 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorVideoVDP: A visual difference predictor for image, video and display distortions
Jan 21, 2024



ColorVideoVDP is a video and image quality metric that models spatial and temporal aspects of vision, for both luminance and color. The metric is built on novel psychophysical models of chromatic spatiotemporal contrast sensitivity and cross-channel contrast masking. It accounts for the viewing conditions, geometric, and photometric characteristics of the display. It was trained to predict common video streaming distortions (e.g. video compression, rescaling, and transmission errors), and also 8 new distortion types related to AR/VR displays (e.g. light source and waveguide non-uniformities). To address the latter application, we collected our novel XR-Display-Artifact-Video quality dataset (XR-DAVID), comprised of 336 distorted videos. Extensive testing on XR-DAVID, as well as several datasets from the literature, indicate a significant gain in prediction performance compared to existing metrics. ColorVideoVDP opens the doors to many novel applications which require the joint automated spatiotemporal assessment of luminance and color distortions, including video streaming, display specification and design, visual comparison of results, and perceptually-guided quality optimization.
Perceptual Assessment and Optimization of High Dynamic Range Image Rendering
Oct 23, 2023



High dynamic range (HDR) imaging has gained increasing popularity for its ability to faithfully reproduce the luminance levels in natural scenes. Accordingly, HDR image quality assessment (IQA) is crucial but has been superficially treated. The majority of existing IQA models are developed for and calibrated against low dynamic range (LDR) images, which have been shown to be poorly correlated with human perception of HDR image quality. In this work, we propose a family of HDR IQA models by transferring the recent advances in LDR IQA. The key step in our approach is to specify a simple inverse display model that decomposes an HDR image to a set of LDR images with different exposures, which will be assessed by existing LDR quality models. The local quality scores of each exposure are then aggregated with the help of a simple well-exposedness measure into a global quality score for each exposure, which will be further weighted across exposures to obtain the overall quality score. When assessing LDR images, the proposed HDR quality models reduce gracefully to the original LDR ones with the same performance. Experiments on four human-rated HDR image datasets demonstrate that our HDR quality models are consistently better than existing IQA methods, including the HDR-VDP family. Moreover, we demonstrate their strengths in perceptual optimization of HDR novel view synthesis.
HDR-VDP-3: A multi-metric for predicting image differences, quality and contrast distortions in high dynamic range and regular content
Apr 26, 2023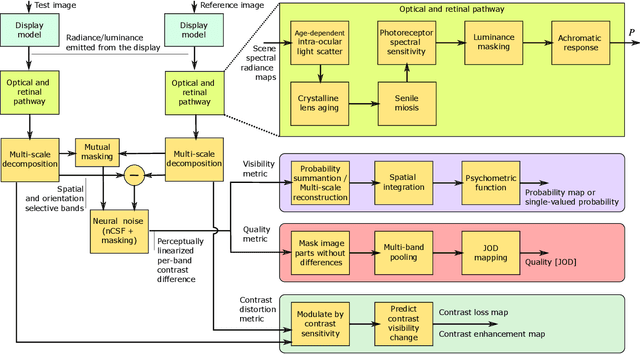
High-Dynamic-Range Visual-Difference-Predictor version 3, or HDR-VDP-3, is a visual metric that can fulfill several tasks, such as full-reference image/video quality assessment, prediction of visual differences between a pair of images, or prediction of contrast distortions. Here we present a high-level overview of the metric, position it with respect to related work, explain the main differences compared to version 2.2, and describe how the metric was adapted for the HDR Video Quality Measurement Grand Challenge 2023.
Distilling Style from Image Pairs for Global Forward and Inverse Tone Mapping
Oct 04, 2022
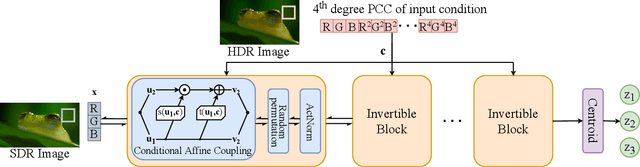


Many image enhancement or editing operations, such as forward and inverse tone mapping or color grading, do not have a unique solution, but instead a range of solutions, each representing a different style. Despite this, existing learning-based methods attempt to learn a unique mapping, disregarding this style. In this work, we show that information about the style can be distilled from collections of image pairs and encoded into a 2- or 3-dimensional vector. This gives us not only an efficient representation but also an interpretable latent space for editing the image style. We represent the global color mapping between a pair of images as a custom normalizing flow, conditioned on a polynomial basis of the pixel color. We show that such a network is more effective than PCA or VAE at encoding image style in low-dimensional space and lets us obtain an accuracy close to 40 dB, which is about 7-10 dB improvement over the state-of-the-art methods.
