 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHOrD: Generation of Collision-Free, House-Scale, and Organized Digital Twins for 3D Indoor Scenes with Controllable Floor Plans and Optimal Layouts
Mar 15, 2025We introduce CHOrD, a novel framework for scalable synthesis of 3D indoor scenes, designed to create house-scale, collision-free, and hierarchically structured indoor digital twins. In contrast to existing methods that directly synthesize the scene layout as a scene graph or object list, CHOrD incorporates a 2D image-based intermediate layout representation, enabling effective prevention of collision artifacts by successfully capturing them as out-of-distribution (OOD) scenarios during generation. Furthermore, unlike existing methods, CHOrD is capable of generating scene layouts that adhere to complex floor plans with multi-modal controls, enabling the creation of coherent, house-wide layouts robust to both geometric and semantic variations in room structures. Additionally, we propose a novel dataset with expanded coverage of household items and room configurations, as well as significantly improved data quality. CHOrD demonstrates state-of-the-art performance on both the 3D-FRONT and our proposed datasets, delivering photorealistic, spatially coherent indoor scene synthesis adaptable to arbitrary floor plan variations.
ColorVideoVDP: A visual difference predictor for image, video and display distortions
Jan 21, 2024



ColorVideoVDP is a video and image quality metric that models spatial and temporal aspects of vision, for both luminance and color. The metric is built on novel psychophysical models of chromatic spatiotemporal contrast sensitivity and cross-channel contrast masking. It accounts for the viewing conditions, geometric, and photometric characteristics of the display. It was trained to predict common video streaming distortions (e.g. video compression, rescaling, and transmission errors), and also 8 new distortion types related to AR/VR displays (e.g. light source and waveguide non-uniformities). To address the latter application, we collected our novel XR-Display-Artifact-Video quality dataset (XR-DAVID), comprised of 336 distorted videos. Extensive testing on XR-DAVID, as well as several datasets from the literature, indicate a significant gain in prediction performance compared to existing metrics. ColorVideoVDP opens the doors to many novel applications which require the joint automated spatiotemporal assessment of luminance and color distortions, including video streaming, display specification and design, visual comparison of results, and perceptually-guided quality optimization.
FrePolad: Frequency-Rectified Point Latent Diffusion for Point Cloud Generation
Nov 20, 2023



We propose FrePolad: frequency-rectified point latent diffusion, a point cloud generation pipeline integrating a variational autoencoder (VAE) with a denoising diffusion probabilistic model (DDPM) for the latent distribution. FrePolad simultaneously achieves high quality, diversity, and flexibility in point cloud cardinality for generation tasks while maintaining high computational efficiency. The improvement in generation quality and diversity is achieved through (1) a novel frequency rectification module via spherical harmonics designed to retain high-frequency content while learning the point cloud distribution; and (2) a latent DDPM to learn the regularized yet complex latent distribution. In addition, FrePolad supports variable point cloud cardinality by formulating the sampling of points as conditional distributions over a latent shape distribution. Finally, the low-dimensional latent space encoded by the VAE contributes to FrePolad's fast and scalable sampling. Our quantitative and qualitative results demonstrate the state-of-the-art performance of FrePolad in terms of quality, diversity, and computational efficiency.
Robust estimation of exposure ratios in multi-exposure image stacks
Aug 12, 2023Merging multi-exposure image stacks into a high dynamic range (HDR) image requires knowledge of accurate exposure times. When exposure times are inaccurate, for example, when they are extracted from a camera's EXIF metadata, the reconstructed HDR images reveal banding artifacts at smooth gradients. To remedy this, we propose to estimate exposure ratios directly from the input images. We derive the exposure time estimation as an optimization problem, in which pixels are selected from pairs of exposures to minimize estimation error caused by camera noise. When pixel values are represented in the logarithmic domain, the problem can be solved efficiently using a linear solver. We demonstrate that the estimation can be easily made robust to pixel misalignment caused by camera or object motion by collecting pixels from multiple spatial tiles. The proposed automatic exposure estimation and alignment eliminates banding artifacts in popular datasets and is essential for applications that require physically accurate reconstructions, such as measuring the modulation transfer function of a display. The code for the method is available.
