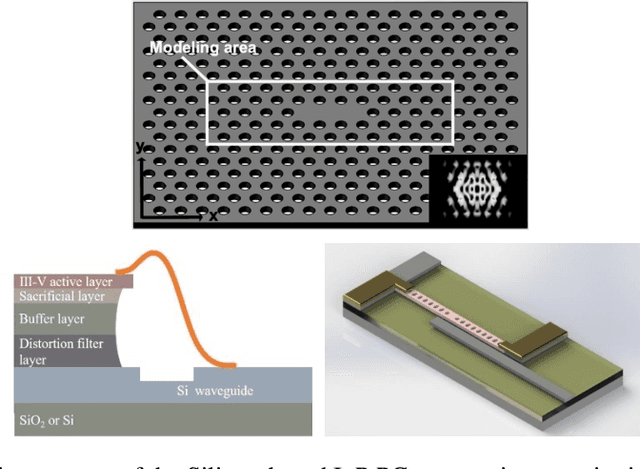
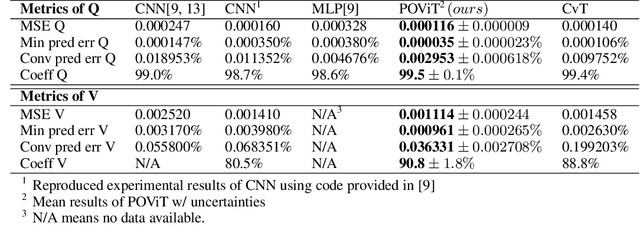
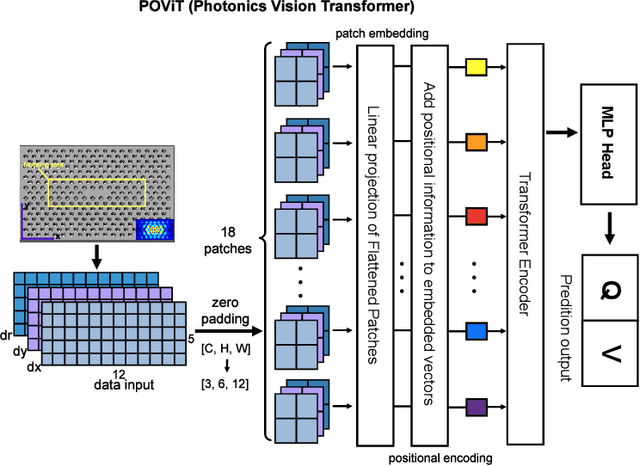
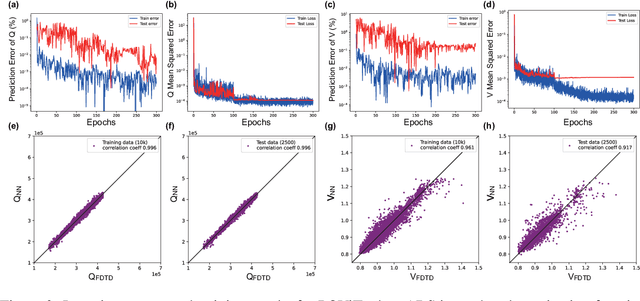
We solve a fundamental challenge in semiconductor IC design: the fast and accurate characterization of nanoscale photonic devices. Much like the fusion between AI and EDA, many efforts have been made to apply DNNs such as convolutional neural networks (CNN) to prototype and characterize next-gen optoelectronic devices commonly found in photonic integrated circuits (PIC) and LiDAR. These prior works generally strive to predict the quality factor (Q) and modal volume (V) of for instance, photonic crystals, with ultra-high accuracy and speed. However, state-of-the-art models are still far from being directly applicable in the real-world: e.g. the correlation coefficient of V ($V_{coeff}$ ) is only about 80%, which is much lower than what it takes to generate reliable and reproducible nanophotonic designs. Recently, attention-based transformer models have attracted extensive interests and been widely used in CV and NLP. In this work, we propose the first-ever Transformer model (POViT) to efficiently design and simulate semiconductor photonic devices with multiple objectives. Unlike the standard Vision Transformer (ViT), we supplied photonic crystals as data input and changed the activation layer from GELU to an absolute-value function (ABS). Our experiments show that POViT exceeds results reported by previous models significantly. The correlation coefficient $V_{coeff}$ increases by over 12% (i.e., to 92.0%) and the prediction errors of Q is reduced by an order of magnitude, among several other key metric improvements. Our work has the potential to drive the expansion of EDA to fully automated photonic design. The complete dataset and code will be released to aid researchers endeavoring in the interdisciplinary field of physics and computer science.