 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Style from Image Pairs for Global Forward and Inverse Tone Mapping
Oct 04, 2022
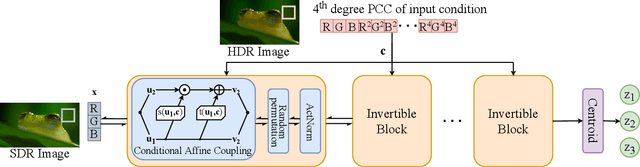


Many image enhancement or editing operations, such as forward and inverse tone mapping or color grading, do not have a unique solution, but instead a range of solutions, each representing a different style. Despite this, existing learning-based methods attempt to learn a unique mapping, disregarding this style. In this work, we show that information about the style can be distilled from collections of image pairs and encoded into a 2- or 3-dimensional vector. This gives us not only an efficient representation but also an interpretable latent space for editing the image style. We represent the global color mapping between a pair of images as a custom normalizing flow, conditioned on a polynomial basis of the pixel color. We show that such a network is more effective than PCA or VAE at encoding image style in low-dimensional space and lets us obtain an accuracy close to 40 dB, which is about 7-10 dB improvement over the state-of-the-art methods.
Training a Better Loss Function for Image Restoration
Mar 26, 2021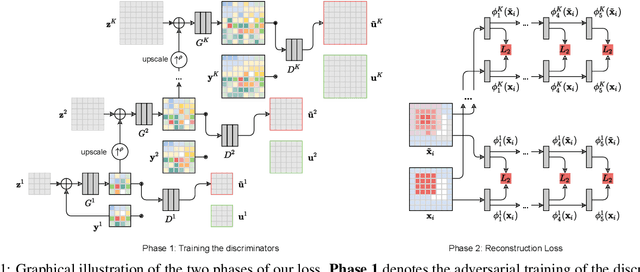
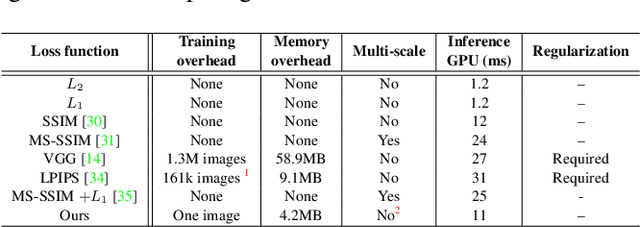
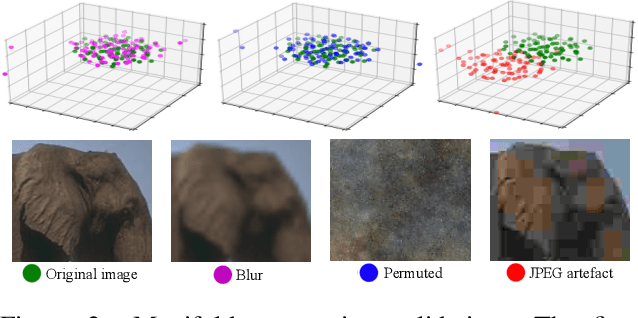
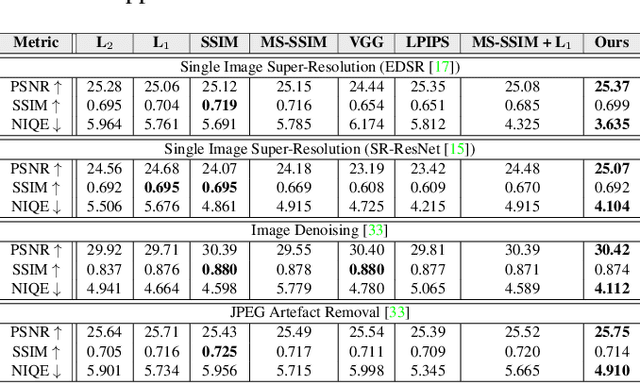
Central to the application of neural networks in image restoration problems, such as single image super resolution, is the choice of a loss function that encourages natural and perceptually pleasing results. A popular choice for a loss function is a pre-trained network, such as VGG and LPIPS, which is used as a feature extractor for computing the difference between restored and reference images. However, such an approach has multiple drawbacks: it is computationally expensive, requires regularization and hyper-parameter tuning, and involves a large network trained on an unrelated task. In this work, we explore the question of what makes a good loss function for an image restoration task. First, we observe that a single natural image is sufficient to train a lightweight feature extractor that outperforms state-of-the-art loss functions in single image super resolution, denoising, and JPEG artefact removal. We propose a novel Multi-Scale Discriminative Feature (MDF) loss comprising a series of discriminators, trained to penalize errors introduced by a generator. Second, we show that an effective loss function does not have to be a good predictor of perceived image quality, but instead needs to be specialized in identifying the distortions for a given restoration method.