How to cheat with metrics in single-image HDR reconstruction
Aug 19, 2021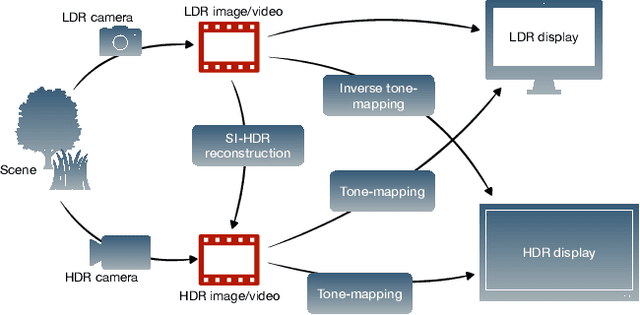
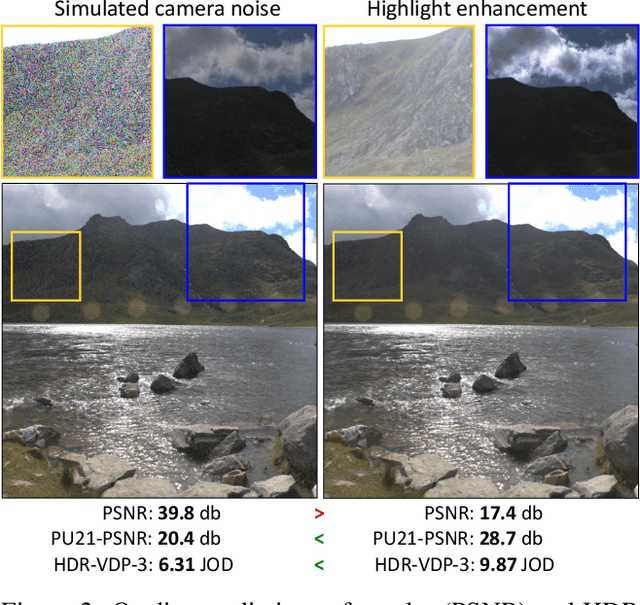
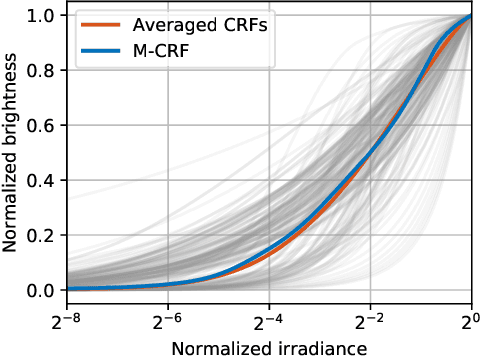
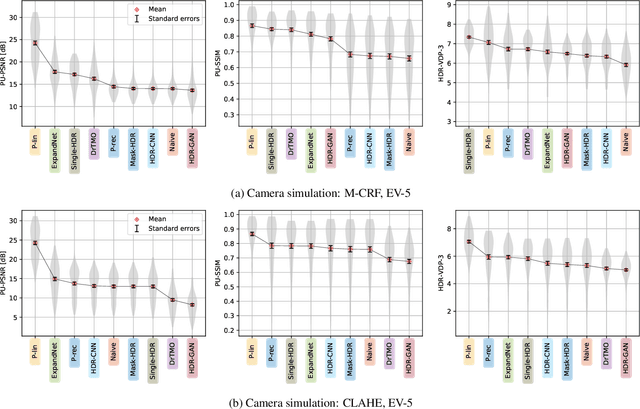
Single-image high dynamic range (SI-HDR) reconstruction has recently emerged as a problem well-suited for deep learning methods. Each successive technique demonstrates an improvement over existing methods by reporting higher image quality scores. This paper, however, highlights that such improvements in objective metrics do not necessarily translate to visually superior images. The first problem is the use of disparate evaluation conditions in terms of data and metric parameters, calling for a standardized protocol to make it possible to compare between papers. The second problem, which forms the main focus of this paper, is the inherent difficulty in evaluating SI-HDR reconstructions since certain aspects of the reconstruction problem dominate objective differences, thereby introducing a bias. Here, we reproduce a typical evaluation using existing as well as simulated SI-HDR methods to demonstrate how different aspects of the problem affect objective quality metrics. Surprisingly, we found that methods that do not even reconstruct HDR information can compete with state-of-the-art deep learning methods. We show how such results are not representative of the perceived quality and that SI-HDR reconstruction needs better evaluation protocols.
