 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPoser: Diffusion Model as Robust 3D Human Pose Prior
Paper and Code


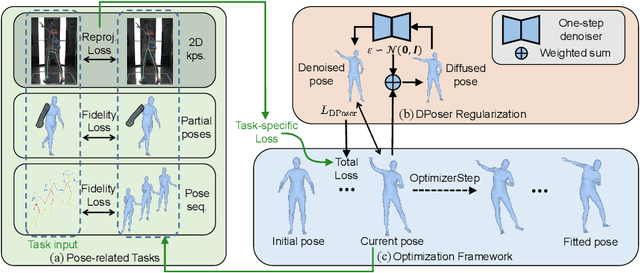

Modeling human pose is a cornerstone in applications from human-robot interaction to augmented reality, yet crafting a robust human pose prior remains a challenge due to biomechanical constraints and diverse human movements. Traditional priors like VAEs and NDFs often fall short in realism and generalization, especially in extreme conditions such as unseen noisy poses. To address these issues, we introduce DPoser, a robust and versatile human pose prior built upon diffusion models. Designed with optimization frameworks, DPoser seamlessly integrates into various pose-centric applications, including human mesh recovery, pose completion, and motion denoising. Specifically, by formulating these tasks as inverse problems, we employ variational diffusion sampling for efficient solving. Furthermore, acknowledging the disparity between the articulated poses we focus on and structured images in previous research, we propose a truncated timestep scheduling to boost performance on downstream tasks. Our exhaustive experiments demonstrate DPoser's superiority over existing state-of-the-art pose priors across multiple tasks.