Transformation Consistency Regularization- A Semi-Supervised Paradigm for Image-to-Image Translation
Jul 15, 2020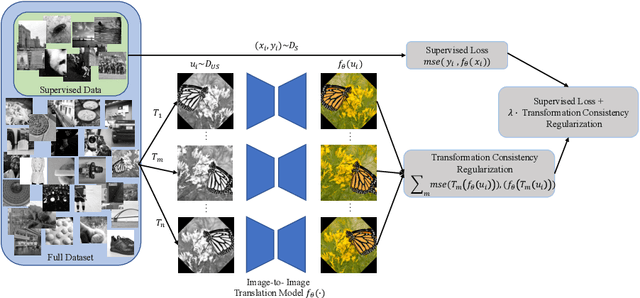
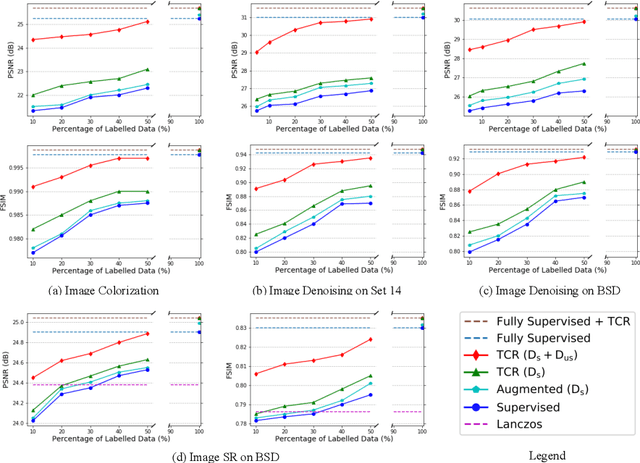

Scarcity of labeled data has motivated the development of semi-supervised learning methods, which learn from large portions of unlabeled data alongside a few labeled samples. Consistency Regularization between model's predictions under different input perturbations, particularly has shown to provide state-of-the art results in a semi-supervised framework. However, most of these method have been limited to classification and segmentation applications. We propose Transformation Consistency Regularization, which delves into a more challenging setting of image-to-image translation, which remains unexplored by semi-supervised algorithms. The method introduces a diverse set of geometric transformations and enforces the model's predictions for unlabeled data to be invariant to those transformations. We evaluate the efficacy of our algorithm on three different applications: image colorization, denoising and super-resolution. Our method is significantly data efficient, requiring only around 10 - 20% of labeled samples to achieve similar image reconstructions to its fully-supervised counterpart. Furthermore, we show the effectiveness of our method in video processing applications, where knowledge from a few frames can be leveraged to enhance the quality of the rest of the movie.
Adversarial Defense by Restricting the Hidden Space of Deep Neural Networks
Apr 07, 2019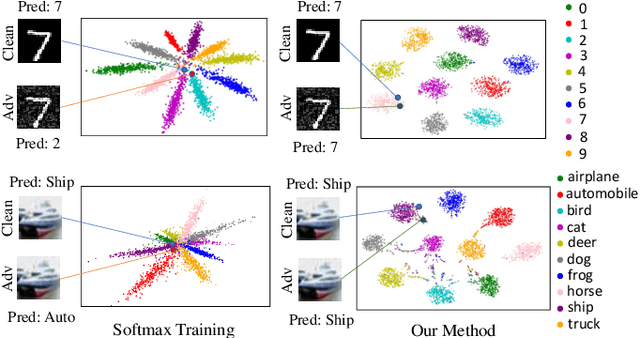
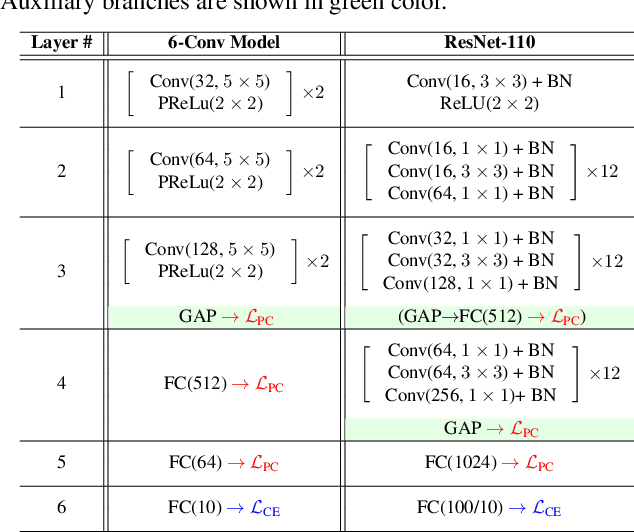
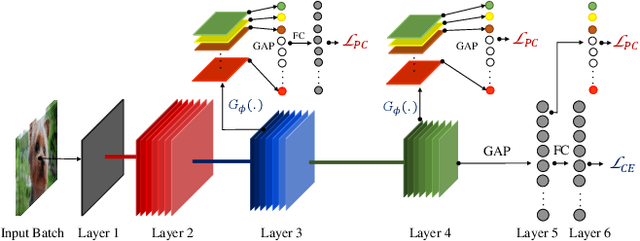
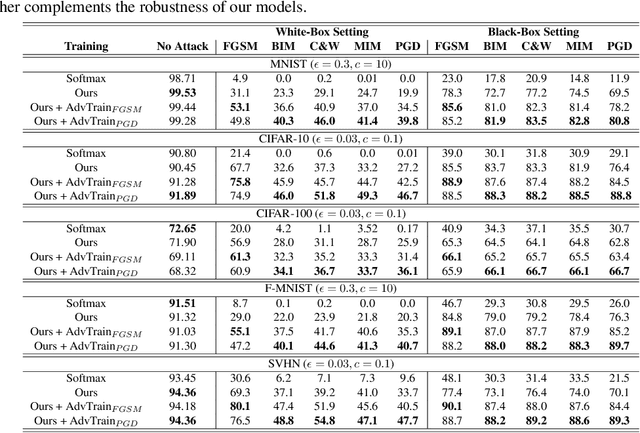
Deep neural networks are vulnerable to adversarial attacks, which can fool them by adding minuscule perturbations to the input images. The robustness of existing defenses suffers greatly under white-box attack settings, where an adversary has full knowledge about the network and can iterate several times to find strong perturbations. We observe that the main reason for the existence of such perturbations is the close proximity of different class samples in the learned feature space. This allows model decisions to be totally changed by adding an imperceptible perturbation in the inputs. To