 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Numerical Gradient Inversion Attack in Variational Quantum Neural-Networks
Apr 17, 2025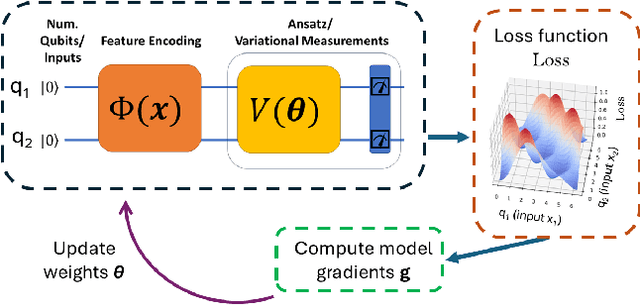
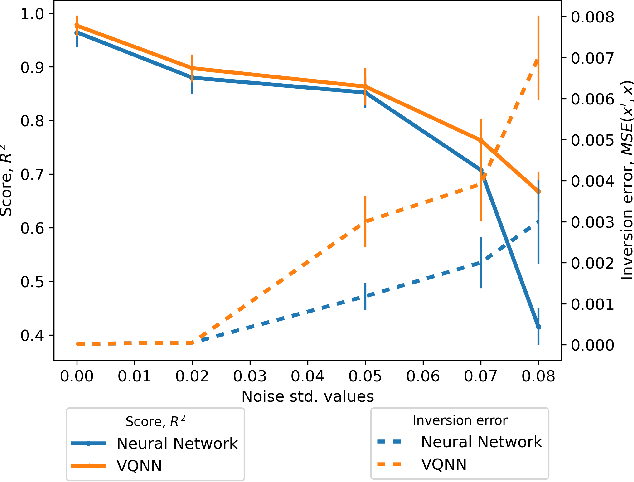
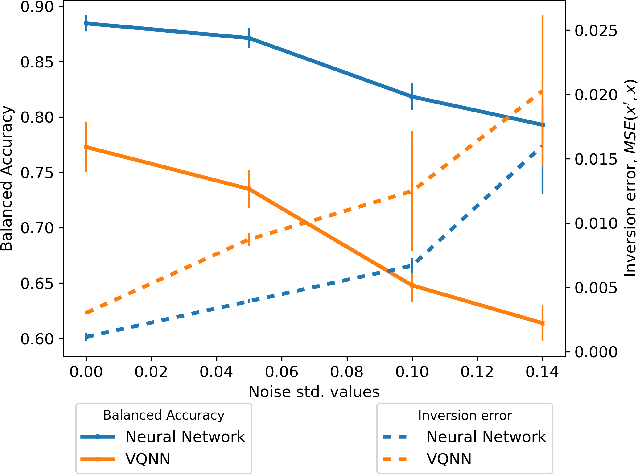
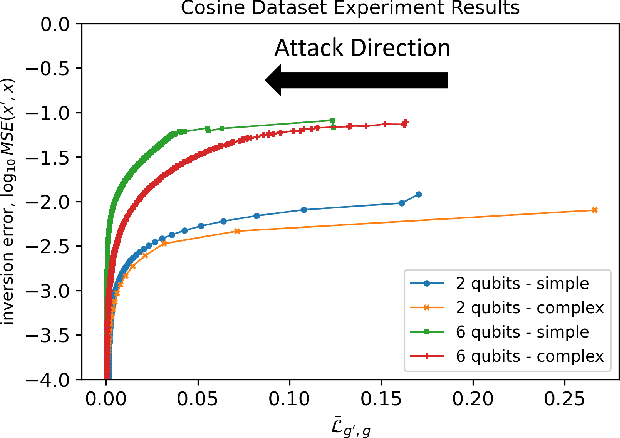
The loss landscape of Variational Quantum Neural Networks (VQNNs) is characterized by local minima that grow exponentially with increasing qubits. Because of this, it is more challenging to recover information from model gradients during training compared to classical Neural Networks (NNs). In this paper we present a numerical scheme that successfully reconstructs input training, real-world, practical data from trainable VQNNs' gradients. Our scheme is based on gradient inversion that works by combining gradients estimation with the finite difference method and adaptive low-pass filtering. The scheme is further optimized with Kalman filter to obtain efficient convergence. Our experiments show that our algorithm can invert even batch-trained data, given the VQNN model is sufficiently over-parameterized.
