 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Rules for Causal Identification with Background Knowledge
Jul 21, 2024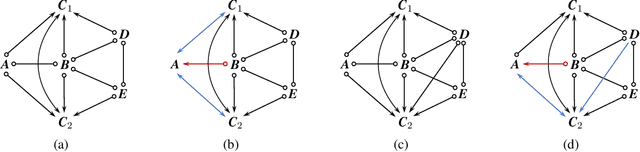
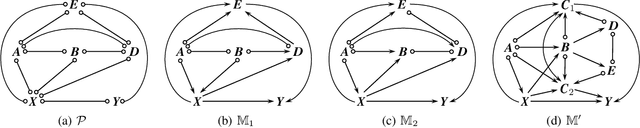
Identifying causal relations is crucial for a variety of downstream tasks. In additional to observational data, background knowledge (BK), which could be attained from human expertise or experiments, is usually introduced for uncovering causal relations. This raises an open problem that in the presence of latent variables, what causal relations are identifiable from observational data and BK. In this paper, we propose two novel rules for incorporating BK, which offer a new perspective to the open problem. In addition, we show that these rules are applicable in some typical causality tasks, such as determining the set of possible causal effects with observational data. Our rule-based approach enhances the state-of-the-art method by circumventing a process of enumerating block sets that would otherwise take exponential complexity.
Deciphering Raw Data in Neuro-Symbolic Learning with Provable Guarantees
Aug 21, 2023



Neuro-symbolic hybrid systems are promising for integrating machine learning and symbolic reasoning, where perception models are facilitated with information inferred from a symbolic knowledge base through logical reasoning. Despite empirical evidence showing the ability of hybrid systems to learn accurate perception models, the theoretical understanding of learnability is still lacking. Hence, it remains unclear why a hybrid system succeeds for a specific task and when it may fail given a different knowledge base. In this paper, we introduce a novel way of characterising supervision signals from a knowledge base, and establish a criterion for determining the knowledge's efficacy in facilitating successful learning. This, for the first time, allows us to address the two questions above by inspecting the knowledge base under investigation. Our analysis suggests that many knowledge bases satisfy the criterion, thus enabling effective learning, while some fail to satisfy it, indicating potential failures. Comprehensive experiments confirm the utility of our criterion on benchmark tasks.
Open-Sampling: Exploring Out-of-Distribution data for Re-balancing Long-tailed datasets
Jun 24, 2022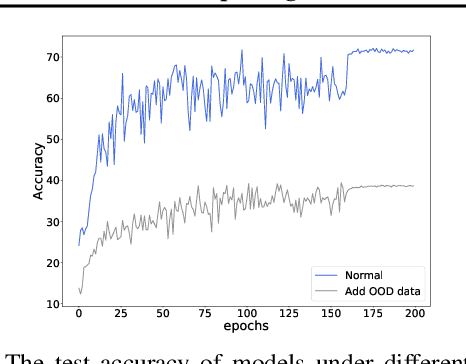
