 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy "classic" Transformers are shallow and how to make them go deep
Dec 11, 2023Since its introduction in 2017, Transformer has emerged as the leading neural network architecture, catalyzing revolutionary advancements in many AI disciplines. The key innovation in Transformer is a Self-Attention (SA) mechanism designed to capture contextual information. However, extending the original Transformer design to models of greater depth has proven exceedingly challenging, if not impossible. Even though various modifications have been proposed in order to stack more layers of SA mechanism into deeper models, a full understanding of this depth problem remains elusive. In this paper, we conduct a comprehensive investigation, both theoretically and empirically, to substantiate the claim that the depth problem is caused by \emph{token similarity escalation}; that is, tokens grow increasingly alike after repeated applications of the SA mechanism. Our analysis reveals that, driven by the invariant leading eigenspace and large spectral gaps of attention matrices, token similarity provably escalates at a linear rate. Based on the gained insight, we propose a simple strategy that, unlike most existing methods, surgically removes excessive similarity without discounting the SA mechanism as a whole. Preliminary experimental results confirm the effectiveness of the proposed approach on moderate-scale post-norm Transformer models.
POViT: Vision Transformer for Multi-objective Design and Characterization of Nanophotonic Devices
May 17, 2022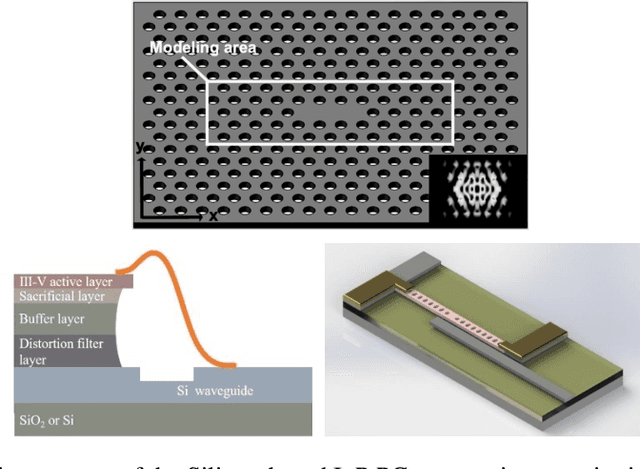
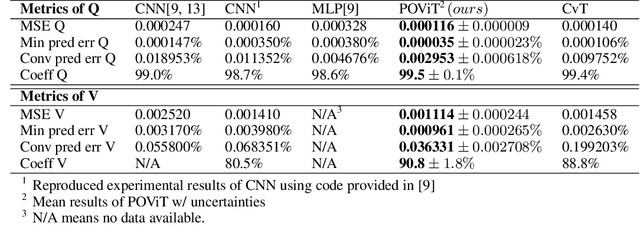
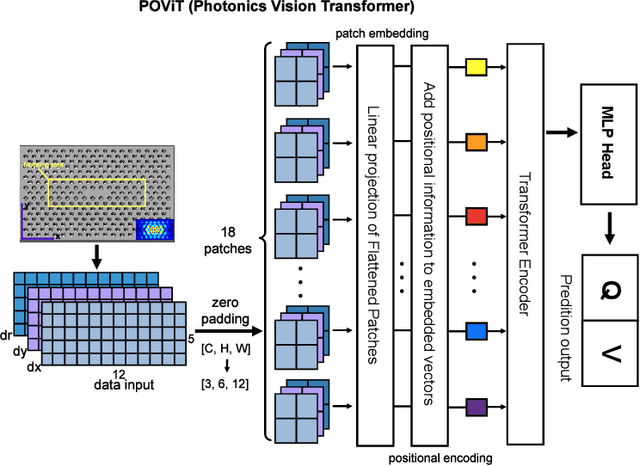
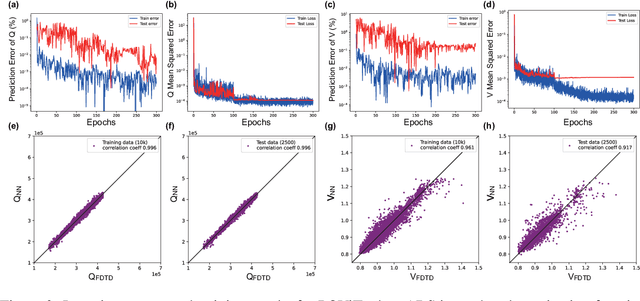
We solve a fundamental challenge in semiconductor IC design: the fast and accurate characterization of nanoscale photonic devices. Much like the fusion between AI and EDA, many efforts have been made to apply DNNs such as convolutional neural networks (CNN) to prototype and characterize next-gen optoelectronic devices commonly found in photonic integrated circuits (PIC) and LiDAR. These prior works generally strive to predict the quality factor (Q) and modal volume (V) of for instance, photonic crystals, with ultra-high accuracy and speed. However, state-of-the-art models are still far from being directly applicable in the real-world: e.g. the correlation coefficient of V ($V_{coeff}$ ) is only about 80%, which is much lower than what it takes to generate reliable and reproducible nanophotonic designs. Recently, attention-based