 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Distributed Backdoor Attacks in Federated Learning
Mar 04, 2026While federated learning protects data privacy, it also makes the model update process vulnerable to long-term stealthy perturbations. Existing studies on backdoor attacks in federated learning mainly focus on trigger design or poisoning strategies, typically assuming that identical perturbations behave similarly across different model architectures. This assumption overlooks the impact of model structure on perturbation effectiveness. From a structure-aware perspective, this paper analyzes the coupling relationship between model architectures and backdoor perturbations. We introduce two metrics, Structural Responsiveness Score (SRS) and Structural Compatibility Coefficient (SCC), to measure a model's sensitivity to perturbations and its preference for fractal perturbations. Based on these metrics, we develop a structure-aware fractal perturbation injection framework (TFI) to study the role of architectural properties in the backdoor injection process. Experimental results show that model architecture significantly influences the propagation and aggregation of perturbations. Networks with multi-path feature fusion can amplify and retain fractal perturbations even under low poisoning ratios, while models with low structural compatibility constrain their effectiveness. Further analysis reveals a strong correlation between SCC and attack success rate, suggesting that SCC can predict perturbation survivability. These findings highlight that backdoor behaviors in federated learning depend not only on perturbation design or poisoning intensity but also on the interaction between model architecture and aggregation mechanisms, offering new insights for structure-aware defense design.
Decentralized Non-convex Stochastic Optimization with Heterogeneous Variance
Feb 12, 2026Decentralized optimization is critical for solving large-scale machine learning problems over distributed networks, where multiple nodes collaborate through local communication. In practice, the variances of stochastic gradient estimators often differ across nodes, yet their impact on algorithm design and complexity remains unclear. To address this issue, we propose D-NSS, a decentralized algorithm with node-specific sampling, and establish its sample complexity depending on the arithmetic mean of local standard deviations, achieving tighter bounds than existing methods that rely on the worst-case or quadratic mean. We further derive a matching sample complexity lower bound under heterogeneous variance, thereby proving the optimality of this dependence. Moreover, we extend the framework with a variance reduction technique and develop D-NSS-VR, which under the mean-squared smoothness assumption attains an improved sample complexity bound while preserving the arithmetic-mean dependence. Finally, numerical experiments validate the theoretical results and demonstrate the effectiveness of the proposed algorithms.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Stability and Generalization of Nonconvex Optimization with Heavy-Tailed Noise
Jan 27, 2026The empirical evidence indicates that stochastic optimization with heavy-tailed gradient noise is more appropriate to characterize the training of machine learning models than that with standard bounded gradient variance noise. Most existing works on this phenomenon focus on the convergence of optimization errors, while the analysis for generalization bounds under the heavy-tailed gradient noise remains limited. In this paper, we develop a general framework for establishing generalization bounds under heavy-tailed noise. Specifically, we introduce a truncation argument to achieve the generalization error bound based on the algorithmic stability under the assumption of bounded $p$th centered moment with $p\in(1,2]$. Building on this framework, we further provide the stability and generalization analysis for several popular stochastic algorithms under heavy-tailed noise, including clipped and normalized stochastic gradient descent, as well as their mini-batch and momentum variants.
Policy Mirror Descent with Temporal Difference Learning: Sample Complexity under Online Markov Data
Dec 30, 2025This paper studies the policy mirror descent (PMD) method, which is a general policy optimization framework in reinforcement learning and can cover a wide range of policy gradient methods by specifying difference mirror maps. Existing sample complexity analysis for policy mirror descent either focuses on the generative sampling model, or the Markovian sampling model but with the action values being explicitly approximated to certain pre-specified accuracy. In contrast, we consider the sample complexity of policy mirror descent with temporal difference (TD) learning under the Markovian sampling model. Two algorithms called Expected TD-PMD and Approximate TD-PMD have been presented, which are off-policy and mixed policy algorithms respectively. Under a small enough constant policy update step size, the $\tilde{O}(\varepsilon^{-2})$ (a logarithm factor about $\varepsilon$ is hidden in $\tilde{O}(\cdot)$) sample complexity can be established for them to achieve average-time $\varepsilon$-optimality. The sample complexity is further improved to $O(\varepsilon^{-2})$ (without the hidden logarithm factor) to achieve the last-iterate $\varepsilon$-optimality based on adaptive policy update step sizes.