Training a Better Loss Function for Image Restoration
Mar 26, 2021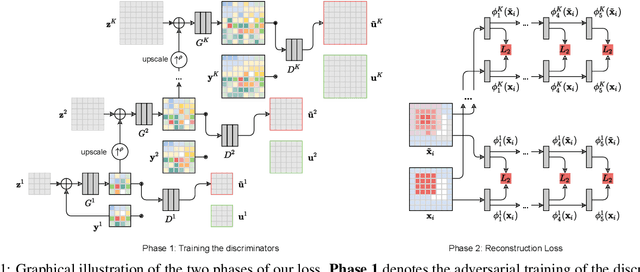
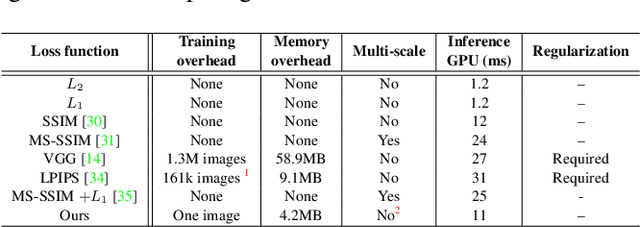
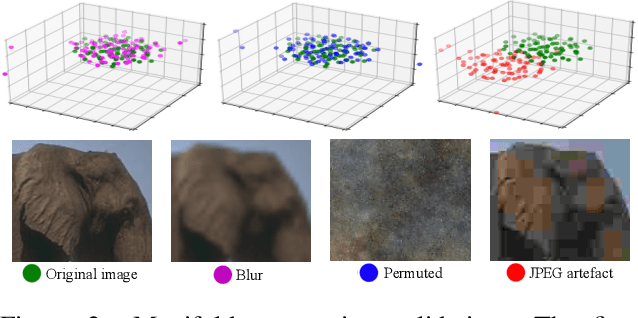
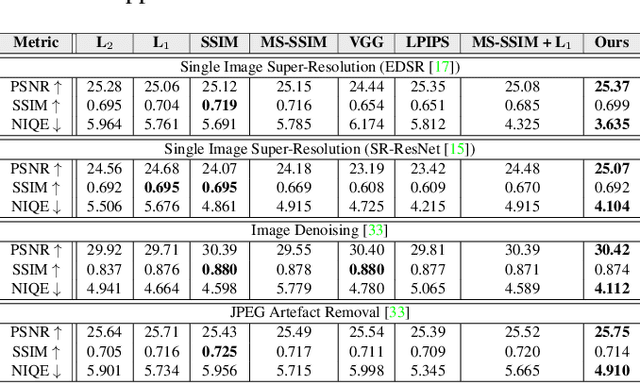
Central to the application of neural networks in image restoration problems, such as single image super resolution, is the choice of a loss function that encourages natural and perceptually pleasing results. A popular choice for a loss function is a pre-trained network, such as VGG and LPIPS, which is used as a feature extractor for computing the difference between restored and reference images. However, such an approach has multiple drawbacks: it is computationally expensive, requires regularization and hyper-parameter tuning, and involves a large network trained on an unrelated task. In this work, we explore the question of what makes a good loss function for an image restoration task. First, we observe that a single natural image is sufficient to train a lightweight feature extractor that outperforms state-of-the-art loss functions in single image super resolution, denoising, and JPEG artefact removal. We propose a novel Multi-Scale Discriminative Feature (MDF) loss comprising a series of discriminators, trained to penalize errors introduced by a generator. Second, we show that an effective loss function does not have to be a good predictor of perceived image quality, but instead needs to be specialized in identifying the distortions for a given restoration method.
