 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a Better Loss Function for Image Restoration
Mar 26, 2021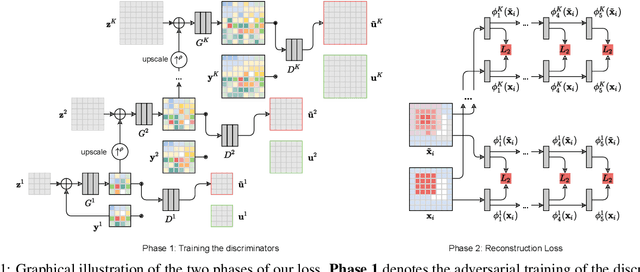
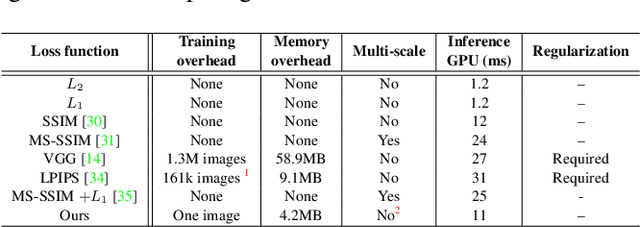
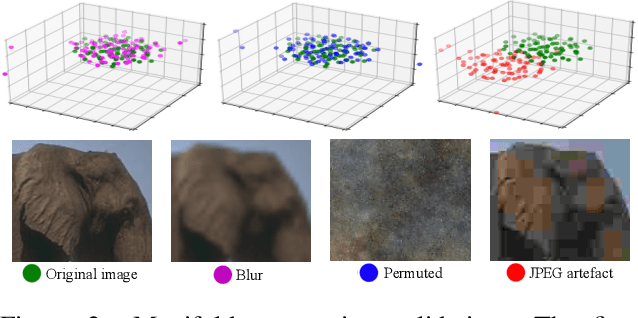
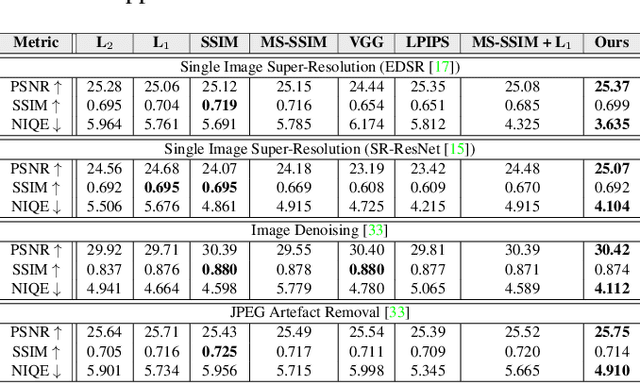
Central to the application of neural networks in image restoration problems, such as single image super resolution, is the choice of a loss function that encourages natural and perceptually pleasing results. A popular choice for a loss function is a pre-trained network, such as VGG and LPIPS, which is used as a feature extractor for computing the difference between restored and reference images. However, such an approach has multiple drawbacks: it is computationally expensive, requires regularization and hyper-parameter tuning, and involves a large network trained on an unrelated task. In this work, we explore the question of what makes a good loss function for an image restoration task. First, we observe that a single natural image is sufficient to train a lightweight feature extractor that outperforms state-of-the-art loss functions in single image super resolution, denoising, and JPEG artefact removal. We propose a novel Multi-Scale Discriminative Feature (MDF) loss comprising a series of discriminators, trained to penalize errors introduced by a generator. Second, we show that an effective loss function does not have to be a good predictor of perceived image quality, but instead needs to be specialized in identifying the distortions for a given restoration method.
Consolidated Dataset and Metrics for High-Dynamic-Range Image Quality
Dec 19, 2020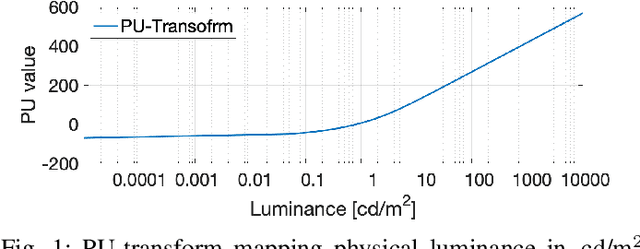
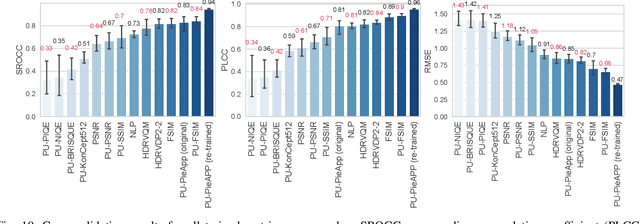
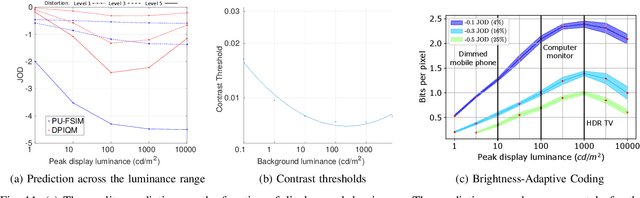
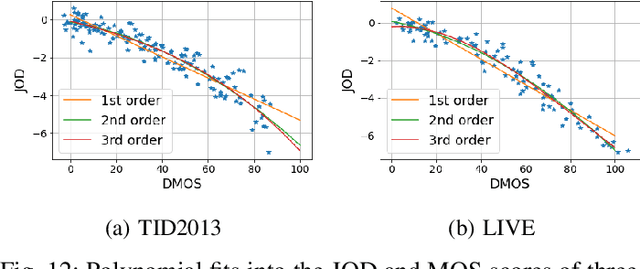
Increasing popularity of high-dynamic-range (HDR) image and video content brings the need for metrics that could predict the severity of image impairments as seen on displays of different brightness levels and dynamic range. Such metrics should be trained and validated on a sufficiently large subjective image quality dataset to ensure robust performance. As the existing HDR quality datasets are limited in size, we created a Unified Photometric Image Quality dataset (UPIQ) with over 4,000 images by realigning and merging existing HDR and standard-dynamic-range (SDR) datasets. The realigned quality scores share the same unified quality scale across all datasets. Such realignment was achieved by collecting additional cross-dataset quality comparisons and re-scaling data with a psychometric scaling method. Images in the proposed dataset are represented in absolute photometric and colorimetric units, corresponding to light emitted from a display. We use the new dataset to retrain existing HDR metrics and show that the dataset is sufficiently large for training deep architectures. We show the utility of the dataset on brightness aware image compression.
