 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrePolad: Frequency-Rectified Point Latent Diffusion for Point Cloud Generation
Nov 20, 2023



We propose FrePolad: frequency-rectified point latent diffusion, a point cloud generation pipeline integrating a variational autoencoder (VAE) with a denoising diffusion probabilistic model (DDPM) for the latent distribution. FrePolad simultaneously achieves high quality, diversity, and flexibility in point cloud cardinality for generation tasks while maintaining high computational efficiency. The improvement in generation quality and diversity is achieved through (1) a novel frequency rectification module via spherical harmonics designed to retain high-frequency content while learning the point cloud distribution; and (2) a latent DDPM to learn the regularized yet complex latent distribution. In addition, FrePolad supports variable point cloud cardinality by formulating the sampling of points as conditional distributions over a latent shape distribution. Finally, the low-dimensional latent space encoded by the VAE contributes to FrePolad's fast and scalable sampling. Our quantitative and qualitative results demonstrate the state-of-the-art performance of FrePolad in terms of quality, diversity, and computational efficiency.
Perceptual Quality Assessment of NeRF and Neural View Synthesis Methods for Front-Facing Views
Apr 02, 2023Neural view synthesis (NVS) is one of the most successful techniques for synthesizing free viewpoint videos, capable of achieving high fidelity from only a sparse set of captured images. This success has led to many variants of the techniques, each evaluated on a set of test views typically using image quality metrics such as PSNR, SSIM, or LPIPS. There has been a lack of research on how NVS methods perform with respect to perceived video quality. We present the first study on perceptual evaluation of NVS and NeRF variants. For this study, we collected two datasets of scenes captured in a controlled lab environment as well as in-the-wild. In contrast to existing datasets, these scenes come with reference video sequences, allowing us to test for temporal artifacts and subtle distortions that are easily overlooked when viewing only static images. We measured the quality of videos synthesized by several NVS methods in a well-controlled perceptual quality assessment experiment as well as with many existing state-of-the-art image/video quality metrics. We present a detailed analysis of the results and recommendations for dataset and metric selection for NVS evaluation.
Scale-recurrent Network for Deep Image Deblurring
Feb 06, 2018
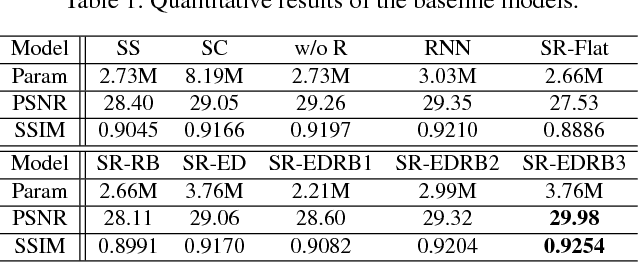
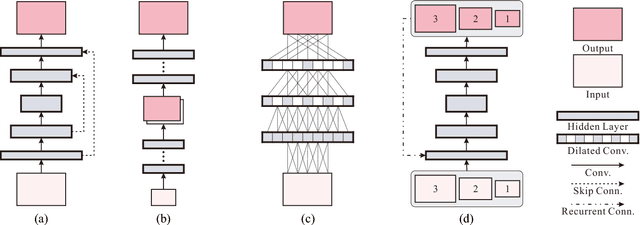
In single image deblurring, the "coarse-to-fine" scheme, i.e. gradually restoring the sharp image on different resolutions in a pyramid, is very successful in both traditional optimization-based methods and recent neural-network-based approaches. In this paper, we investigate this strategy and propose a Scale-recurrent Network (SRN-DeblurNet) for this deblurring task. Compared with the many recent learning-based approaches in [25], it has a simpler network structure, a smaller number of parameters and is easier to train. We evaluate our method on large-scale deblurring datasets with complex motion. Results show that our method can produce better quality results than state-of-the-arts, both quantitatively and qualitatively.
Detail-revealing Deep Video Super-resolution
Apr 10, 2017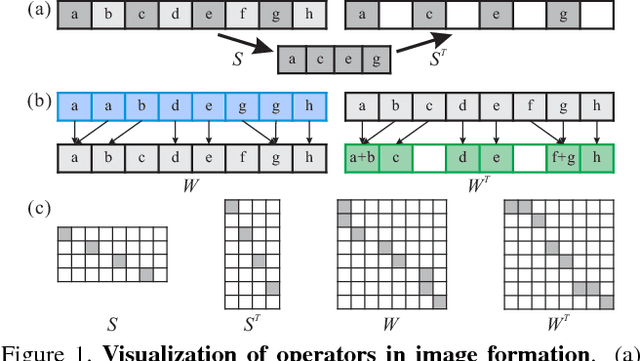