* 11 pages, 11 figures, journal
Neural Fields with Hard Constraints of Arbitrary Differential Order
Jun 15, 2023



While deep learning techniques have become extremely popular for solving a broad range of optimization problems, methods to enforce hard constraints during optimization, particularly on deep neural networks, remain underdeveloped. Inspired by the rich literature on meshless interpolation and its extension to spectral collocation methods in scientific computing, we develop a series of approaches for enforcing hard constraints on neural fields, which we refer to as \emph{Constrained Neural Fields} (CNF). The constraints can be specified as a linear operator applied to the neural field and its derivatives. We also design specific model representations and training strategies for problems where standard models may encounter difficulties, such as conditioning of the system, memory consumption, and capacity of the network when being constrained. Our approaches are demonstrated in a wide range of real-world applications. Additionally, we develop a framework that enables highly efficient model and constraint specification, which can be readily applied to any downstream task where hard constraints need to be explicitly satisfied during optimization.
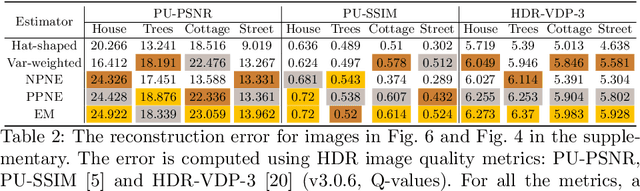
HDR-VDP-3: A multi-metric for predicting image differences, quality and contrast distortions in high dynamic range and regular content
Apr 26, 2023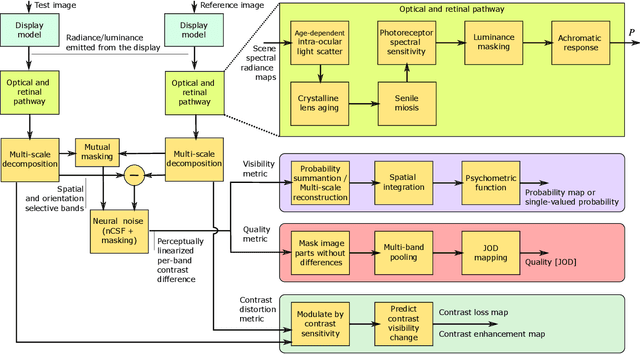
High-Dynamic-Range Visual-Difference-Predictor version 3, or HDR-VDP-3, is a visual metric that can fulfill several tasks, such as full-reference image/video quality assessment, prediction of visual differences between a pair of images, or prediction of contrast distortions. Here we present a high-level overview of the metric, position it with respect to related work, explain the main differences compared to version 2.2, and describe how the metric was adapted for the HDR Video Quality Measurement Grand Challenge 2023.
Perceptual Quality Assessment of NeRF and Neural View Synthesis Methods for Front-Facing Views
Apr 02, 2023Neural view synthesis (NVS) is one of the most successful techniques for synthesizing free viewpoint videos, capable of achieving high fidelity from only a sparse set of captured images. This success has led to many variants of the techniques, each evaluated on a set of test views typically using image quality metrics such as PSNR, SSIM, or LPIPS. There has been a lack of research on how NVS methods perform with respect to perceived video quality. We present the first study on perceptual evaluation of NVS and NeRF variants. For this study, we collected two datasets of scenes captured in a controlled lab environment as well as in-the-wild. In contrast to existing datasets, these scenes come with reference video sequences, allowing us to test for temporal artifacts and subtle distortions that are easily overlooked when viewing only static images. We measured the quality of videos synthesized by several NVS methods in a well-controlled perceptual quality assessment experiment as well as with many existing state-of-the-art image/video quality metrics. We present a detailed analysis of the results and recommendations for dataset and metric selection for NVS evaluation.