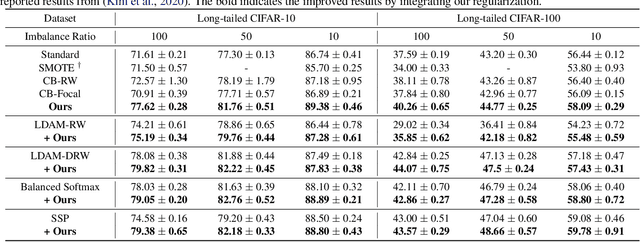
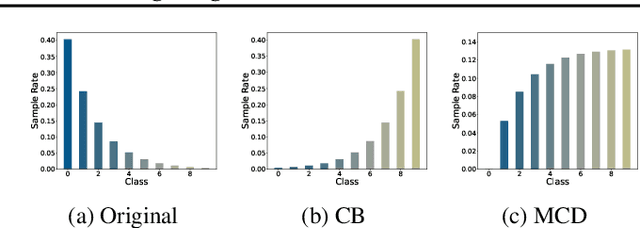
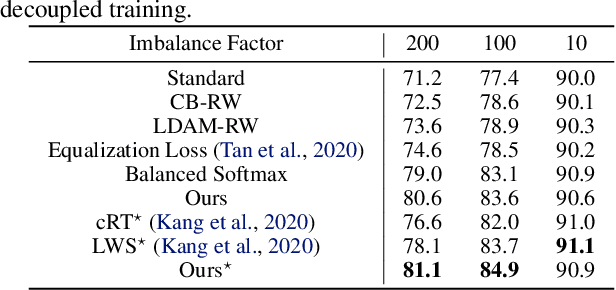
Deep neural networks usually perform poorly when the training dataset suffers from extreme class imbalance. Recent studies found that directly training with out-of-distribution data (i.e., open-set samples) in a semi-supervised manner would harm the generalization performance. In this work, we theoretically show that out-of-distribution data can still be leveraged to augment the minority classes from a Bayesian perspective. Based on this motivation, we propose a novel method called Open-sampling, which utilizes open-set noisy labels to re-balance the class priors of the training dataset. For each open-set instance, the label is sampled from our pre-defined distribution that is complementary to the distribution of original class priors. We empirically show that Open-sampling not only re-balances the class priors but also encourages the neural network to learn separable representations. Extensive experiments demonstrate that our proposed method significantly outperforms existing data re-balancing methods and can boost the performance of existing state-of-the-art methods.
Can Adversarial Training Be Manipulated By Non-Robust Features?
Jan 31, 2022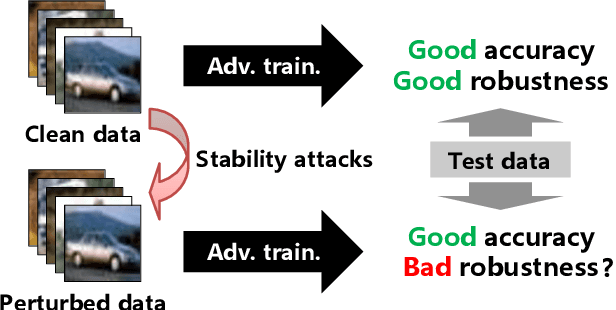
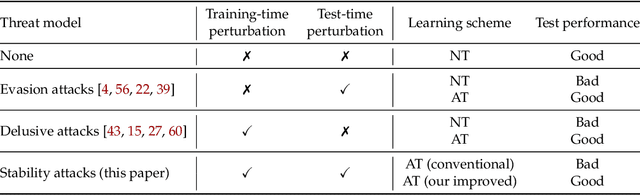
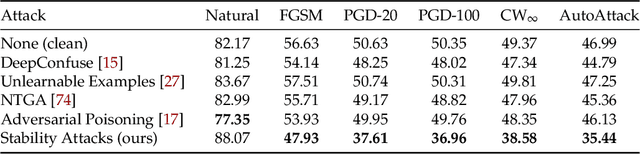
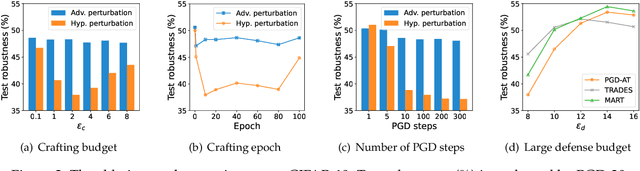
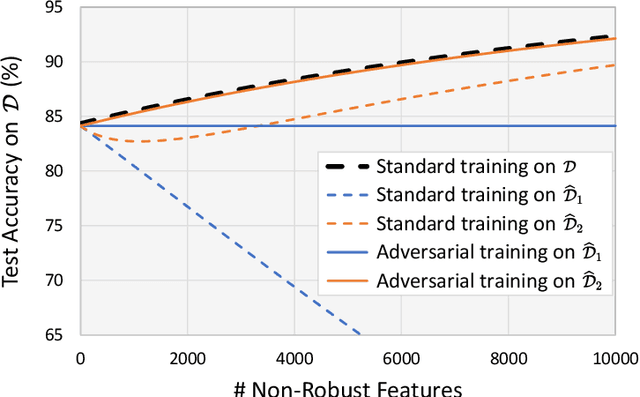
Adversarial training, originally designed to resist test-time adversarial examples, has shown to be promising in mitigating training-time availability attacks. This defense ability, however, is challenged in this paper. We identify a novel threat model named stability attacks, which aims to hinder robust availability by slightly perturbing the training data. Under this threat, we find that adversarial training using a conventional defense budget $\epsilon$ provably fails to provide test robustness in a simple statistical setting when the non-robust features of the training data are reinforced by $\epsilon$-bounded perturbation. Further, we analyze the necessity of enlarging the defense budget to counter stability attacks. Finally, comprehensive experiments demonstrate that stability attacks are harmful on benchmark datasets, and thus the adaptive defense is necessary to maintain robustness.