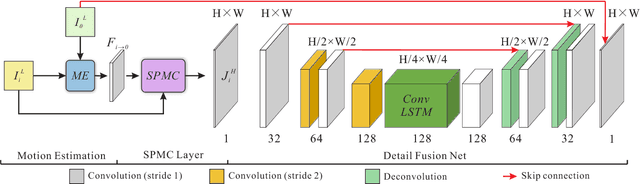
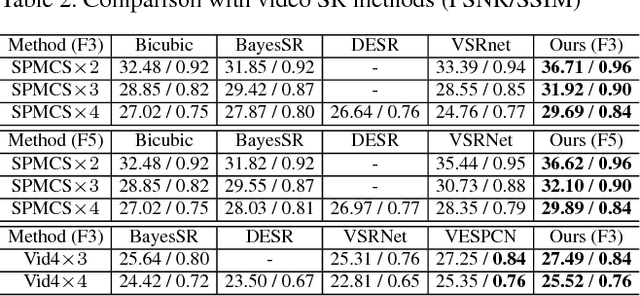
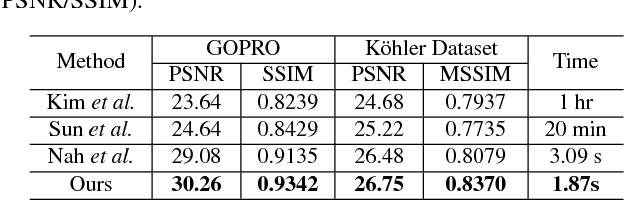
Previous CNN-based video super-resolution approaches need to align multiple frames to the reference. In this paper, we show that proper frame alignment and motion compensation is crucial for achieving high quality results. We accordingly propose a `sub-pixel motion compensation' (SPMC) layer in a CNN framework. Analysis and experiments show the suitability of this layer in video SR. The final end-to-end, scalable CNN framework effectively incorporates the SPMC layer and fuses multiple frames to reveal image details. Our implementation can generate visually and quantitatively high-quality results, superior to current state-of-the-arts, without the need of parameter tuning.
High-Quality Correspondence and Segmentation Estimation for Dual-Lens Smart-Phone Portraits
Apr 07, 2017
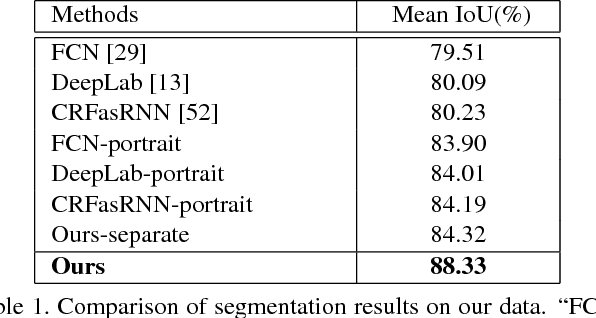

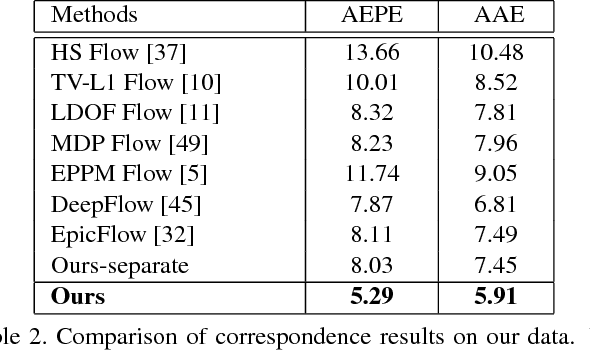
Estimating correspondence between two images and extracting the foreground object are two challenges in computer vision. With dual-lens smart phones, such as iPhone 7Plus and Huawei P9, coming into the market, two images of slightly different views provide us new information to unify the two topics. We propose a joint method to tackle them simultaneously via a joint fully connected conditional random field (CRF) framework. The regional correspondence is used to handle textureless regions in matching and make our CRF system computationally efficient. Our method is evaluated over 2,000 new image pairs, and produces promising results on challenging portrait images.