counter this, we propose to class-wise disentangle the intermediate feature representations of deep networks. Specifically, we force the features for each class to lie inside a convex polytope that is maximally separated from the polytopes of other classes. In this manner, the network is forced to learn distinct and distant decision regions for each class. We observe that this simple constraint on the features greatly enhances the robustness of learned models, even against the strongest white-box attacks, without degrading the classification performance on clean images. We report extensive evaluations in both black-box and white-box attack scenarios and show significant gains in comparison to state-of-the art defenses.
Image Super-Resolution as a Defense Against Adversarial Attacks
Jan 07, 2019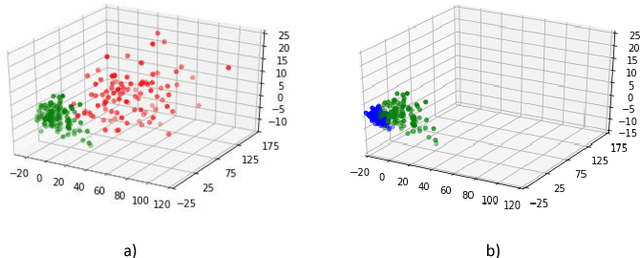
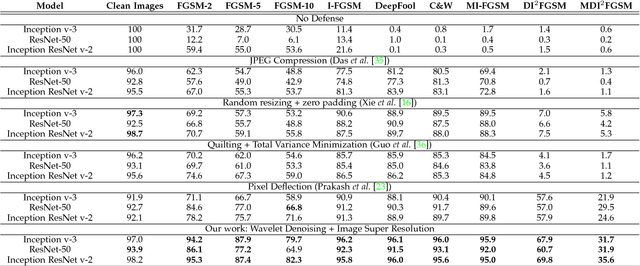
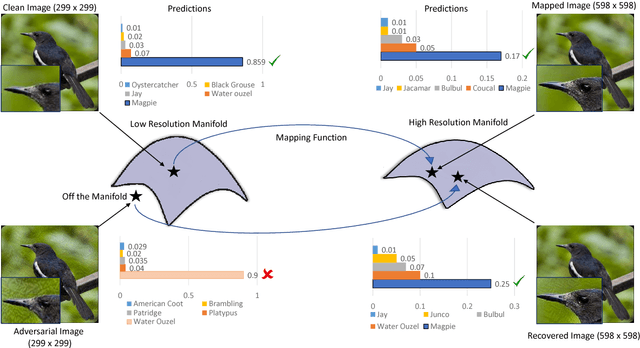
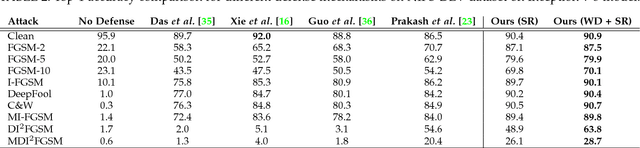
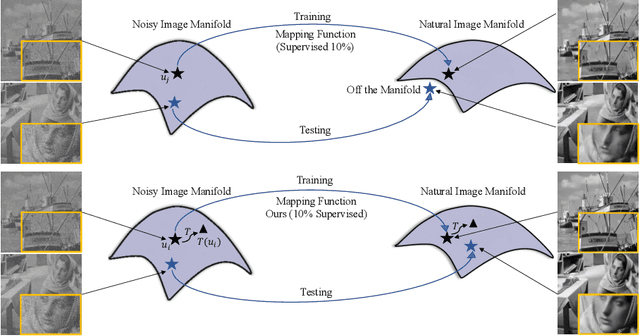
Convolutional Neural Networks have achieved significant success across multiple computer vision tasks. However, they are vulnerable to carefully crafted, human imperceptible adversarial noise patterns which constrain their deployment in critical security-sensitive systems. This paper proposes a computationally efficient image enhancement approach that provides a strong defense mechanism to effectively mitigate the effect of such adversarial perturbations. We show that the deep image restoration networks learn mapping functions that can bring \textit{off-the-manifold} adversarial samples onto the natural image manifold, thus restoring classifier beliefs towards correct classes. A distinguishing feature of our approach is that, in addition to providing robustness against attacks, it simultaneously enhances image quality and retains models performance on clean images. Furthermore, the proposed method does not modify the classifier or requires a separate mechanism to detect adversarial images. The effectiveness of the scheme has been demonstrated through extensive experiments, where it has proven a strong defense in both white-box and black-box attack settings. The proposed scheme is simple and has the following advantages: (1) it does not require any model training or parameter optimization, (2) it complements other existing defense mechanisms, (3) it is agnostic to the attacked model and attack type and (4) it provides superior performance across all popular attack algorithms. Our codes are publicly available at https://github.com/aamir-mustafa/super-resolution-adversarial-defense.
