 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Utility of Prediction Sets in Human-AI Teams
Paper and Code
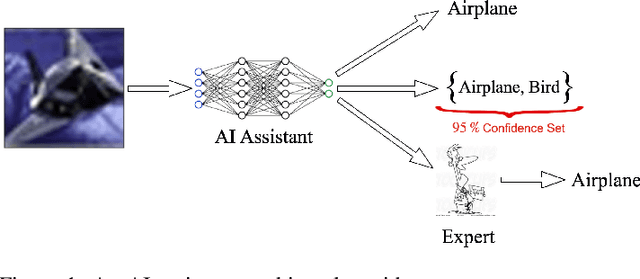
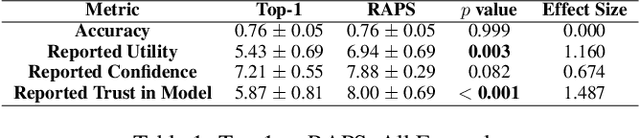
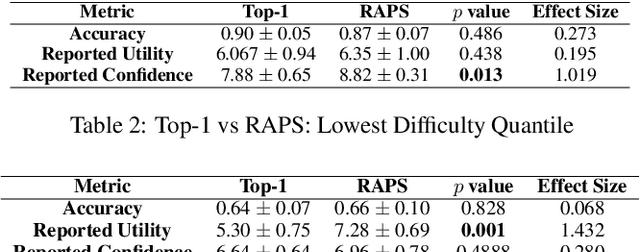
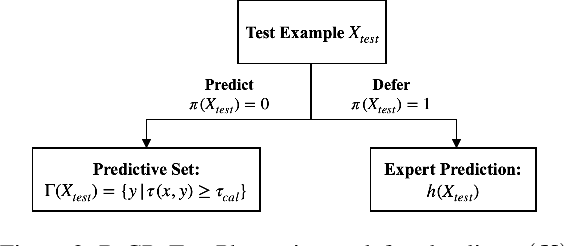
Research on human-AI teams usually provides experts with a single label, which ignores the uncertainty in a model's recommendation. Conformal prediction (CP) is a well established line of research that focuses on building a theoretically grounded, calibrated prediction set, which may contain multiple labels. We explore how such prediction sets impact expert decision-making in human-AI teams. Our evaluation on human subjects finds that set valued predictions positively impact experts. However, we notice that the predictive sets provided by CP can be very large, which leads to unhelpful AI assistants. To mitigate this, we introduce D-CP, a method to perform CP on some examples and defer to experts. We prove that D-CP can reduce the prediction set size of non-deferred examples. We show how D-CP performs in quantitative and in human subject experiments ($n=120$). Our results suggest that CP prediction sets improve human-AI team performance over showing the top-1 prediction alone, and that experts find D-CP prediction sets are more useful than CP prediction sets.