 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformation Consistency Regularization- A Semi-Supervised Paradigm for Image-to-Image Translation
Paper and Code
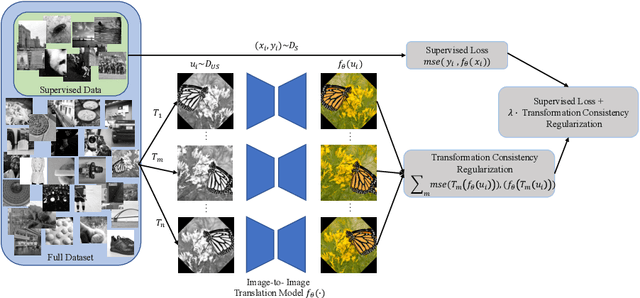
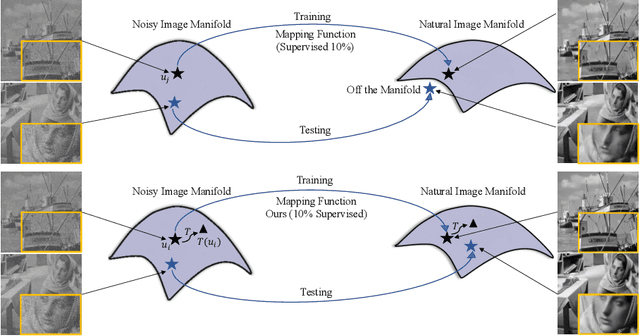
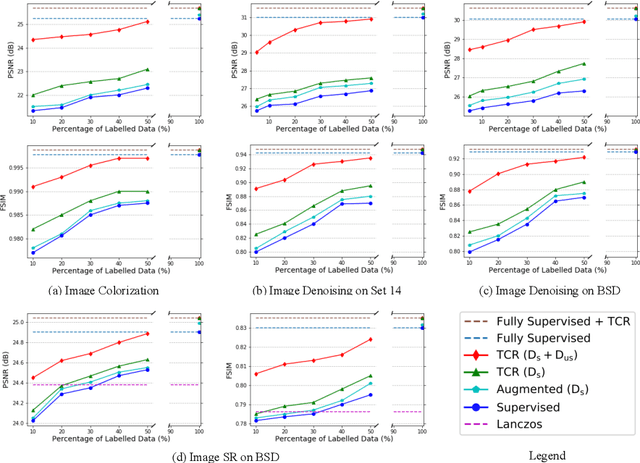

Scarcity of labeled data has motivated the development of semi-supervised learning methods, which learn from large portions of unlabeled data alongside a few labeled samples. Consistency Regularization between model's predictions under different input perturbations, particularly has shown to provide state-of-the art results in a semi-supervised framework. However, most of these method have been limited to classification and segmentation applications. We propose Transformation Consistency Regularization, which delves into a more challenging setting of image-to-image translation, which remains unexplored by semi-supervised algorithms. The method introduces a diverse set of geometric transformations and enforces the model's predictions for unlabeled data to be invariant to those transformations. We evaluate the efficacy of our algorithm on three different applications: image colorization, denoising and super-resolution. Our method is significantly data efficient, requiring only around 10 - 20% of labeled samples to achieve similar image reconstructions to its fully-supervised counterpart. Furthermore, we show the effectiveness of our method in video processing applications, where knowledge from a few frames can be leveraged to enhance the quality of the rest of the movie.