 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustry-Aligned Granular Topic Modeling
Jan 16, 2026Topic modeling has extensive applications in text mining and data analysis across various industrial sectors. Although the concept of granularity holds significant value for business applications by providing deeper insights, the capability of topic modeling methods to produce granular topics has not been thoroughly explored. In this context, this paper introduces a framework called TIDE, which primarily provides a novel granular topic modeling method based on large language models (LLMs) as a core feature, along with other useful functionalities for business applications, such as summarizing long documents, topic parenting, and distillation. Through extensive experiments on a variety of public and real-world business datasets, we demonstrate that TIDE's topic modeling approach outperforms modern topic modeling methods, and our auxiliary components provide valuable support for dealing with industrial business scenarios. The TIDE framework is currently undergoing the process of being open sourced.
Automatic Labelling with Open-source LLMs using Dynamic Label Schema Integration
Jan 21, 2025Acquiring labelled training data remains a costly task in real world machine learning projects to meet quantity and quality requirements. Recently Large Language Models (LLMs), notably GPT-4, have shown great promises in labelling data with high accuracy. However, privacy and cost concerns prevent the ubiquitous use of GPT-4. In this work, we explore effectively leveraging open-source models for automatic labelling. We identify integrating label schema as a promising technology but found that naively using the label description for classification leads to poor performance on high cardinality tasks. To address this, we propose Retrieval Augmented Classification (RAC) for which LLM performs inferences for one label at a time using corresponding label schema; we start with the most related label and iterates until a label is chosen by the LLM. We show that our method, which dynamically integrates label description, leads to performance improvements in labelling tasks. We further show that by focusing only on the most promising labels, RAC can trade off between label quality and coverage - a property we leverage to automatically label our internal datasets.
A Benchmark Generative Probabilistic Model for Weak Supervised Learning
Mar 31, 2023Finding relevant and high-quality datasets to train machine learning models is a major bottleneck for practitioners. Furthermore, to address ambitious real-world use-cases there is usually the requirement that the data come labelled with high-quality annotations that can facilitate the training of a supervised model. Manually labelling data with high-quality labels is generally a time-consuming and challenging task and often this turns out to be the bottleneck in a machine learning project. Weak Supervised Learning (WSL) approaches have been developed to alleviate the annotation burden by offering an automatic way of assigning approximate labels (pseudo-labels) to unlabelled data based on heuristics, distant supervision and knowledge bases. We apply probabilistic generative latent variable models (PLVMs), trained on heuristic labelling representations of the original dataset, as an accurate, fast and cost-effective way to generate pseudo-labels. We show that the PLVMs achieve state-of-the-art performance across four datasets. For example, they achieve 22% points higher F1 score than Snorkel in the class-imbalanced Spouse dataset. PLVMs are plug-and-playable and are a drop-in replacement to existing WSL frameworks (e.g. Snorkel) or they can be used as benchmark models for more complicated algorithms, giving practitioners a compelling accuracy boost.
A New Baseline for GreenAI: Finding the Optimal Sub-Network via Layer and Channel Pruning
Feb 17, 2023The concept of Green AI has been gaining attention within the deep learning community given the recent trend of ever larger and more complex neural network models. Some large models have billions of parameters causing the training time to take up to hundreds of GPU/TPU-days. The estimated energy consumption can be comparable to the annual total energy consumption of a standard household. Existing solutions to reduce the computational burden usually involve pruning the network parameters, however, they often create extra overhead either by iterative training and fine-tuning for static pruning or repeated computation of a dynamic pruning graph. We propose a new parameter pruning strategy that finds the effective group of lightweight sub-networks that minimizes the energy cost while maintaining comparable performances to the full network on given downstream tasks. Our proposed pruning scheme is green-oriented, such that the scheme only requires one-off training to discover the optimal static sub-networks by dynamic pruning methods. The pruning scheme consists of a lightweight, differentiable, and binarized gating module and novel loss functions to uncover sub-networks with user-defined sparsity. Our method enables pruning and training simultaneously, which saves energy in both the training and inference phases and avoids extra computational overhead from gating modules at inference time. Our results on CIFAR-10 and CIFAR-100 suggest that our scheme can remove ~50% of connections in deep networks with <1% reduction in classification accuracy. Compared to other related pruning methods, our method has a lower accuracy drop for equivalent reductions in computational costs.