Automatically discovering heuristics in a complex SAT solver with large language models
Jul 30, 2025Satisfiability problem (SAT) is a cornerstone of computational complexity with broad industrial applications, and it remains challenging to optimize modern SAT solvers in real-world settings due to their intricate architectures. While automatic configuration frameworks have been developed, they rely on manually constrained search spaces and yield limited performance gains. This work introduces a novel paradigm which effectively optimizes complex SAT solvers via Large Language Models (LLMs), and a tool called AutoModSAT is developed. Three fundamental challenges are addressed in order to achieve superior performance: (1) LLM-friendly solver: Systematic guidelines are proposed for developing a modularized solver to meet LLMs' compatibility, emphasizing code simplification, information share and bug reduction; (2) Automatic prompt optimization: An unsupervised automatic prompt optimization method is introduced to advance the diversity of LLMs' output; (3) Efficient search strategy: We design a presearch strategy and an EA evolutionary algorithm for the final efficient and effective discovery of heuristics. Extensive experiments across a wide range of datasets demonstrate that AutoModSAT achieves 50% performance improvement over the baseline solver and achieves 30% superiority against the state-of-the-art (SOTA) solvers. Moreover, AutoModSAT attains a 20% speedup on average compared to parameter-tuned alternatives of the SOTA solvers, showcasing the enhanced capability in handling complex problem instances. This work bridges the gap between AI-driven heuristics discovery and mission-critical system optimization, and provides both methodological advancements and empirically validated results for next-generation complex solver development.
MSV-Mamba: A Multiscale Vision Mamba Network for Echocardiography Segmentation
Jan 13, 2025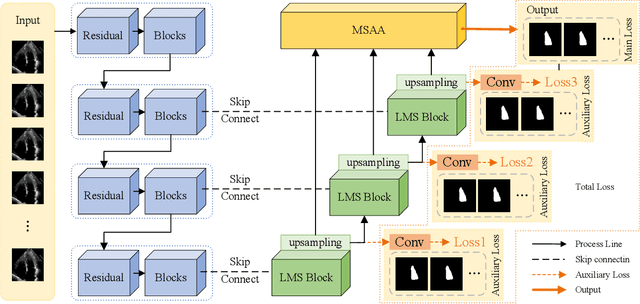