Hyperspectral unmixing for Raman spectroscopy via physics-constrained autoencoders
Mar 07, 2024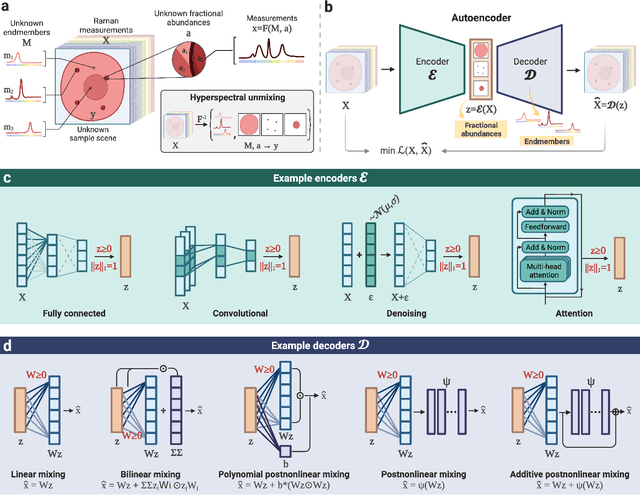
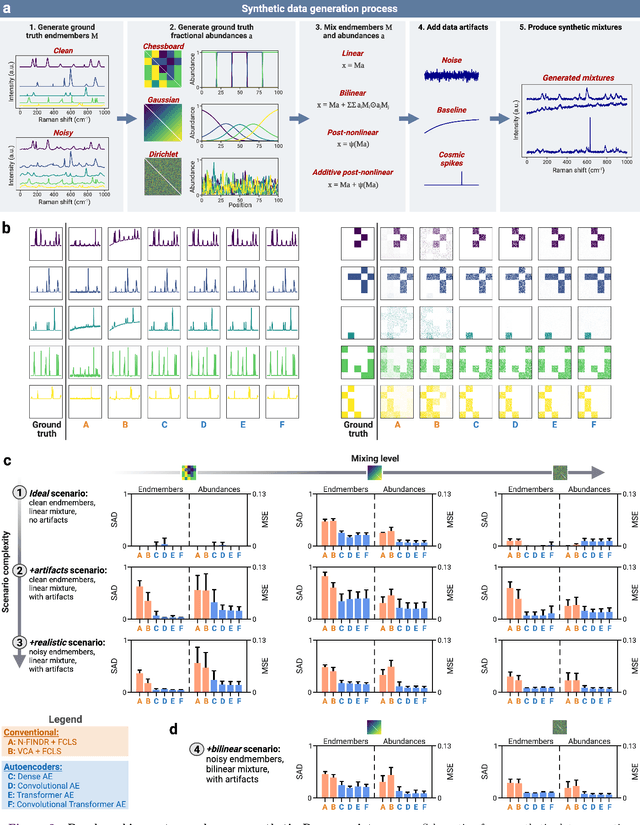
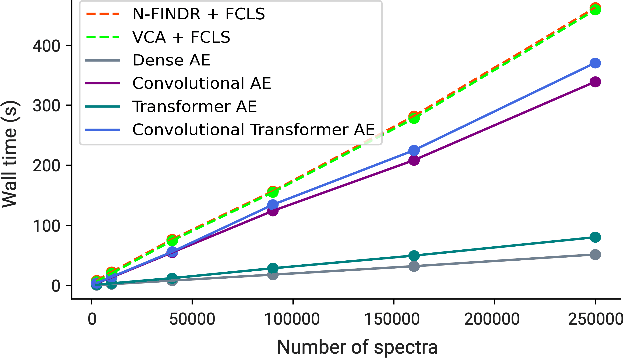
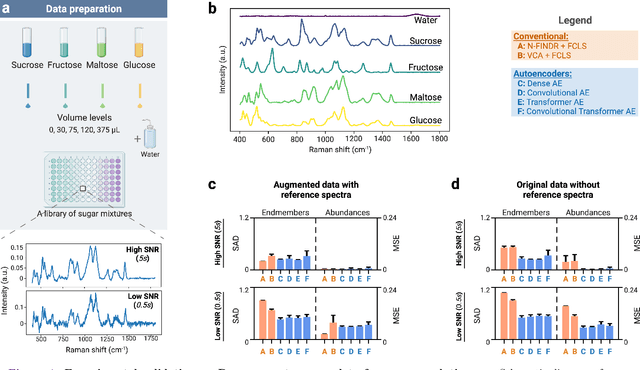
Raman spectroscopy is widely used across scientific domains to characterize the chemical composition of samples in a non-destructive, label-free manner. Many applications entail the unmixing of signals from mixtures of molecular species to identify the individual components present and their proportions, yet conventional methods for chemometrics often struggle with complex mixture scenarios encountered in practice. Here, we develop hyperspectral unmixing algorithms based on autoencoder neural networks, and we systematically validate them using both synthetic and experimental benchmark datasets created in-house. Our results demonstrate that unmixing autoencoders provide improved accuracy, robustness and efficiency compared to standard unmixing methods. We also showcase the applicability of autoencoders to complex biological settings by showing improved biochemical characterization of volumetric Raman imaging data from a monocytic cell.