Open-set Label Noise Can Improve Robustness Against Inherent Label Noise
Jun 21, 2021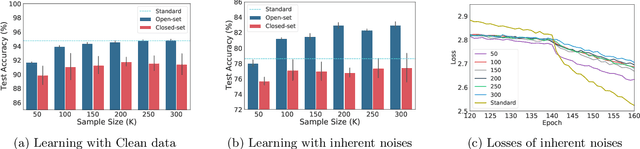
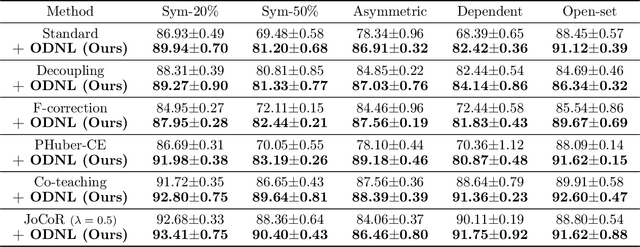
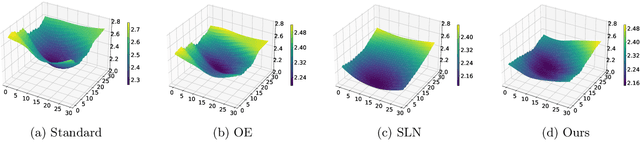
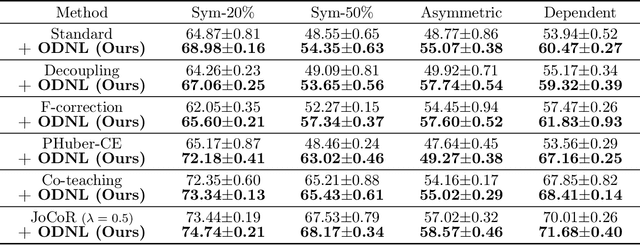
Learning with noisy labels is a practically challenging problem in weakly supervised learning. In the existing literature, open-set noises are always considered to be poisonous for generalization, similar to closed-set noises. In this paper, we empirically show that open-set noisy labels can be non-toxic and even benefit the robustness against inherent noisy labels. Inspired by the observations, we propose a simple yet effective regularization by introducing Open-set samples with Dynamic Noisy Labels (ODNL) into training. With ODNL, the extra capacity of the neural network can be largely consumed in a way that does not interfere with learning patterns from clean data. Through the lens of SGD noise, we show that the noises induced by our method are random-direction, conflict-free and biased, which may help the model converge to a flat minimum with superior stability and enforce the model to produce conservative predictions on Out-of-Distribution instances. Extensive experimental results on benchmark datasets with various types of noisy labels demonstrate that the proposed method not only enhances the performance of many existing robust algorithms but also achieves significant improvement on Out-of-Distribution detection tasks even in the label noise setting.