Consolidated Dataset and Metrics for High-Dynamic-Range Image Quality
Dec 19, 2020
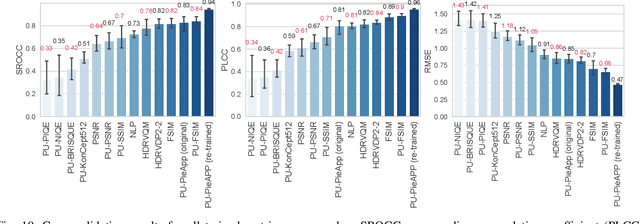
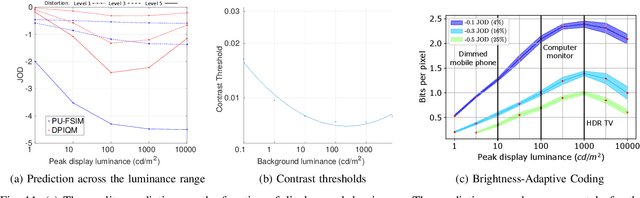
Increasing popularity of high-dynamic-range (HDR) image and video content brings the need for metrics that could predict the severity of image impairments as seen on displays of different brightness levels and dynamic range. Such metrics should be trained and validated on a sufficiently large subjective image quality dataset to ensure robust performance. As the existing HDR quality datasets are limited in size, we created a Unified Photometric Image Quality dataset (UPIQ) with over 4,000 images by realigning and merging existing HDR and standard-dynamic-range (SDR) datasets. The realigned quality scores share the same unified quality scale across all datasets. Such realignment was achieved by collecting additional cross-dataset quality comparisons and re-scaling data with a psychometric scaling method. Images in the proposed dataset are represented in absolute photometric and colorimetric units, corresponding to light emitted from a display. We use the new dataset to retrain existing HDR metrics and show that the dataset is sufficiently large for training deep architectures. We show the utility of the dataset on brightness aware image compression.
Noise-Aware Merging of High Dynamic Range Image Stacks without Camera Calibration
Sep 16, 2020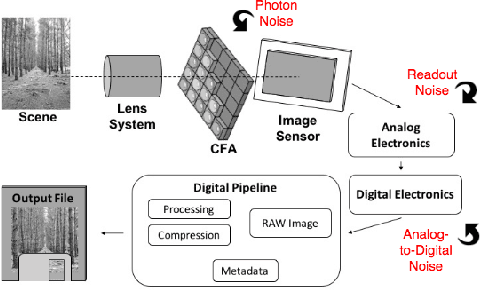
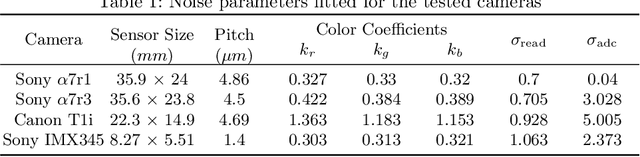
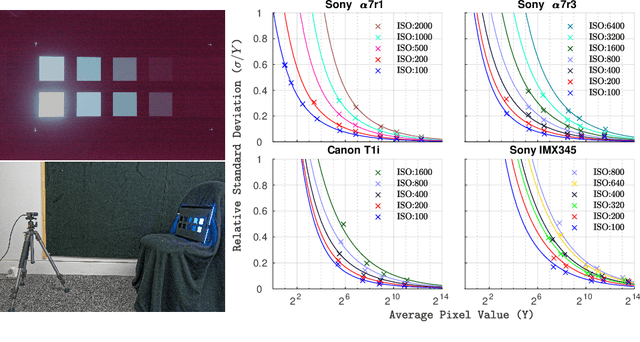
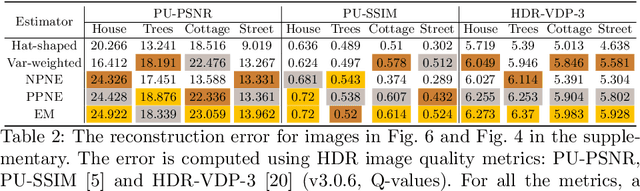
A near-optimal reconstruction of the radiance of a High Dynamic Range scene from an exposure stack can be obtained by modeling the camera noise distribution. The latent radiance is then estimated using Maximum Likelihood Estimation. But this requires a well-calibrated noise model of the camera, which is difficult to obtain in practice. We show that an unbiased estimation of comparable variance can be obtained with a simpler Poisson noise estimator, which does not require the knowledge of camera-specific noise parameters. We demonstrate this empirically for four different cameras, ranging from a smartphone camera to a full-frame mirrorless camera. Our experimental results are consistent for simulated as well as real images, and across different camera settings.
