 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSSF: A 4D Radar and Camera Fusion Framework With Multi-Stage Sampling for 3D Object Detection in Autonomous Driving
Paper and Code
Nov 22, 2024

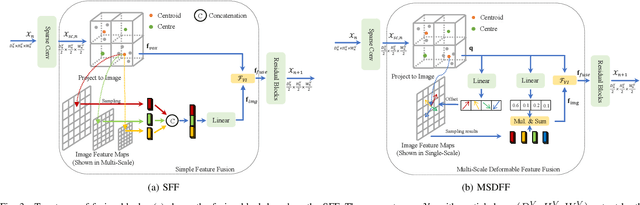

As one of the automotive sensors that have emerged in recent years, 4D millimeter-wave radar has a higher resolution than conventional 3D radar and provides precise elevation measurements. But its point clouds are still sparse and noisy, making it challenging to meet the requirements of autonomous driving. Camera, as another commonly used sensor, can capture rich semantic information. As a result, the fusion of 4D radar and camera can provide an affordable and robust perception solution for autonomous driving systems. However, previous radar-camera fusion methods have not yet been thoroughly investigated, resulting in a large performance gap compared to LiDAR-based methods. Specifically, they ignore the feature-blurring problem and do not deeply interact with image semantic information. To this end, we present a simple but effective multi-stage sampling fusion (MSSF) network based on 4D radar and camera. On the one hand, we design a fusion block that can deeply interact point cloud features with image features, and can be applied to commonly used single-modal backbones in a plug-and-play manner. The fusion block encompasses two types, namely, simple feature fusion (SFF) and multiscale deformable feature fusion (MSDFF). The SFF is easy to implement, while the MSDFF has stronger fusion abilities. On the other hand, we propose a semantic-guided head to perform foreground-background segmentation on voxels with voxel feature re-weighting, further alleviating the problem of feature blurring. Extensive experiments on the View-of-Delft (VoD) and TJ4DRadset datasets demonstrate the effectiveness of our MSSF. Notably, compared to state-of-the-art methods, MSSF achieves a 7.0% and 4.0% improvement in 3D mean average precision on the VoD and TJ4DRadSet datasets, respectively. It even surpasses classical LiDAR-based methods on the VoD dataset.