Improving Model Robustness by Adaptively Correcting Perturbation Levels with Active Queries
Mar 27, 2021
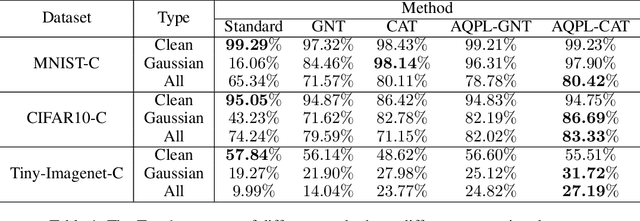
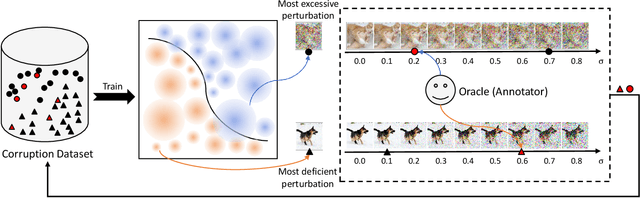
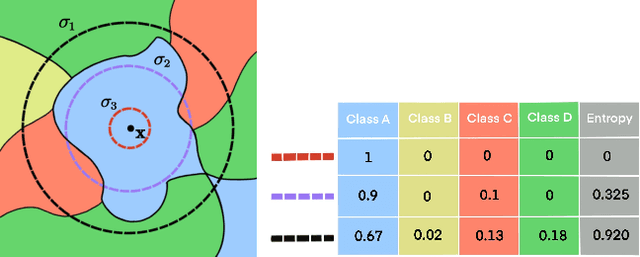
In addition to high accuracy, robustness is becoming increasingly important for machine learning models in various applications. Recently, much research has been devoted to improving the model robustness by training with noise perturbations. Most existing studies assume a fixed perturbation level for all training examples, which however hardly holds in real tasks. In fact, excessive perturbations may destroy the discriminative content of an example, while deficient perturbations may fail to provide helpful information for improving the robustness. Motivated by this observation, we propose to adaptively adjust the perturbation levels for each example in the training process. Specifically, a novel active learning framework is proposed to allow the model to interactively query the correct perturbation level from human experts. By designing a cost-effective sampling strategy along with a new query type, the robustness can be significantly improved with a few queries. Both theoretical analysis and experimental studies validate the effectiveness of the proposed approach.
Provable Defense Against Delusive Poisoning
Feb 09, 2021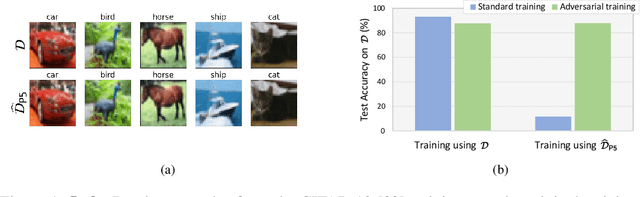
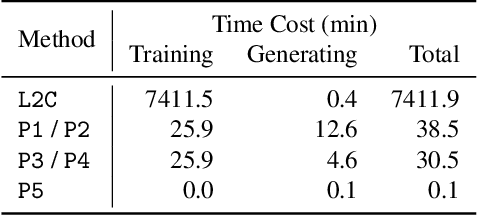
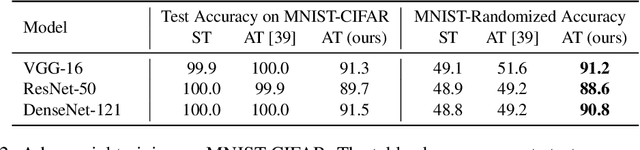
Delusive poisoning is a special kind of attack to obstruct learning, where the learning performance could be significantly deteriorated by only manipulating (even slightly) the features of correctly labeled training examples. By formalizing this malicious attack as finding the worst-case distribution shift at training time within a specific $\infty$-Wasserstein ball, we show that minimizing adversarial risk on the poison data is equivalent to optimizing an upper bound of natural risk on the original data. This implies that adversarial training can be a principled defense method against delusive poisoning. To further understand the internal mechanism of the defense, we disclose that adversarial training can resist the training distribution shift by preventing the learner from overly relying on non-robust features in a natural setting. Finally, we complement our theoretical findings with a set of experiments on popular benchmark datasets, which shows that the defense withstands six different practical attacks. Both theoretical and empirical results vote for adversarial training when confronted with delusive poisoning.