Prediction and Localization of Student Engagement in the Wild
Jun 26, 2018
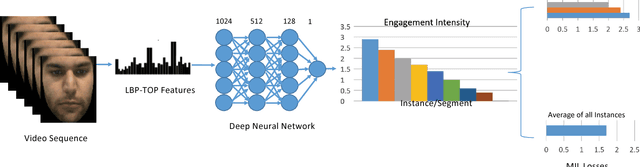
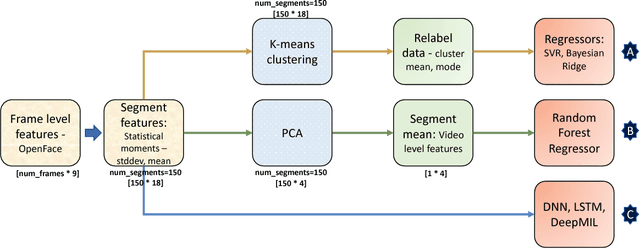

In this paper, we introduce a new dataset for student engagement detection and localization. Digital revolution has transformed the traditional teaching procedure and a result analysis of the student engagement in an e-learning environment would facilitate effective task accomplishment and learning. Well known social cues of engagement/disengagement can be inferred from facial expressions, body movements and gaze pattern. In this paper, student's response to various stimuli videos are recorded and important cues are extracted to estimate variations in engagement level. In this paper, we study the association of a subject's behavioral cues with his/her engagement level, as annotated by labelers. We then localize engaging/non-engaging parts in the stimuli videos using a deep multiple instance learning based framework, which can give useful insight into designing Massive Open Online Courses (MOOCs) video material. Recognizing the lack of any publicly available dataset in the domain of user engagement, a new `in the wild' dataset is created to study the subject engagement problem. The dataset contains 195 videos captured from 78 subjects which is about 16.5 hours of recording. We present detailed baseline results using different classifiers ranging from traditional machine learning to deep learning based approaches. The subject independent analysis is performed so that it can be generalized to new users. The problem of engagement prediction is modeled as a weakly supervised learning problem. The dataset is manually annotated by different labelers for four levels of engagement independently and the correlation studies between annotated and predicted labels of videos by different classifiers is reported. This dataset creation is an effort to facilitate research in various e-learning environments such as intelligent tutoring systems, MOOCs, and others.