 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX2HDR: HDR Image Generation in a Perceptually Uniform Space
Feb 04, 2026High-dynamic-range (HDR) formats and displays are becoming increasingly prevalent, yet state-of-the-art image generators (e.g., Stable Diffusion and FLUX) typically remain limited to low-dynamic-range (LDR) output due to the lack of large-scale HDR training data. In this work, we show that existing pretrained diffusion models can be easily adapted to HDR generation without retraining from scratch. A key challenge is that HDR images are natively represented in linear RGB, whose intensity and color statistics differ substantially from those of sRGB-encoded LDR images. This gap, however, can be effectively bridged by converting HDR inputs into perceptually uniform encodings (e.g., using PU21 or PQ). Empirically, we find that LDR-pretrained variational autoencoders (VAEs) reconstruct PU21-encoded HDR inputs with fidelity comparable to LDR data, whereas linear RGB inputs cause severe degradations. Motivated by this finding, we describe an efficient adaptation strategy that freezes the VAE and finetunes only the denoiser via low-rank adaptation in a perceptually uniform space. This results in a unified computational method that supports both text-to-HDR synthesis and single-image RAW-to-HDR reconstruction. Experiments demonstrate that our perceptually encoded adaptation consistently improves perceptual fidelity, text-image alignment, and effective dynamic range, relative to previous techniques.
elaTCSF: A Temporal Contrast Sensitivity Function for Flicker Detection and Modeling Variable Refresh Rate Flicker
Mar 21, 2025

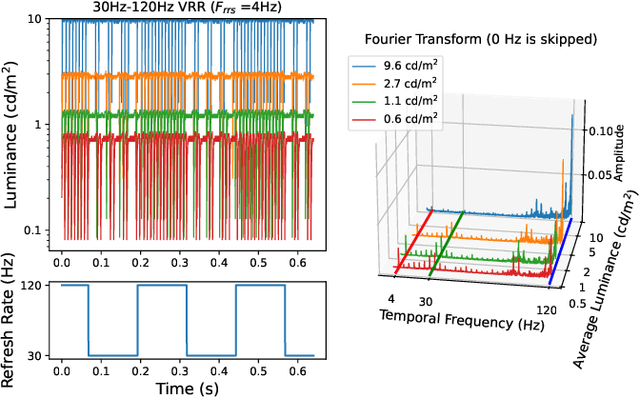

The perception of flicker has been a prominent concern in illumination and electronic display fields for over a century. Traditional approaches often rely on Critical Flicker Frequency (CFF), primarily suited for high-contrast (full-on, full-off) flicker. To tackle varying contrast flicker, the International Committee for Display Metrology (ICDM) introduced a Temporal Contrast Sensitivity Function TCSF$_{IDMS}$ within the Information Display Measurements Standard (IDMS). Nevertheless, this standard overlooks crucial parameters: luminance, eccentricity, and area. Existing models incorporating these parameters are inadequate for flicker detection, especially at low spatial frequencies. To address these limitations, we extend the TCSF$_{IDMS}$ and combine it with a new spatial probability summation model to incorporate the effects of luminance, eccentricity, and area (elaTCSF). We train the elaTCSF on various flicker detection datasets and establish the first variable refresh rate flicker detection dataset for further verification. Additionally, we contribute to resolving a longstanding debate on whether the flicker is more visible in peripheral vision. We demonstrate how elaTCSF can be used to predict flicker due to low-persistence in VR headsets, identify flicker-free VRR operational ranges, and determine flicker sensitivity in lighting design.
Do image and video quality metrics model low-level human vision?
Mar 20, 2025Image and video quality metrics, such as SSIM, LPIPS, and VMAF, are aimed to predict the perceived quality of the evaluated content and are often claimed to be "perceptual". Yet, few metrics directly model human visual perception, and most rely on hand-crafted formulas or training datasets to achieve alignment with perceptual data. In this paper, we propose a set of tests for full-reference quality metrics that examine their ability to model several aspects of low-level human vision: contrast sensitivity, contrast masking, and contrast matching. The tests are meant to provide additional scrutiny for newly proposed metrics. We use our tests to analyze 33 existing image and video quality metrics and find their strengths and weaknesses, such as the ability of LPIPS and MS-SSIM to predict contrast masking and poor performance of VMAF in this task. We further find that the popular SSIM metric overemphasizes differences in high spatial frequencies, but its multi-scale counterpart, MS-SSIM, addresses this shortcoming. Such findings cannot be easily made using existing evaluation protocols.
Resolution limit of the eye: how many pixels can we see?
Oct 08, 2024As large engineering efforts go towards improving the resolution of mobile, AR and VR displays, it is important to know the maximum resolution at which further improvements bring no noticeable benefit. This limit is often referred to as the "retinal resolution", although the limiting factor may not necessarily be attributed to the retina. To determine the ultimate resolution at which an image appears sharp to our eyes with no perceivable blur, we created an experimental setup with a sliding display, which allows for continuous control of the resolution. The lack of such control was the main limitation of the previous studies. We measure achromatic (black-white) and chromatic (red-green and yellow-violet) resolution limits for foveal vision, and at two eccentricities (10 and 20 deg). Our results demonstrate that the resolution limit is higher than what was previously believed, reaching 94 pixels-per-degree (ppd) for foveal achromatic vision, 89 ppd for red-green patterns, and 53 ppd for yellow-violet patterns. We also observe a much larger drop in the resolution limit for chromatic patterns (red-green and yellow-violet) than for achromatic. Our results set the north star for display development, with implications for future imaging, rendering and video coding technologies.
Robust estimation of exposure ratios in multi-exposure image stacks
Aug 12, 2023Merging multi-exposure image stacks into a high dynamic range (HDR) image requires knowledge of accurate exposure times. When exposure times are inaccurate, for example, when they are extracted from a camera's EXIF metadata, the reconstructed HDR images reveal banding artifacts at smooth gradients. To remedy this, we propose to estimate exposure ratios directly from the input images. We derive the exposure time estimation as an optimization problem, in which pixels are selected from pairs of exposures to minimize estimation error caused by camera noise. When pixel values are represented in the logarithmic domain, the problem can be solved efficiently using a linear solver. We demonstrate that the estimation can be easily made robust to pixel misalignment caused by camera or object motion by collecting pixels from multiple spatial tiles. The proposed automatic exposure estimation and alignment eliminates banding artifacts in popular datasets and is essential for applications that require physically accurate reconstructions, such as measuring the modulation transfer function of a display. The code for the method is available.
* 11 pages, 11 figures, journal
Single-frame Regularization for Temporally Stable CNNs
Feb 27, 2019