With False Friends Like These, Who Can Have Self-Knowledge?
Dec 29, 2020


Adversarial examples arise from excessive sensitivity of a model. Commonly studied adversarial examples are malicious inputs, crafted by an adversary from correctly classified examples, to induce misclassification. This paper studies an intriguing, yet far overlooked consequence of the excessive sensitivity, that is, a misclassified example can be easily perturbed to help the model to produce correct output. Such perturbed examples look harmless, but actually can be maliciously utilized by a false friend to make the model self-satisfied. Thus we name them hypocritical examples. With false friends like these, a poorly performed model could behave like a state-of-the-art one. Once a deployer trusts the hypocritical performance and uses the "well-performed" model in real-world applications, potential security concerns appear even in benign environments. In this paper, we formalize the hypocritical risk for the first time and propose a defense method specialized for hypocritical examples by minimizing the tradeoff between natural risk and an upper bound of hypocritical risk. Moreover, our theoretical analysis reveals connections between adversarial risk and hypocritical risk. Extensive experiments verify the theoretical results and the effectiveness of our proposed methods.
Accelerated Stochastic Gradient-free and Projection-free Methods
Aug 10, 2020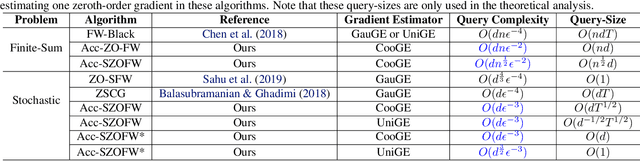
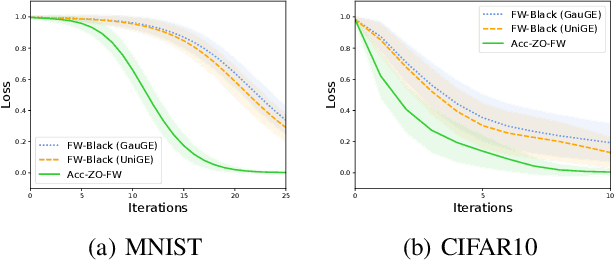
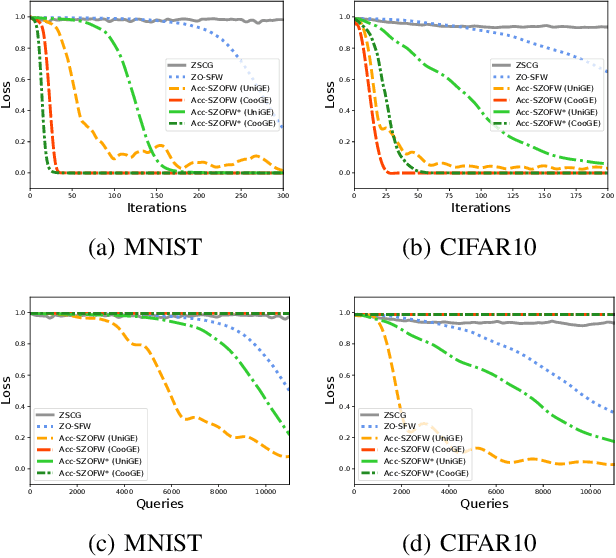
In the paper, we propose a class of accelerated stochastic gradient-free and projection-free (a.k.a., zeroth-order Frank-Wolfe) methods to solve the constrained stochastic and finite-sum nonconvex optimization. Specifically, we propose an accelerated stochastic zeroth-order Frank-Wolfe (Acc-SZOFW) method based on the variance reduced technique of SPIDER/SpiderBoost and a novel momentum accelerated technique. Moreover, under some mild conditions, we prove that the Acc-SZOFW has the function query complexity of $O(d\sqrt{n}\epsilon^{-2})$ for finding an $\epsilon$-stationary point in the finite-sum problem, which improves the exiting best result by a factor of $O(\sqrt{n}\epsilon^{-2})$, and has the function query complexity of $O(d\epsilon^{-3})$ in the stochastic problem, which improves the exiting best result by a factor of $O(\epsilon^{-1})$. To relax the large batches required