API-Spector: an API-to-API Specification Recommendation Engine
Dec 14, 2022When designing a new API for a large project, developers need to make smart design choices so that their code base can grow sustainably. To ensure that new API components are well designed, developers can learn from existing API components. However, the lack of standardized method for comparing API designs makes this learning process time-consuming and difficult. To address this gap we developed the API-Spector, to the best of our knowledge one of the first API-to-API specification recommendation engines. API-Spector retrieves relevant specification components written in OpenAPI (a widely adopted language used to describe web APIs). API-Spector presents several significant contributions, including: (1) novel methods of processing and extracting key information from OpenAPI specifications, (2) innovative feature extraction techniques that are optimized for the highly technical API specification domain, and (3) a novel log-linear probabilistic model that combines multiple signals to retrieve relevant and high quality OpenAPI specification components given a query specification. We evaluate API-Spector in both quantitative and qualitative tasks and achieve an overall of 91.7% recall@1 and 56.2% F1, which surpasses baseline performance by 15.4% in recall@1 and 3.2% in F1. Overall, API-Spector will allow developers to retrieve relevant OpenAPI specification components from a public or internal database in the early stages of the API development cycle, so that they can learn from existing established examples and potentially identify redundancies in their work. It provides the guidance developers need to accelerate development process and contribute thoughtfully designed APIs that promote code maintainability and quality.
Topical: Learning Repository Embeddings from Source Code using Attention