transformer models have attracted extensive interests and been widely used in CV and NLP. In this work, we propose the first-ever Transformer model (POViT) to efficiently design and simulate semiconductor photonic devices with multiple objectives. Unlike the standard Vision Transformer (ViT), we supplied photonic crystals as data input and changed the activation layer from GELU to an absolute-value function (ABS). Our experiments show that POViT exceeds results reported by previous models significantly. The correlation coefficient $V_{coeff}$ increases by over 12% (i.e., to 92.0%) and the prediction errors of Q is reduced by an order of magnitude, among several other key metric improvements. Our work has the potential to drive the expansion of EDA to fully automated photonic design. The complete dataset and code will be released to aid researchers endeavoring in the interdisciplinary field of physics and computer science.
Householder-Absolute Neural Layers For High Variability and Deep Trainability
Jun 08, 2021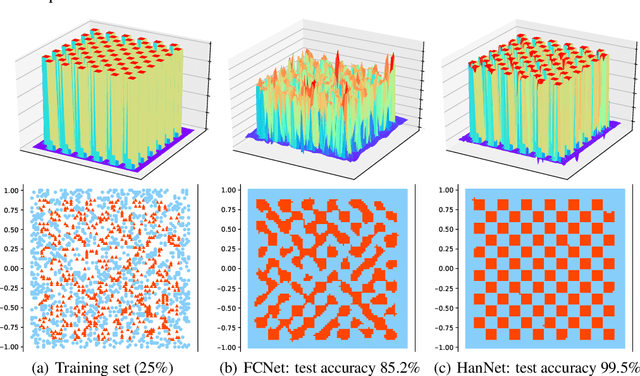
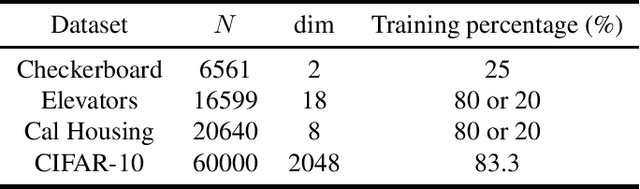
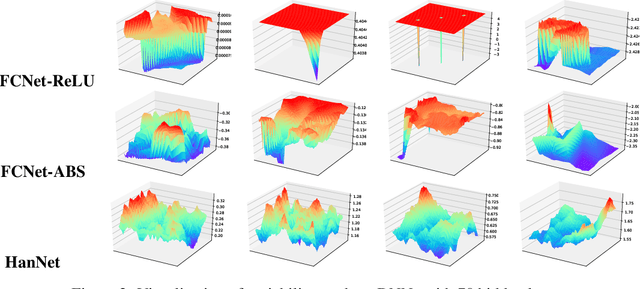

We propose a new architecture for artificial neural networks called Householder-absolute neural layers, or Han-layers for short, that use Householder reflectors as weight matrices and the absolute-value function for activation. Han-layers, functioning as fully connected layers, are motivated by recent results on neural-network variability and are designed to increase activation ratio and reduce the chance of Collapse to Constants. Neural networks constructed chiefly from Han-layers are called HanNets. By construction, HanNets enjoy a theoretical guarantee that vanishing or exploding gradient never occurs. We conduct several proof-of-concept experiments. Some surprising results obtained on styled test problems suggest that, under certain conditions, HanNets exhibit an unusual ability to produce nearly perfect solutions unattainable by fully connected networks. Experiments on regression datasets show that HanNets can significantly reduce the number of model parameters while maintaining or improving the level of generalization accuracy. In addition, by adding a few Han-layers into the pre-classification FC-layer of a convolutional neural network, we are able to quickly improve a state-of-the-art result on CIFAR10 dataset. These proof-of-concept results are sufficient to necessitate further studies on HanNets to understand their capacities and limits, and to exploit their potentials in real-world applications.
