 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear Optimal Decision Trees in a SPLIT Second
Feb 21, 2025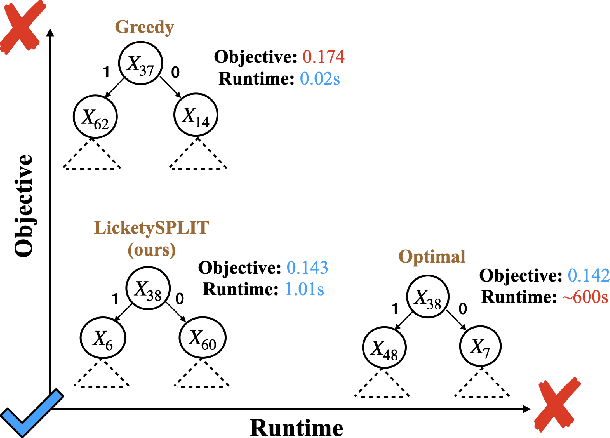

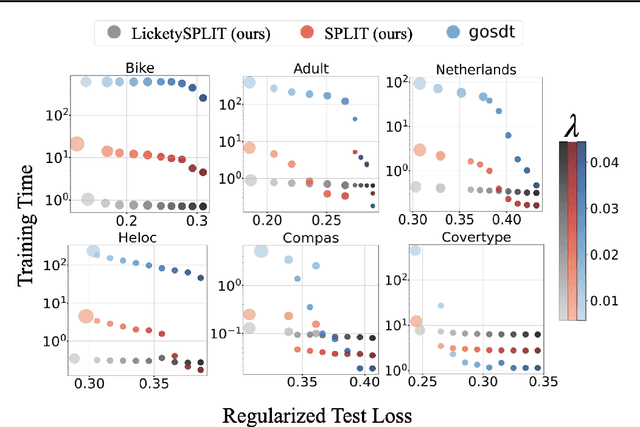

Decision tree optimization is fundamental to interpretable machine learning. The most popular approach is to greedily search for the best feature at every decision point, which is fast but provably suboptimal. Recent approaches find the global optimum using branch and bound with dynamic programming, showing substantial improvements in accuracy and sparsity at great cost to scalability. An ideal solution would have the accuracy of an optimal method and the scalability of a greedy method. We introduce a family of algorithms called SPLIT (SParse Lookahead for Interpretable Trees) that moves us significantly forward in achieving this ideal balance. We demonstrate that not all sub-problems need to be solved to optimality to find high quality trees; greediness suffices near the leaves. Since each depth adds an exponential number of possible trees, this change makes our algorithms orders of magnitude faster than existing optimal methods, with negligible loss in performance. We extend this algorithm to allow scalable computation of sets of near-optimal trees (i.e., the Rashomon set).
What is different between these datasets?
Mar 08, 2024



The performance of machine learning models heavily depends on the quality of input data, yet real-world applications often encounter various data-related challenges. One such challenge could arise when curating training data or deploying the model in the real world - two comparable datasets in the same domain may have different distributions. While numerous techniques exist for detecting distribution shifts, the literature lacks comprehensive approaches for explaining dataset differences in a human-understandable manner. To address this gap, we propose a suite of interpretable methods (toolbox) for comparing two datasets. We demonstrate the versatility of our approach across diverse data modalities, including tabular data, language, images, and signals in both low and high-dimensional settings. Our methods not only outperform comparable and related approaches in terms of explanation quality and correctness, but also provide actionable, complementary insights to understand and mitigate dataset differences effectively.
A New Baseline for GreenAI: Finding the Optimal Sub-Network via Layer and Channel Pruning
Feb 17, 2023The concept of Green AI has been gaining attention within the deep learning community given the recent trend of ever larger and more complex neural network models. Some large models have billions of parameters causing the training time to take up to hundreds of GPU/TPU-days. The estimated energy consumption can be comparable to the annual total energy consumption of a standard household. Existing solutions to reduce the computational burden usually involve pruning the network parameters, however, they often create extra overhead either by iterative training and fine-tuning for static pruning or repeated computation of a dynamic pruning graph. We propose a new parameter pruning strategy that finds the effective group of lightweight sub-networks that minimizes the energy cost while maintaining comparable performances to the full network on given downstream tasks. Our proposed pruning scheme is green-oriented, such that the scheme only requires one-off training to discover the optimal static sub-networks by dynamic pruning methods. The pruning scheme consists of a lightweight, differentiable, and binarized gating module and novel loss functions to uncover sub-networks with user-defined sparsity. Our method enables pruning and training simultaneously, which saves energy in both the training and inference phases and avoids extra computational overhead from gating modules at inference time. Our results on CIFAR-10 and CIFAR-100 suggest that our scheme can remove ~50% of connections in deep networks with <1% reduction in classification accuracy. Compared to other related pruning methods, our method has a lower accuracy drop for equivalent reductions in computational costs.