Active Sampling for Pairwise Comparisons via Approximate Message Passing and Information Gain Maximization
Apr 12, 2020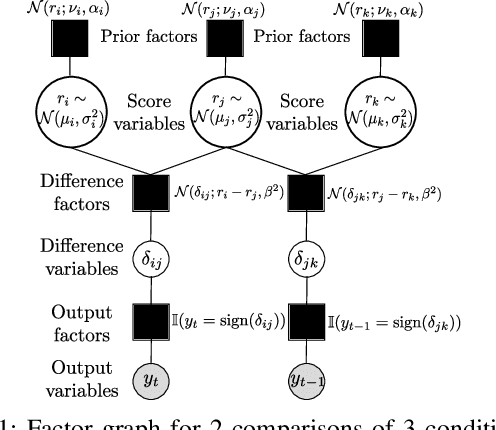
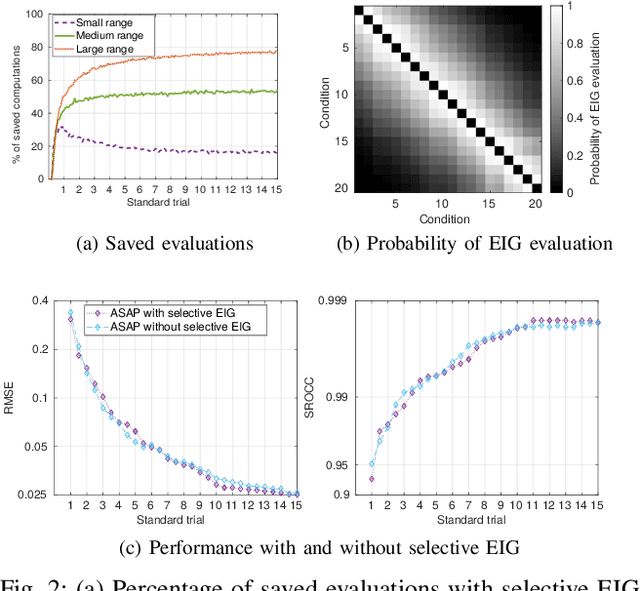
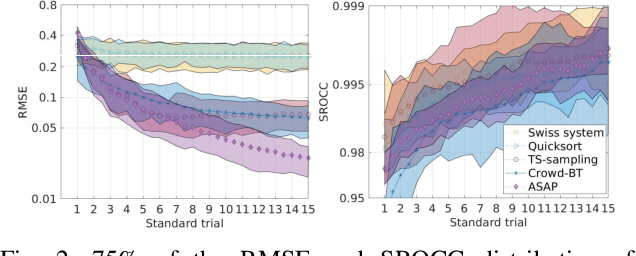
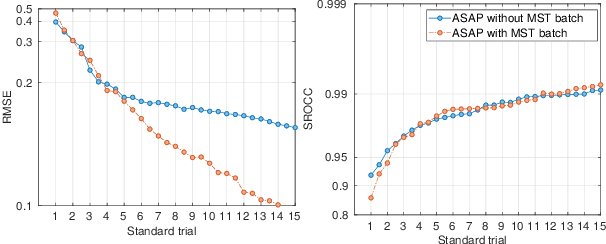
Pairwise comparison data arise in many domains with subjective assessment experiments, for example in image and video quality assessment. In these experiments observers are asked to express a preference between two conditions. However, many pairwise comparison protocols require a large number of comparisons to infer accurate scores, which may be unfeasible when each comparison is time-consuming (e.g. videos) or expensive (e.g. medical imaging). This motivates the use of an active sampling algorithm that chooses only the most informative pairs for comparison. In this paper we propose ASAP, an active sampling algorithm based on approximate message passing and expected information gain maximization. Unlike most existing methods, which rely on partial updates of the posterior distribution, we are able to perform full updates and therefore much improve the accuracy of the inferred scores. The algorithm relies on three techniques for reducing computational cost: inference based on approximate message passing, selective evaluations of the information gain, and selecting pairs in a batch that forms a minimum spanning tree of the inverse of information gain. We demonstrate, with real and synthetic data, that ASAP offers the highest accuracy of inferred scores compared to the existing methods. We also provide an open-source GPU implementation of ASAP for large-scale experiments.