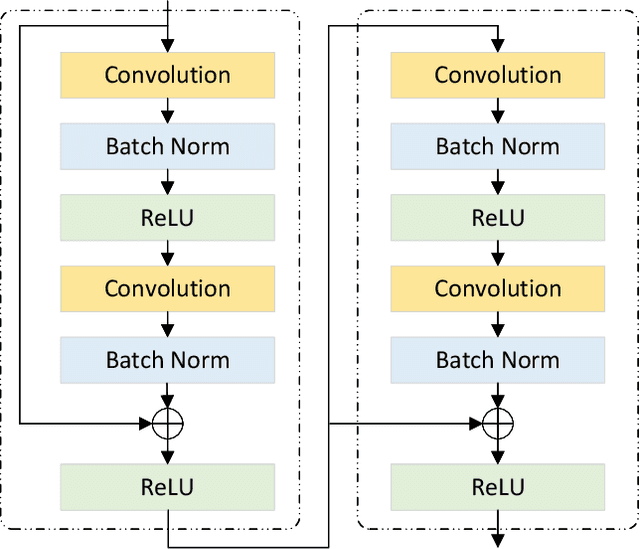
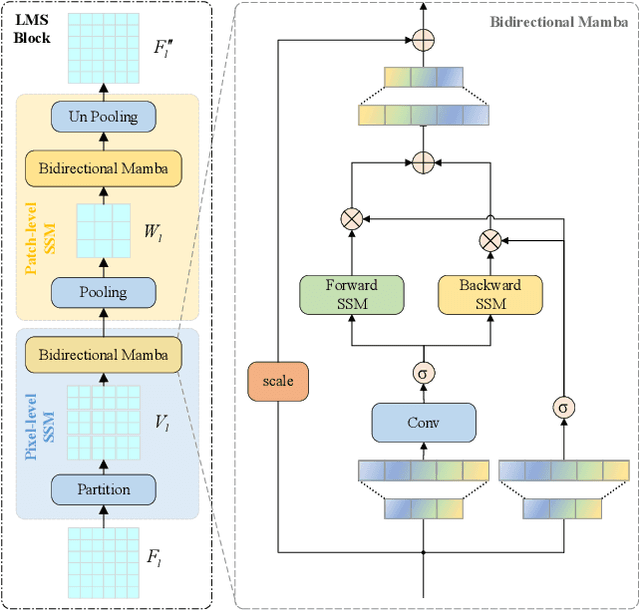
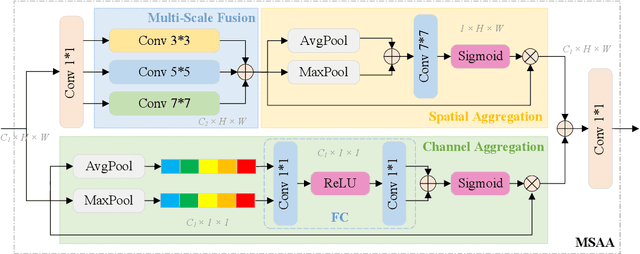
Ultrasound imaging frequently encounters challenges, such as those related to elevated noise levels, diminished spatiotemporal resolution, and the complexity of anatomical structures. These factors significantly hinder the model's ability to accurately capture and analyze structural relationships and dynamic patterns across various regions of the heart. Mamba, an emerging model, is one of the most cutting-edge approaches that is widely applied to diverse vision and language tasks. To this end, this paper introduces a U-shaped deep learning model incorporating a large-window Mamba scale (LMS) module and a hierarchical feature fusion approach for echocardiographic segmentation. First, a cascaded residual block serves as an encoder and is employed to incrementally extract multiscale detailed features. Second, a large-window multiscale mamba module is integrated into the decoder to capture global dependencies across regions and enhance the segmentation capability for complex anatomical structures. Furthermore, our model introduces auxiliary losses at each decoder layer and employs a dual attention mechanism to fuse multilayer features both spatially and across channels. This approach enhances segmentation performance and accuracy in delineating complex anatomical structures. Finally, the experimental results using the EchoNet-Dynamic and CAMUS datasets demonstrate that the model outperforms other methods in terms of both accuracy and robustness. For the segmentation of the left ventricular endocardium (${LV}_{endo}$), the model achieved optimal values of 95.01 and 93.36, respectively, while for the left ventricular epicardium (${LV}_{epi}$), values of 87.35 and 87.80, respectively, were achieved. This represents an improvement ranging between 0.54 and 1.11 compared with the best-performing model.