Aug 19, 2022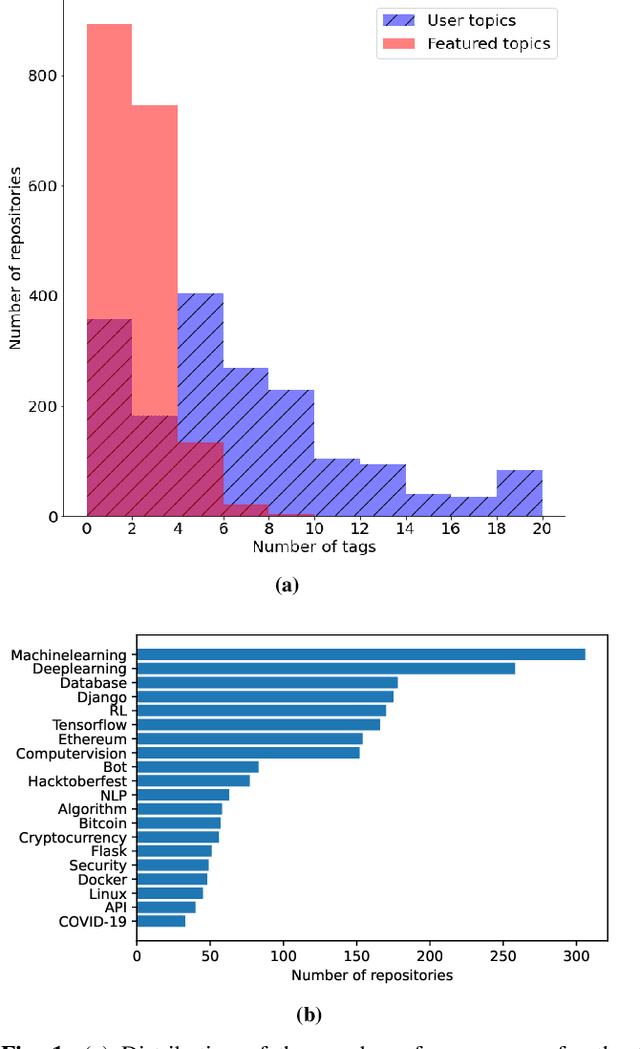
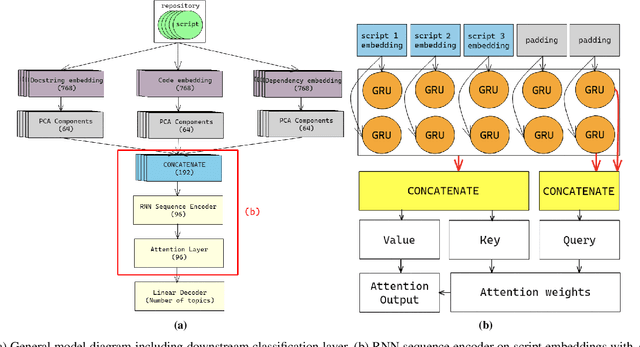

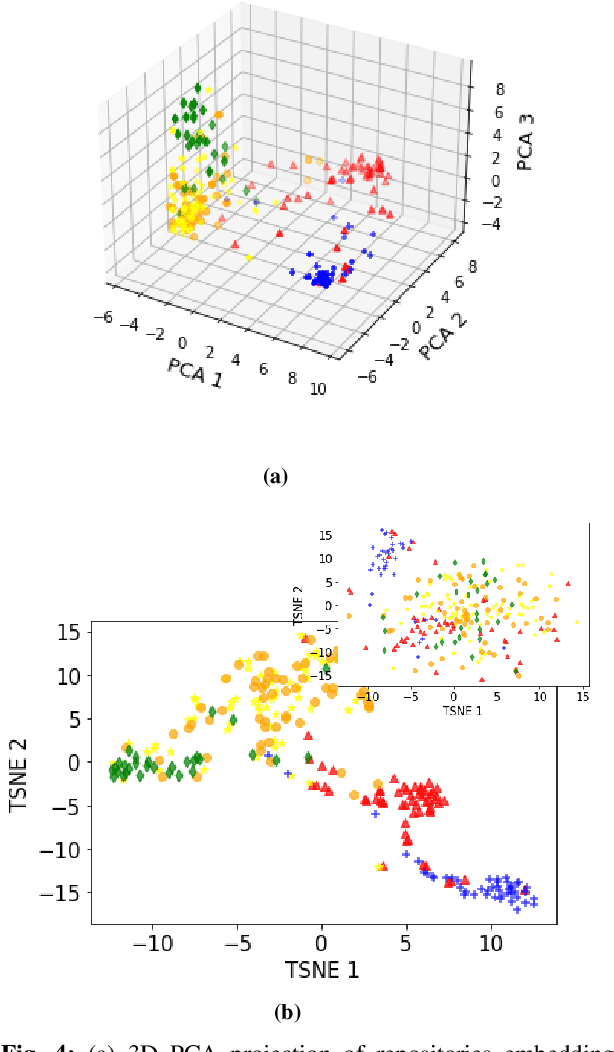
Machine learning on source code (MLOnCode) promises to transform how software is delivered. By mining the context and relationship between software artefacts, MLOnCode augments the software developers capabilities with code auto-generation, code recommendation, code auto-tagging and other data-driven enhancements. For many of these tasks a script level representation of code is sufficient, however, in many cases a repository level representation that takes into account various dependencies and repository structure is imperative, for example, auto-tagging repositories with topics or auto-documentation of repository code etc. Existing methods for computing repository level representations suffer from (a) reliance on natural language documentation of code (for example, README files) (b) naive aggregation of method/script-level representation, for example, by concatenation or averaging. This paper introduces Topical a deep neural network to generate repository level embeddings of publicly available GitHub code repositories directly from source code. Topical incorporates an attention mechanism that projects the source code, the full dependency graph and the script level textual information into a dense repository-level representation. To compute the repository-level representations, Topical is trained to predict the topics associated with a repository, on a dataset of publicly available GitHub repositories that were crawled along with their ground truth topic tags. Our experiments show that the embeddings computed by Topical are able to outperform multiple baselines, including baselines that naively combine the method-level representations through averaging or concatenation at the task of repository auto-tagging.