Transformation Consistency Regularization- A Semi-Supervised Paradigm for Image-to-Image Translation
Jul 15, 2020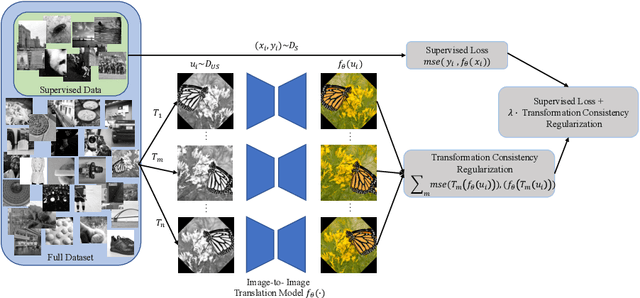
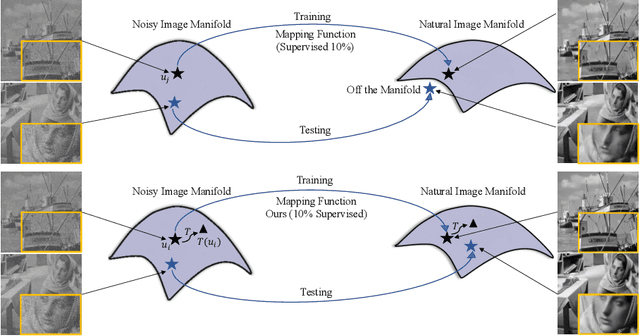
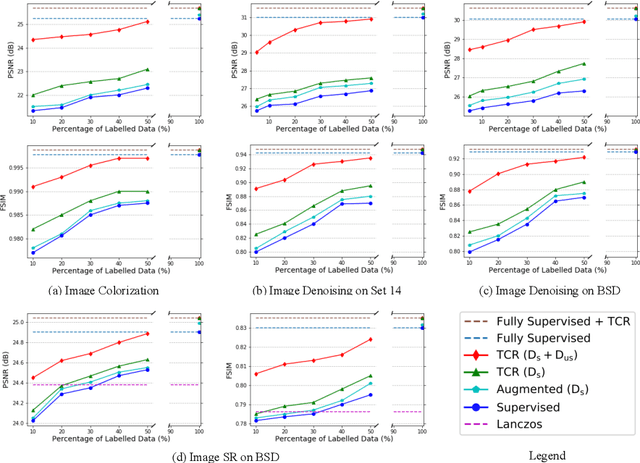

Scarcity of labeled data has motivated the development of semi-supervised learning methods, which learn from large portions of unlabeled data alongside a few labeled samples. Consistency Regularization between model's predictions under different input perturbations, particularly has shown to provide state-of-the art results in a semi-supervised framework. However, most of these method have been limited to classification and segmentation applications. We propose Transformation Consistency Regularization, which delves into a more challenging setting of image-to-image translation, which remains unexplored by semi-supervised algorithms. The method introduces a diverse set of geometric transformations and enforces the model's predictions for unlabeled data to be invariant to those transformations. We evaluate the efficacy of our algorithm on three different applications: image colorization, denoising and super-resolution. Our method is significantly data efficient, requiring only around 10 - 20% of labeled samples to achieve similar image reconstructions to its fully-supervised counterpart. Furthermore, we show the effectiveness of our method in video processing applications, where knowledge from a few frames can be leveraged to enhance the quality of the rest of the movie.
Hybrid-MST: A Hybrid Active Sampling Strategy for Pairwise Preference Aggregation
Oct 20, 2018
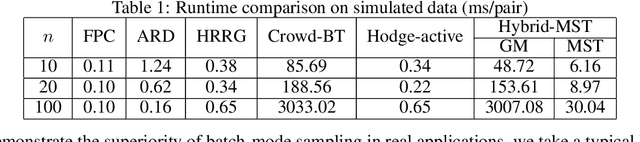


In this paper we present a hybrid active sampling strategy for pairwise preference aggregation, which aims at recovering the underlying rating of the test candidates from sparse and noisy pairwise labelling. Our method employs Bayesian optimization framework and Bradley-Terry model to construct the utility function, then to obtain the Expected Information Gain (EIG) of each pair. For computational efficiency, Gaussian-Hermite quadrature is used for estimation of EIG. In this work, a hybrid active sampling strategy is proposed, either using Global Maximum (GM) EIG sampling or Minimum Spanning Tree (MST) sampling in each trial, which is determined by the test budget. The proposed method has been validated on both simulated and real-world datasets, where it shows higher preference aggregation ability than the state-of-the-art methods.