 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling High-Dimensional Data With Sparse Input
Mar 14, 2023We address the problem of human-in-the-loop control for generating highly-structured data. This task is challenging because existing generative models lack an efficient interface through which users can modify the output. Users have the option to either manually explore a non-interpretable latent space, or to laboriously annotate the data with conditioning labels. To solve this, we introduce a novel framework whereby an encoder maps a sparse, human interpretable control space onto the latent space of a generative model. We apply this framework to the task of controlling prosody in text-to-speech synthesis. We propose a model, called Multiple-Instance CVAE (MICVAE), that is specifically designed to encode sparse prosodic features and output complete waveforms. We show empirically that MICVAE displays desirable qualities of a sparse human-in-the-loop control mechanism: efficiency, robustness, and faithfulness. With even a very small number of input values (~4), MICVAE enables users to improve the quality of the output significantly, in terms of listener preference (4:1).
Training a Better Loss Function for Image Restoration
Mar 26, 2021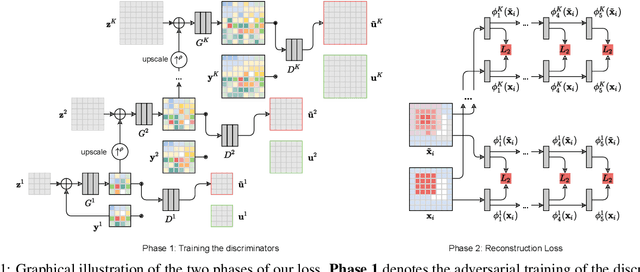
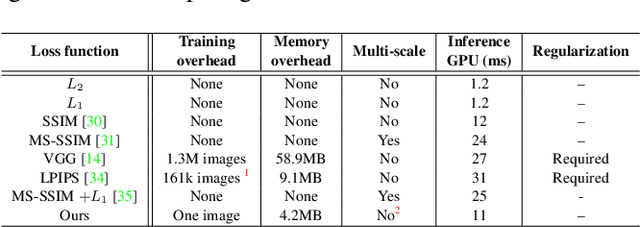
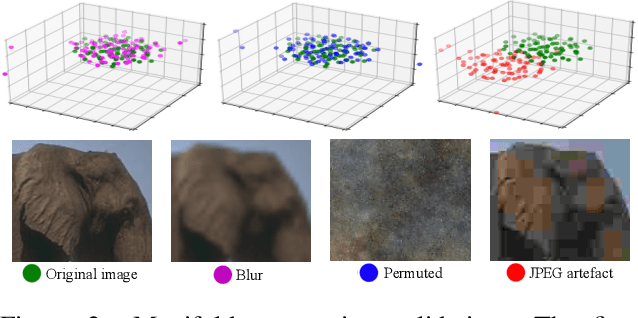
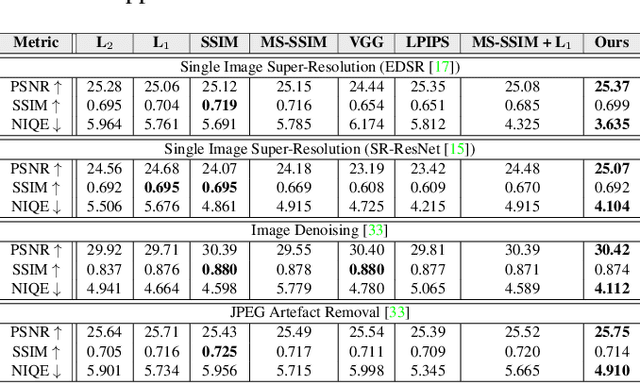
Central to the application of neural networks in image restoration problems, such as single image super resolution, is the choice of a loss function that encourages natural and perceptually pleasing results. A popular choice for a loss function is a pre-trained network, such as VGG and LPIPS, which is used as a feature extractor for computing the difference between restored and reference images. However, such an approach has multiple drawbacks: it is computationally expensive, requires regularization and hyper-parameter tuning, and involves a large network trained on an unrelated task. In this work, we explore the question of what makes a good loss function for an image restoration task. First, we observe that a single natural image is sufficient to train a lightweight feature extractor that outperforms state-of-the-art loss functions in single image super resolution, denoising, and JPEG artefact removal. We propose a novel Multi-Scale Discriminative Feature (MDF) loss comprising a series of discriminators, trained to penalize errors introduced by a generator. Second, we show that an effective loss function does not have to be a good predictor of perceived image quality, but instead needs to be specialized in identifying the distortions for a given restoration method.