On the Utility of Prediction Sets in Human-AI Teams
May 03, 2022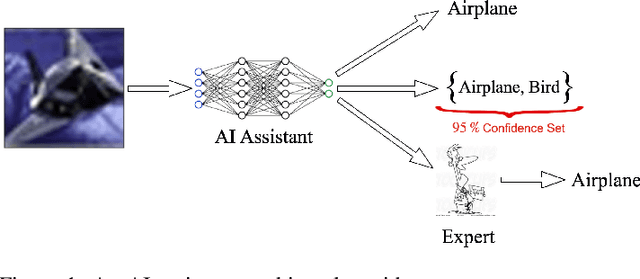
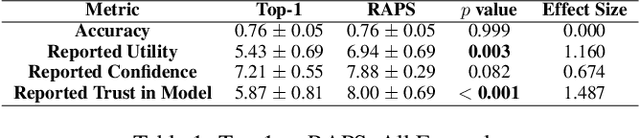
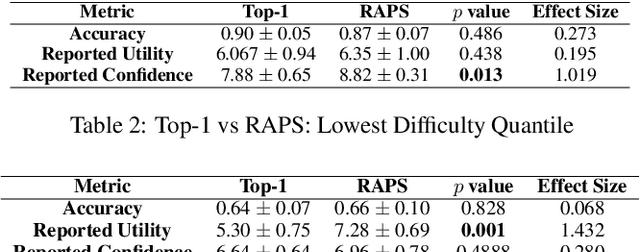
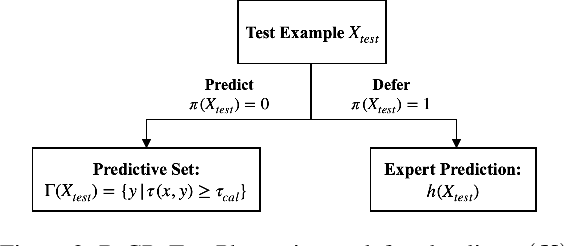
Research on human-AI teams usually provides experts with a single label, which ignores the uncertainty in a model's recommendation. Conformal prediction (CP) is a well established line of research that focuses on building a theoretically grounded, calibrated prediction set, which may contain multiple labels. We explore how such prediction sets impact expert decision-making in human-AI teams. Our evaluation on human subjects finds that set valued predictions positively impact experts. However, we notice that the predictive sets provided by CP can be very large, which leads to unhelpful AI assistants. To mitigate this, we introduce D-CP, a method to perform CP on some examples and defer to experts. We prove that D-CP can reduce the prediction set size of non-deferred examples. We show how D-CP performs in quantitative and in human subject experiments ($n=120$). Our results suggest that CP prediction sets improve human-AI team performance over showing the top-1 prediction alone, and that experts find D-CP prediction sets are more useful than CP prediction sets.
ST-FL: Style Transfer Preprocessing in Federated Learning for COVID-19 Segmentation
Mar 25, 2022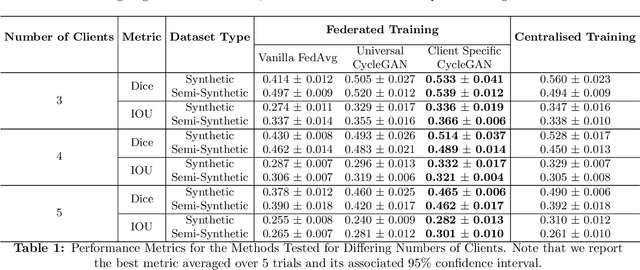
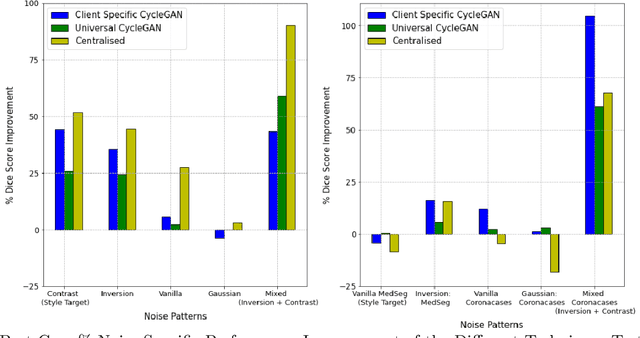
Chest Computational Tomography (CT) scans present low cost, speed and objectivity for COVID-19 diagnosis and deep learning methods have shown great promise in assisting the analysis and interpretation of these images. Most hospitals or countries can train their own models using in-house data, however empirical evidence shows that those models perform poorly when tested on new unseen cases, surfacing the need for coordinated global collaboration. Due to privacy regulations, medical data sharing between hospitals and nations is extremely difficult. We propose a GAN-augmented federated learning model, dubbed ST-FL (Style Transfer Federated Learning), for COVID-19 image segmentation. Federated learning (FL) permits a centralised model to be learned in a secure manner from heterogeneous datasets located in disparate private data silos. We demonstrate that the widely varying data quality on FL client nodes leads to a sub-optimal centralised FL model for COVID-19 chest CT image segmentation. ST-FL is a novel FL framework that is robust in the face of highly variable data quality at client nodes. The robustness is achieved by a denoising CycleGAN model at each client of the federation that maps arbitrary quality images into the same target quality, counteracting the severe data variability evident in real-world FL use-cases. Each client is provided with the target style, which is the same for all clients, and trains their own denoiser. Our qualitative and quantitative results suggest that this FL model performs comparably to, and in some cases better than, a model that has centralised access to all the training data.