Variability of Artificial Neural Networks
May 20, 2021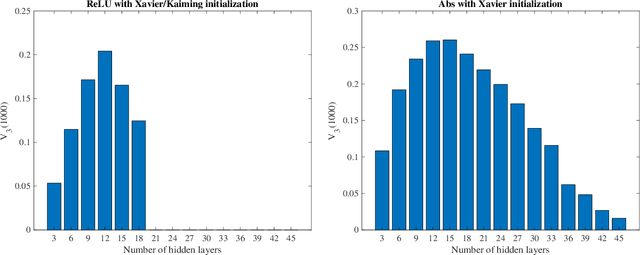
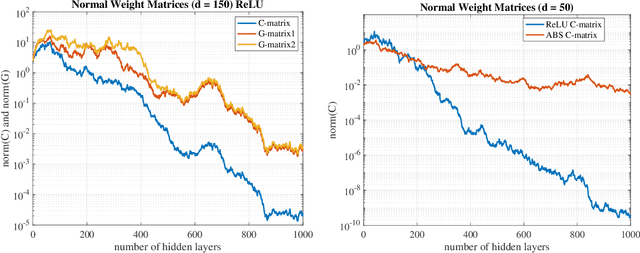
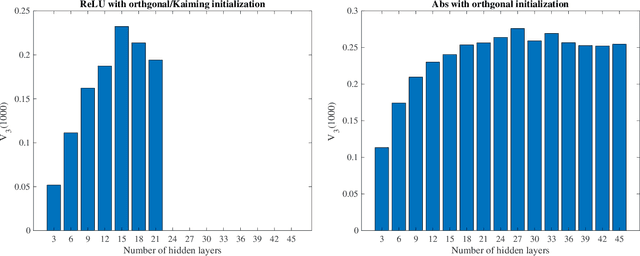
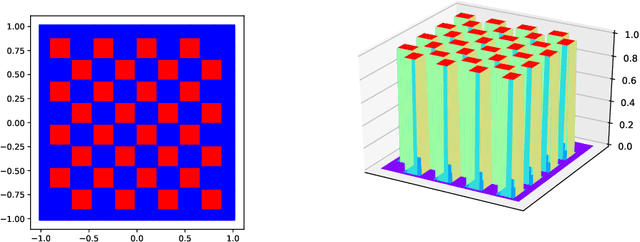
What makes an artificial neural network easier to train and more likely to produce desirable solutions than other comparable networks? In this paper, we provide a new angle to study such issues under the setting of a fixed number of model parameters which in general is the most dominant cost factor. We introduce a notion of variability and show that it correlates positively to the activation ratio and negatively to a phenomenon called {Collapse to Constants} (or C2C), which is closely related but not identical to the phenomenon commonly known as vanishing gradient. Experiments on a styled model problem empirically verify that variability is indeed a key performance indicator for fully connected neural networks. The insights gained from this variability study will help the design of new and effective neural network architectures.
AuxBlocks: Defense Adversarial Example via Auxiliary Blocks
Feb 18, 2019



Deep learning models are vulnerable to adversarial examples, which poses an indisputable threat to their applications. However, recent studies observe gradient-masking defenses are self-deceiving methods if an attacker can realize this defense. In this paper, we propose a new defense method based on appending information. We introduce the Aux Block model to produce extra outputs as a self-ensemble algorithm and analytically investigate the robustness mechanism of Aux Block. We have empirically studied the efficiency of our method against adversarial examples in two types of white-box attacks, and found that even in the full white-box attack where an adversary can craft malicious examples from defense models, our method has a more robust performance of about 54.6% precision on Cifar10 dataset and 38.7% precision on Mini-Imagenet dataset. Another advantage of our method is that it is able to maintain the prediction accuracy of the classification model on clean images, and thereby exhibits its high potential in practical applications