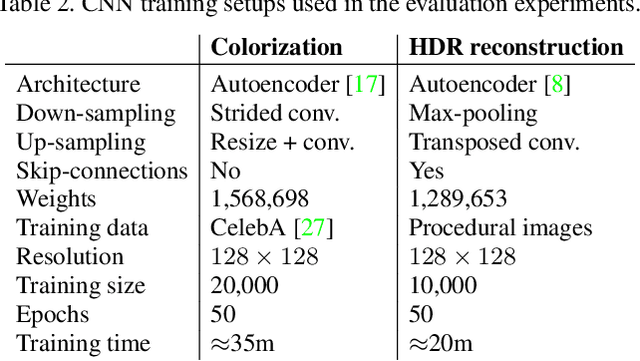

Convolutional neural networks (CNNs) can model complicated non-linear relations between images. However, they are notoriously sensitive to small changes in the input. Most CNNs trained to describe image-to-image mappings generate temporally unstable results when applied to video sequences, leading to flickering artifacts and other inconsistencies over time. In order to use CNNs for video material, previous methods have relied on estimating dense frame-to-frame motion information (optical flow) in the training and/or the inference phase, or by exploring recurrent learning structures. We take a different approach to the problem, posing temporal stability as a regularization of the cost function. The regularization is formulated to account for different types of motion that can occur between frames, so that temporally stable CNNs can be trained without the need for video material or expensive motion estimation. The training can be performed as a fine-tuning operation, without architectural modifications of the CNN. Our evaluation shows that the training strategy leads to large improvements in temporal smoothness. Moreover, in situations where the quantity of training data is limited, the regularization can help in boosting the generalization performance to a much larger extent than what is possible with na\"ive augmentation strategies.
HDR image reconstruction from a single exposure using deep CNNs
Oct 20, 2017
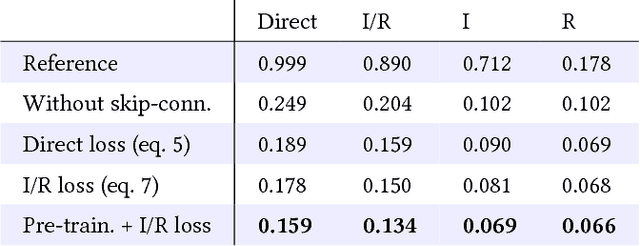
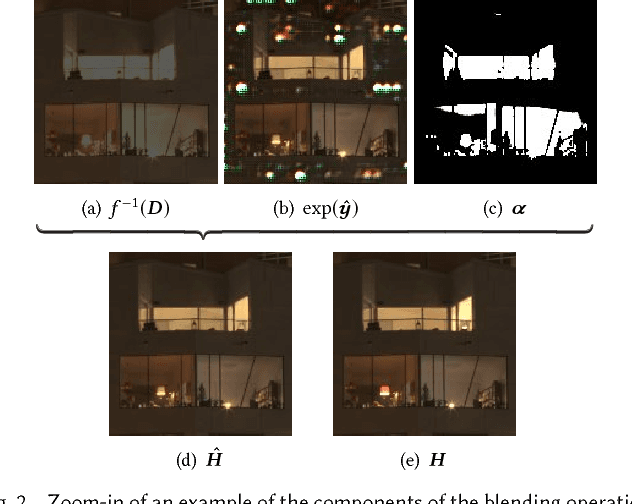
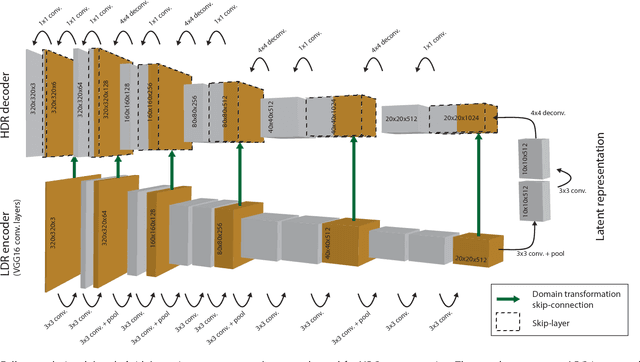
Camera sensors can only capture a limited range of luminance simultaneously, and in order to create high dynamic range (HDR) images a set of different exposures are typically combined. In this paper we address the problem of predicting information that have been lost in saturated image areas, in order to enable HDR reconstruction from a single exposure. We show that this problem is well-suited for deep learning algorithms, and propose a deep convolutional neural network (CNN) that is specifically designed taking into account the challenges in predicting HDR values. To train the CNN we gather a large dataset of HDR images, which we augment by simulating sensor saturation for