in the Acc-SZOFW, we further propose a novel accelerated stochastic zeroth-order Frank-Wolfe (Acc-SZOFW*) based on a new variance reduced technique of STORM, which still reaches the function query complexity of $O(d\epsilon^{-3})$ in the stochastic problem without relying on any large batches. In particular, we present an accelerated framework of the Frank-Wolfe methods based on the proposed momentum accelerated technique. The extensive experimental results on black-box adversarial attack and robust black-box classification demonstrate the efficiency of our algorithms.
Visual and Semantic Prototypes-Jointly Guided CNN for Generalized Zero-shot Learning
Aug 14, 2019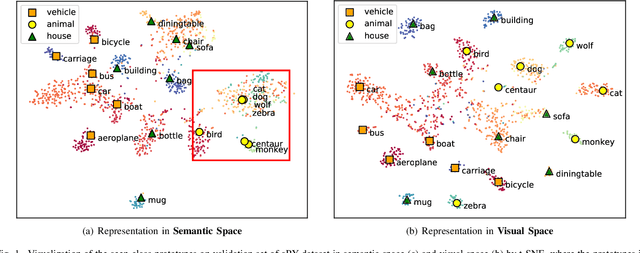
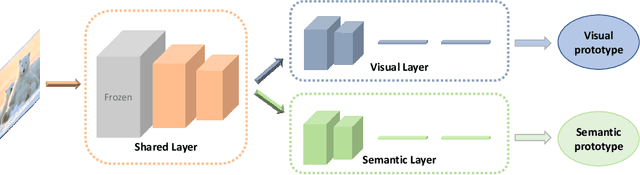


In the process of exploring the world, the curiosity constantly drives humans to cognize new things. Supposing you are a zoologist, for a presented animal image, you can recognize it immediately if you know its class. Otherwise, you would more likely attempt to cognize it by exploiting the side-information (e.g., semantic information, etc.) you have accumulated. Inspired by this, this paper decomposes the generalized zero-shot learning (G-ZSL) task into an open set recognition (OSR) task and a zero-shot learning (ZSL) task, where OSR recognizes seen classes (if we have seen (or known) them) and rejects unseen classes (if we have never seen (or known) them before), while ZSL identifies the unseen classes rejected by the former. Simultaneously, without violating OSR's assumptions (only known class knowledge is available in training), we also first attempt to explore a new generalized open set recognition (G-OSR) by introducing the accumulated side-information from known classes to OSR. For G-ZSL, such a decomposition effectively solves the class overfitting problem with easily misclassifying unseen classes as seen classes. The problem is ubiquitous in most existing G-ZSL methods. On the other hand, for G-OSR, introducing such semantic information of known classes not only improves the recognition performance but also endows OSR with the cognitive ability of unknown classes. Specifically, a visual and semantic prototypes-jointly guided convolutional neural network (VSG-CNN) is proposed to fulfill these two tasks (G-ZSL and G-OSR) in a unified end-to-end learning framework. Extensive experiments on benchmark datasets demonstrate the advantages of our learning framework.