CV4Code: Sourcecode Understanding via Visual Code Representations
May 11, 2022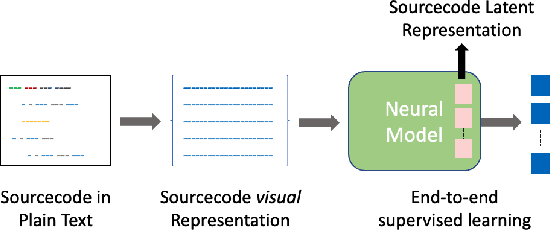
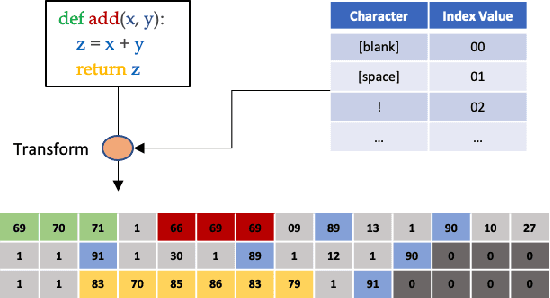

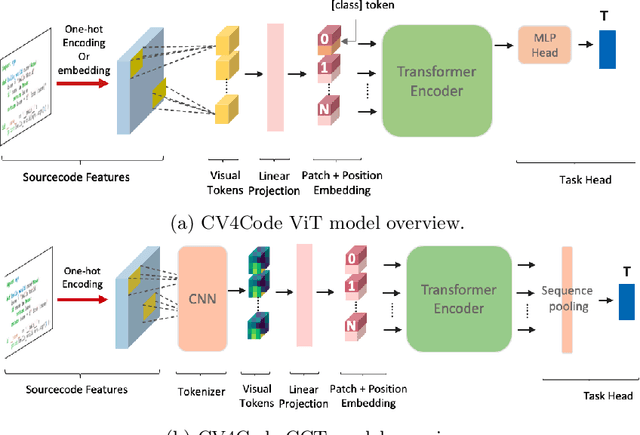
We present CV4Code, a compact and effective computer vision method for sourcecode understanding. Our method leverages the contextual and the structural information available from the code snippet by treating each snippet as a two-dimensional image, which naturally encodes the context and retains the underlying structural information through an explicit spatial representation. To codify snippets as images, we propose an ASCII codepoint-based image representation that facilitates fast generation of sourcecode images and eliminates redundancy in the encoding that would arise from an RGB pixel representation. Furthermore, as sourcecode is treated as images, neither lexical analysis (tokenisation) nor syntax tree parsing is required, which makes the proposed method agnostic to any particular programming language and lightweight from the application pipeline point of view. CV4Code can even featurise syntactically incorrect code which is not possible from methods that depend on the Abstract Syntax Tree (AST). We demonstrate the effectiveness of CV4Code by learning Convolutional and Transformer networks to predict the functional task, i.e. the problem it solves, of the source code directly from its two-dimensional representation, and using an embedding from its latent space to derive a similarity score of two code snippets in a retrieval setup. Experimental results show that our approach achieves state-of-the-art performance in comparison to other methods with the same task and data configurations. For the first time we show the benefits of treating sourcecode understanding as a form of image processing task.