Leave-One-Out Analysis for Nonconvex Robust Matrix Completion with General Thresholding Functions
Jul 28, 2024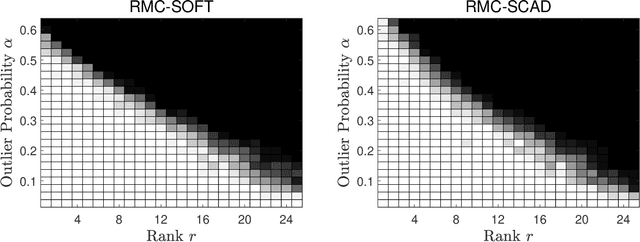
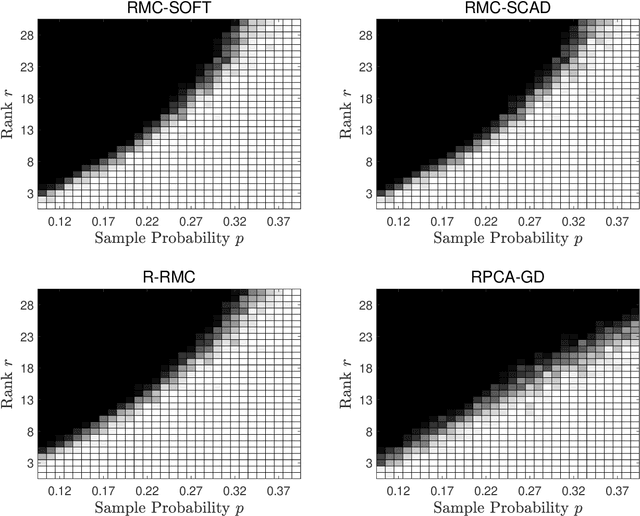
We study the problem of robust matrix completion (RMC), where the partially observed entries of an underlying low-rank matrix is corrupted by sparse noise. Existing analysis of the non-convex methods for this problem either requires the explicit but empirically redundant regularization in the algorithm or requires sample splitting in the analysis. In this paper, we consider a simple yet efficient nonconvex method which alternates between a projected gradient step for the low-rank part and a thresholding step for the sparse noise part. Inspired by leave-one out analysis for low rank matrix completion, it is established that the method can achieve linear convergence for a general class of thresholding functions, including for example soft-thresholding and SCAD. To the best of our knowledge, this is the first leave-one-out analysis on a nonconvex method for RMC. Additionally, when applying our result to low rank matrix completion, it improves the sampling complexity of existing result for the singular value projection method.
Elementary Analysis of Policy Gradient Methods
Apr 11, 2024

Projected policy gradient under the simplex parameterization, policy gradient and natural policy gradient under the softmax parameterization, are fundamental algorithms in reinforcement learning. There have been a flurry of recent activities in studying these algorithms from the theoretical aspect. Despite this, their convergence behavior is still not fully understood, even given the access to exact policy evaluations. In this paper, we focus on the discounted MDP setting and conduct a systematic study of the aforementioned policy optimization methods. Several novel results are presented, including 1) global linear convergence of projected policy gradient for any constant step size, 2) sublinear convergence of softmax policy gradient for any constant step size, 3) global linear convergence of softmax natural policy gradient for any constant step size, 4) global linear convergence of entropy regularized softmax policy gradient for a wider range of constant step sizes than existing result, 5) tight local linear convergence rate of entropy regularized natural policy gradient, and 6) a new and concise local quadratic convergence rate of soft policy iteration without the assumption on the stationary distribution under the optimal policy. New and elementary analysis techniques have been developed to establish these results.
AutoSAT: Automatically Optimize SAT Solvers via Large Language Models
Feb 16, 2024



Heuristics are crucial in SAT solvers, while no heuristic rules are suitable for all problem instances. Therefore, it typically requires to refine specific solvers for specific problem instances. In this context, we present AutoSAT, a novel framework for automatically optimizing heuristics in SAT solvers. AutoSAT is based on Large Large Models (LLMs) which is able to autonomously generate code, conduct evaluation, then utilize the feedback to further optimize heuristics, thereby reducing human intervention and enhancing solver capabilities. AutoSAT operates on a plug-and-play basis, eliminating the need for extensive preliminary setup and model training, and fosters a Chain of Thought collaborative process with fault-tolerance, ensuring robust heuristic optimization. Extensive experiments on a Conflict-Driven Clause Learning (CDCL) solver demonstrates the overall superior performance of AutoSAT, especially in solving some specific SAT problem instances.