Distilling Style from Image Pairs for Global Forward and Inverse Tone Mapping
Oct 04, 2022
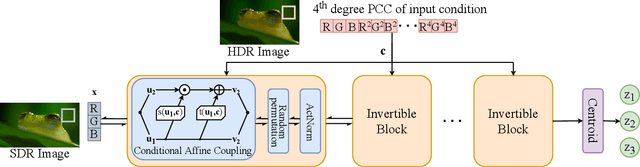


Many image enhancement or editing operations, such as forward and inverse tone mapping or color grading, do not have a unique solution, but instead a range of solutions, each representing a different style. Despite this, existing learning-based methods attempt to learn a unique mapping, disregarding this style. In this work, we show that information about the style can be distilled from collections of image pairs and encoded into a 2- or 3-dimensional vector. This gives us not only an efficient representation but also an interpretable latent space for editing the image style. We represent the global color mapping between a pair of images as a custom normalizing flow, conditioned on a polynomial basis of the pixel color. We show that such a network is more effective than PCA or VAE at encoding image style in low-dimensional space and lets us obtain an accuracy close to 40 dB, which is about 7-10 dB improvement over the state-of-the-art methods.
How to cheat with metrics in single-image HDR reconstruction
Aug 19, 2021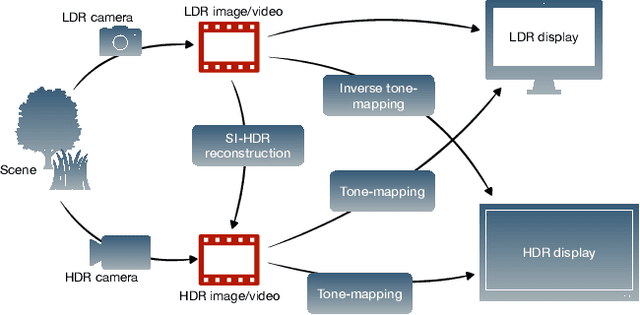
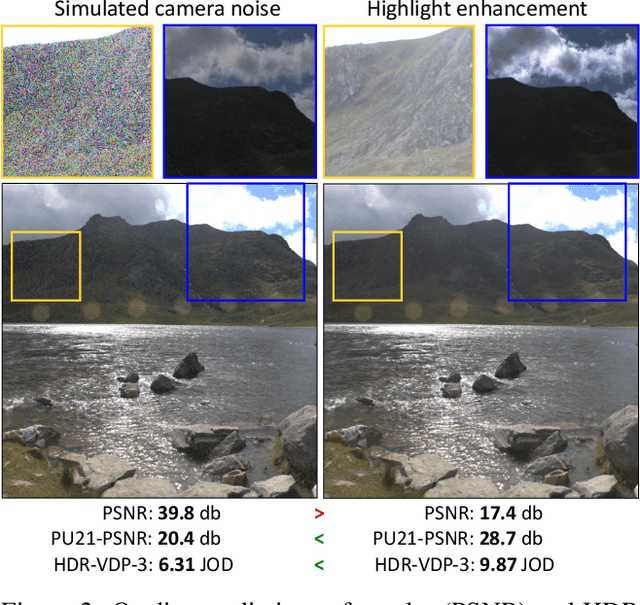
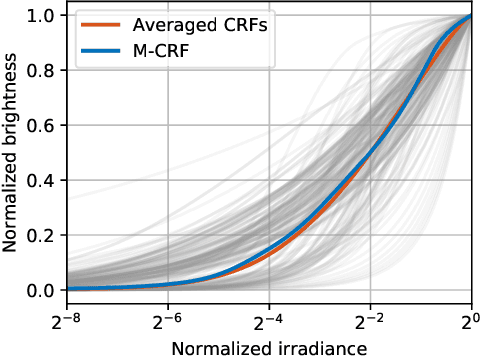
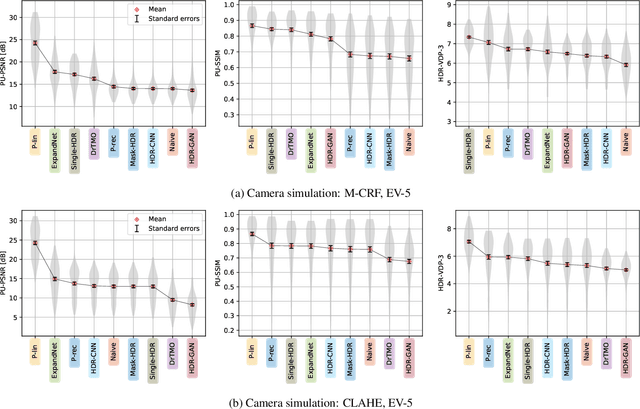
Single-image high dynamic range (SI-HDR) reconstruction has recently emerged as a problem well-suited for deep learning methods. Each successive technique demonstrates an improvement over existing methods by reporting higher image quality scores. This paper, however, highlights that such improvements in objective metrics do not necessarily translate to visually superior images. The first problem is the use of disparate evaluation conditions in terms of