Enhancing Privacy against Inversion Attacks in Federated Learning by using Mixing Gradients Strategies
Apr 26, 2022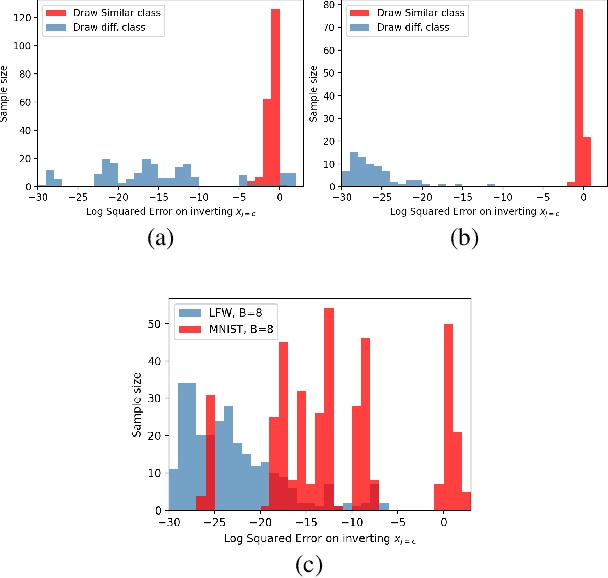

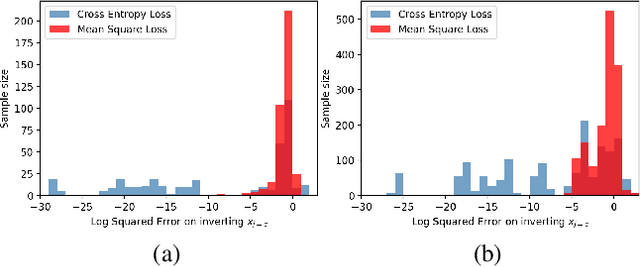
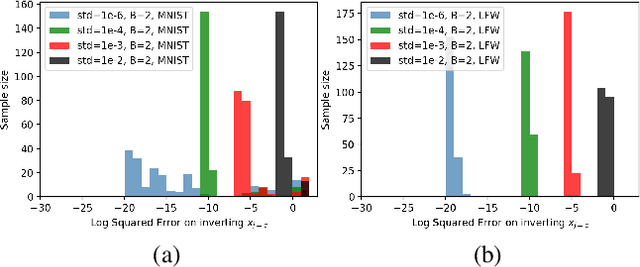
Federated learning reduces the risk of information leakage, but remains vulnerable to attacks. We investigate how several neural network design decisions can defend against gradients inversion attacks. We show that overlapping gradients provides numerical resistance to gradient inversion on the highly vulnerable dense layer. Specifically, we propose to leverage batching to maximise mixing of gradients by choosing an appropriate loss function and drawing identical labels. We show that otherwise it is possible to directly recover all vectors in a mini-batch without any numerical optimisation due to the de-mixing nature of the cross entropy loss. To accurately assess data recovery, we introduce an absolute variation distance (AVD) metric for information leakage in images, derived from total variation. In contrast to standard metrics, e.g. Mean Squared Error or Structural Similarity Index, AVD offers a continuous metric for extracting information in noisy images. Finally, our empirical results on information recovery from various inversion attacks and training performance supports our defense strategies. These strategies are also shown to be useful for deep convolutional neural networks such as LeNET for image recognition. We hope that this study will help guide the development of further strategies that achieve a trustful federation policy.
ST-FL: Style Transfer Preprocessing in Federated Learning for COVID-19 Segmentation
Mar 25, 2022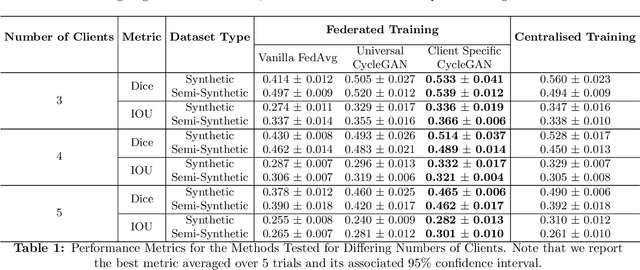
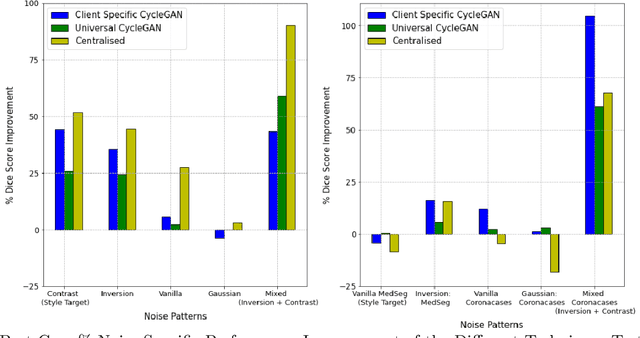
Chest Computational Tomography (CT) scans present low cost, speed and objectivity for COVID-19 diagnosis and deep learning methods have shown great promise in assisting the analysis and interpretation of these images. Most hospitals or countries can train their own models using in-house data, however empirical evidence shows that those models perform poorly when tested on new unseen cases, surfacing the need for coordinated global collaboration. Due to privacy regulations, medical data sharing between hospitals and nations is extremely difficult. We propose a GAN-augmented federated learning model, dubbed ST-FL (Style Transfer Federated Learning), for COVID-19 image segmentation. Federated learning (FL) permits a centralised model to be learned in a secure manner from heterogeneous datasets located in disparate private data silos. We demonstrate that the widely varying data quality on FL client nodes leads to a sub-optimal