A Benchmark Generative Probabilistic Model for Weak Supervised Learning
Mar 31, 2023Finding relevant and high-quality datasets to train machine learning models is a major bottleneck for practitioners. Furthermore, to address ambitious real-world use-cases there is usually the requirement that the data come labelled with high-quality annotations that can facilitate the training of a supervised model. Manually labelling data with high-quality labels is generally a time-consuming and challenging task and often this turns out to be the bottleneck in a machine learning project. Weak Supervised Learning (WSL) approaches have been developed to alleviate the annotation burden by offering an automatic way of assigning approximate labels (pseudo-labels) to unlabelled data based on heuristics, distant supervision and knowledge bases. We apply probabilistic generative latent variable models (PLVMs), trained on heuristic labelling representations of the original dataset, as an accurate, fast and cost-effective way to generate pseudo-labels. We show that the PLVMs achieve state-of-the-art performance across four datasets. For example, they achieve 22% points higher F1 score than Snorkel in the class-imbalanced Spouse dataset. PLVMs are plug-and-playable and are a drop-in replacement to existing WSL frameworks (e.g. Snorkel) or they can be used as benchmark models for more complicated algorithms, giving practitioners a compelling accuracy boost.
Web Robot Detection in Academic Publishing
Nov 14, 2017
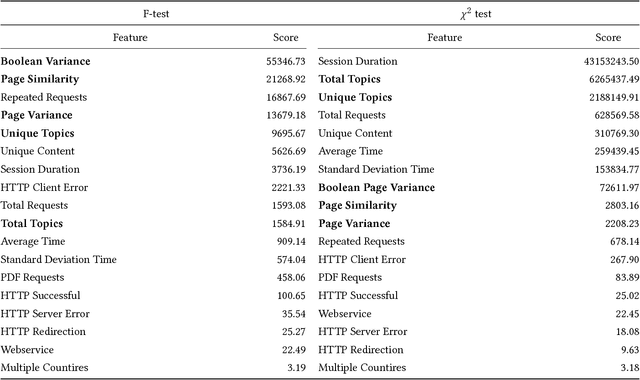


Recent industry reports assure the rise of web robots which comprise more than half of the total web traffic. They not only threaten the security, privacy and efficiency of the web but they also distort analytics and metrics, doubting the veracity of the information being promoted. In the academic publishing domain, this can cause articles to be faulty presented as prominent and influential. In this paper, we present our approach on detecting web robots in academic publishing websites. We use different supervised learning algorithms with a variety of characteristics deriving from both the log files of the server and the content served by the website. Our approach relies on the assumption that human users will be interested in specific domains or articles, while web robots crawl a web library incoherently. We experiment with features adopted in previous studies with the addition of novel semantic characteristics which derive after performing a semantic analysis using the Latent Dirichlet Allocation (LDA) algorithm. Our real-world case study shows promising results, pinpointing the significance of semantic features in the web robot detection problem.
Analysis of Asymptotically Optimal Sampling-based Motion Planning Algorithms for Lipschitz Continuous Dynamical Systems
May 12, 2014



Over the last 20 years significant effort has been dedicated to the development of sampling-based motion planning algorithms such as the Rapidly-exploring Random Trees (RRT) and its asymptotically optimal version (e.g. RRT*). However, asymptotic optimality for RRT* only holds for linear and fully actuated systems or for a small number of non-linear systems (e.g. Dubin's car) for which a steering function is available. The purpose of this paper is to show that asymptotically optimal motion planning for dynamical systems with differential constraints can be achieved without the use of a steering function. We develop a novel analysis on sampling-based planning algorithms that sample the control space. This analysis demonstrated that asymptotically optimal path planning for any Lipschitz continuous dynamical system can be achieved by sampling the control space directly. We also determine theoretical bounds on the convergence rates for this class of algorithms. As the number of iterations increases, the trajectory generated by these algorithms, approaches the optimal control trajectory, with probability one. Simulation results are promising.