a range of cameras. To further boost robustness, we pre-train the CNN on a simulated HDR dataset created from a subset of the MIT Places database. We demonstrate that our approach can reconstruct high-resolution visually convincing HDR results in a wide range of situations, and that it generalizes well to reconstruction of images captured with arbitrary and low-end cameras that use unknown camera response functions and post-processing. Furthermore, we compare to existing methods for HDR expansion, and show high quality results also for image based lighting. Finally, we evaluate the results in a subjective experiment performed on an HDR display. This shows that the reconstructed HDR images are visually convincing, with large improvements as compared to existing methods.
* 15 pages, 19 figures, Siggraph Asia 2017. Project webpage located at http://hdrv.org/hdrcnn/ where paper with high quality images is available, as well as supplementary material (document, images, video and source code)
Towards a quality metric for dense light fields
Apr 25, 2017

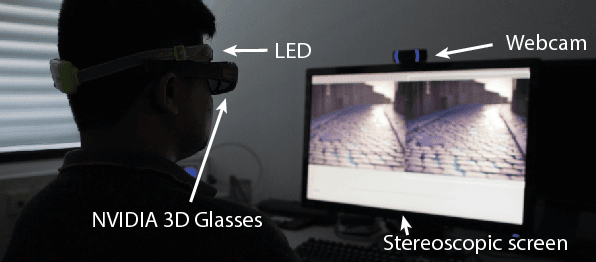
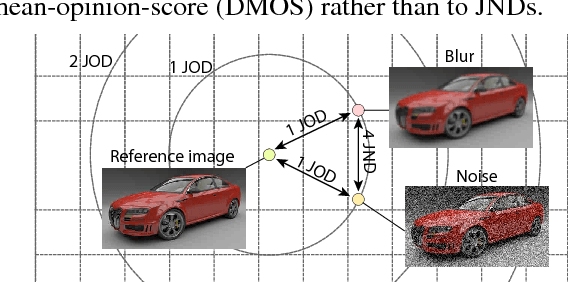
Light fields become a popular representation of three dimensional scenes, and there is interest in their processing, resampling, and compression. As those operations often result in loss of quality, there is a need to quantify it. In this work, we collect a new dataset of dense reference and distorted light fields as well as the corresponding quality scores which are scaled in perceptual units. The scores were acquired in a subjective experiment using an interactive light-field viewing setup. The dataset contains typical artifacts that occur in light-field processing chain due to light-field reconstruction, multi-view compression, and limitations of automultiscopic displays. We test a number of existing objective quality metrics to determine how well they can predict the quality of light fields. We find that the existing image quality metrics provide good measures of light-field quality, but require dense reference light- fields for optimal performance. For more complex tasks of comparing two distorted light fields, their performance drops significantly, which reveals the need for new, light-field-specific metrics.