centralised FL model for COVID-19 chest CT image segmentation. ST-FL is a novel FL framework that is robust in the face of highly variable data quality at client nodes. The robustness is achieved by a denoising CycleGAN model at each client of the federation that maps arbitrary quality images into the same target quality, counteracting the severe data variability evident in real-world FL use-cases. Each client is provided with the target style, which is the same for all clients, and trains their own denoiser. Our qualitative and quantitative results suggest that this FL model performs comparably to, and in some cases better than, a model that has centralised access to all the training data.
DeSkew-LSH based Code-to-Code Recommendation Engine
Nov 05, 2021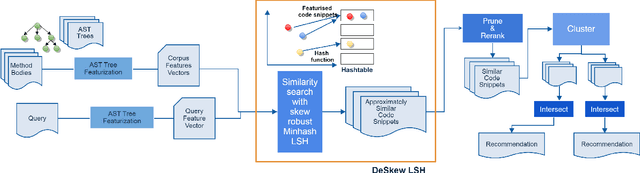
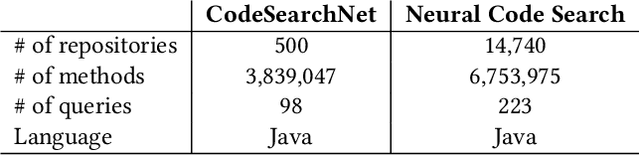

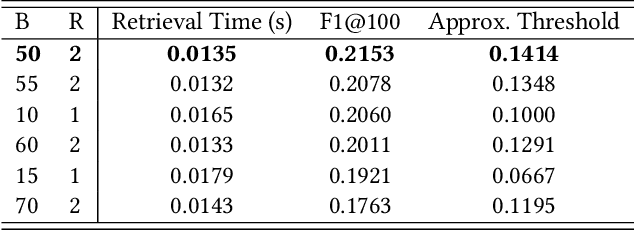
Machine learning on source code (MLOnCode) is a popular research field that has been driven by the availability of large-scale code repositories and the development of powerful probabilistic and deep learning models for mining source code. Code-to-code recommendation is a task in MLOnCode that aims to recommend relevant, diverse and concise code snippets that usefully extend the code currently being written by a developer in their development environment (IDE). Code-to-code recommendation engines hold the promise of increasing developer productivity by reducing context switching from the IDE and increasing code-reuse. Existing code-to-code recommendation engines do not scale gracefully to large codebases, exhibiting a linear growth in query time as the code repository increases in size. In addition, existing code-to-code recommendation engines fail to account for the global statistics of code repositories in the ranking function, such as the distribution of code snippet lengths, leading to sub-optimal retrieval results. We address both of these weaknesses with \emph{Senatus}, a new code-to-code recommendation engine. At the core of Senatus is \emph{De-Skew} LSH a new locality sensitive hashing (LSH) algorithm that indexes the data for fast (sub-linear time) retrieval while also counteracting the skewness in the snippet length distribution using novel abstract syntax tree-based feature scoring and selection algorithms. We evaluate Senatus via automatic evaluation and with an expert developer user study and find the recommendations to be of higher quality than competing baselines, while achieving faster search. For example, on the CodeSearchNet dataset we show that Senatus improves performance by 6.7\% F1 and query time 16x is faster compared to Facebook Aroma on the task of code-to-code recommendation.