data and metric parameters, calling for a standardized protocol to make it possible to compare between papers. The second problem, which forms the main focus of this paper, is the inherent difficulty in evaluating SI-HDR reconstructions since certain aspects of the reconstruction problem dominate objective differences, thereby introducing a bias. Here, we reproduce a typical evaluation using existing as well as simulated SI-HDR methods to demonstrate how different aspects of the problem affect objective quality metrics. Surprisingly, we found that methods that do not even reconstruct HDR information can compete with state-of-the-art deep learning methods. We show how such results are not representative of the perceived quality and that SI-HDR reconstruction needs better evaluation protocols.
Noise-Aware Merging of High Dynamic Range Image Stacks without Camera Calibration
Sep 16, 2020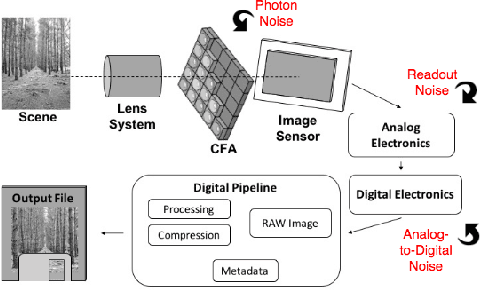
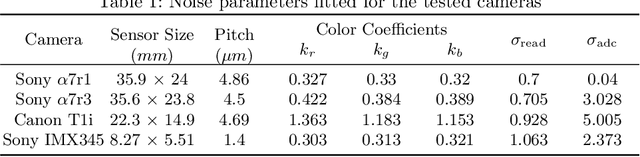
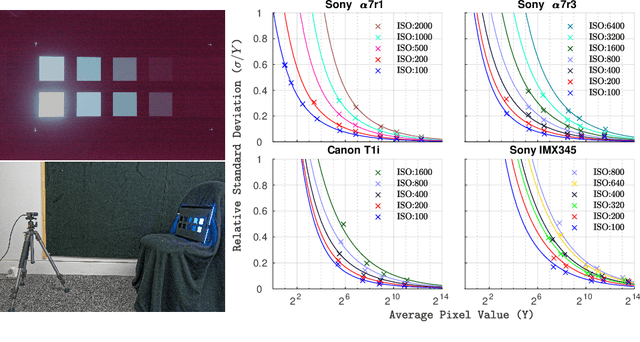
A near-optimal reconstruction of the radiance of a High Dynamic Range scene from an exposure stack can be obtained by modeling the camera noise distribution. The latent radiance is then estimated using Maximum Likelihood Estimation. But this requires a well-calibrated noise model of the camera, which is difficult to obtain in practice. We show that an unbiased estimation of comparable variance can be obtained with a simpler Poisson noise estimator, which does not require the knowledge of camera-specific noise parameters. We demonstrate this empirically for four different cameras, ranging from a smartphone camera to a full-frame mirrorless camera. Our experimental results are consistent for simulated as well as real images, and across different camera settings.