Training a Better Loss Function for Image Restoration
Mar 26, 2021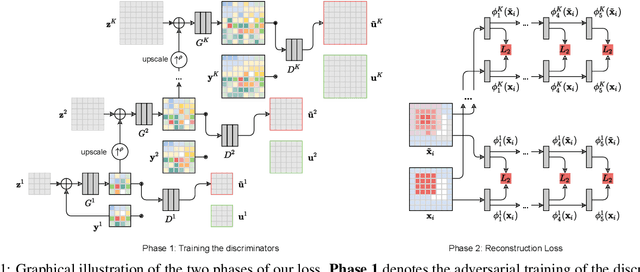
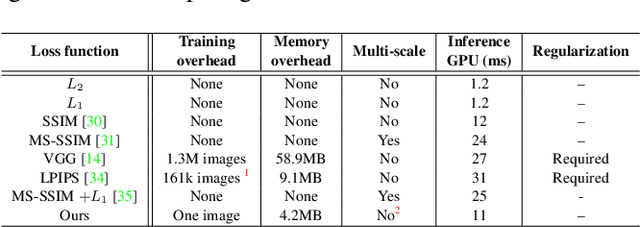
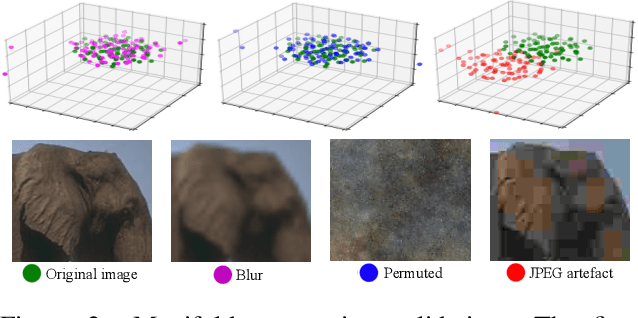
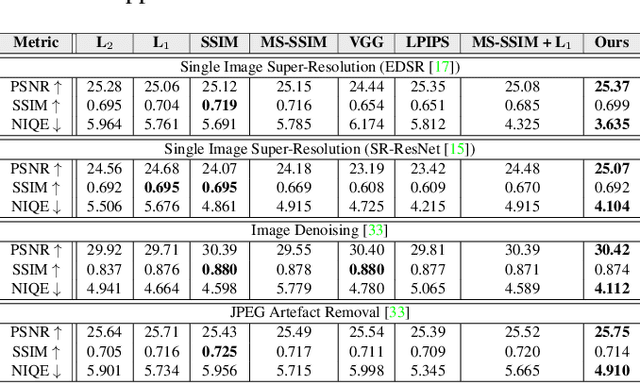
Central to the application of neural networks in image restoration problems, such as single image super resolution, is the choice of a loss function that encourages natural and perceptually pleasing results. A popular choice for a loss function is a pre-trained network, such as VGG and LPIPS, which is used as a feature extractor for computing the difference between restored and reference images. However, such an approach has multiple drawbacks: it is computationally expensive, requires regularization and hyper-parameter tuning, and involves a large network trained on an unrelated task. In this work, we explore the question of what makes a good loss function for an image restoration task. First, we observe that a single natural image is sufficient to train a lightweight feature extractor that outperforms state-of-the-art loss functions in single image super resolution, denoising, and JPEG artefact removal. We propose a novel Multi-Scale Discriminative Feature (MDF) loss comprising a series of discriminators, trained to penalize errors introduced by a generator. Second, we show that an effective loss function does not have to be a good predictor of perceived image quality, but instead needs to be specialized in identifying the distortions for a given restoration method.