 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOMDP-based Object Search with Growing State Space and Hybrid Action Domain
Apr 16, 2026Efficiently locating target objects in complex indoor environments with diverse furniture, such as shelves, tables, and beds, is a significant challenge for mobile robots. This difficulty arises from factors like localization errors, limited fields of view, and visual occlusion. We address this by framing the object-search task as a highdimensional Partially Observable Markov Decision Process (POMDP) with a growing state space and hybrid (continuous and discrete) action spaces in 3D environments. Based on a meticulously designed perception module, a novel online POMDP solver named the growing neural process filtered k-center clustering tree (GNPF-kCT) is proposed to tackle this problem. Optimal actions are selected using Monte Carlo Tree Search (MCTS) with belief tree reuse for growing state space, a neural process network to filter useless primitive actions, and k-center clustering hypersphere discretization for efficient refinement of high-dimensional action spaces. A modified upper-confidence bound (UCB), informed by belief differences and action value functions within cells of estimated diameters, guides MCTS expansion. Theoretical analysis validates the convergence and performance potential of our method. To address scenarios with limited information or rewards, we also introduce a guessed target object with a grid-world model as a key strategy to enhance search efficiency. Extensive Gazebo simulations with Fetch and Stretch robots demonstrate faster and more reliable target localization than POMDP-based baselines and state-of-the-art (SOTA) non-POMDP-based solvers, especially large language model (LLM) based methods, in object search under the same computational constraints and perception systems. Real-world tests in office environments confirm the practical applicability of our approach. Project page: https://sites.google.com/view/gnpfkct.
Generalised Linear Models in Deep Bayesian RL with Learnable Basis Functions
Dec 24, 2025Bayesian Reinforcement Learning (BRL) provides a framework for generalisation of Reinforcement Learning (RL) problems from its use of Bayesian task parameters in the transition and reward models. However, classical BRL methods assume known forms of transition and reward models, reducing their applicability in real-world problems. As a result, recent deep BRL methods have started to incorporate model learning, though the use of neural networks directly on the joint data and task parameters requires optimising the Evidence Lower Bound (ELBO). ELBOs are difficult to optimise and may result in indistinctive task parameters, hence compromised BRL policies. To this end, we introduce a novel deep BRL method, Generalised Linear Models in Deep Bayesian RL with Learnable Basis Functions (GLiBRL), that enables efficient and accurate learning of transition and reward models, with fully tractable marginal likelihood and Bayesian inference on task parameters and model noises. On challenging MetaWorld ML10/45 benchmarks, GLiBRL improves the success rate of one of the state-of-the-art deep BRL methods, VariBAD, by up to 2.7x. Comparing against representative or recent deep BRL / Meta-RL methods, such as MAML, RL2, SDVT, TrMRL and ECET, GLiBRL also demonstrates its low-variance and decent performance consistently.
Vectorized Online POMDP Planning
Oct 31, 2025Planning under partial observability is an essential capability of autonomous robots. The Partially Observable Markov Decision Process (POMDP) provides a powerful framework for planning under partial observability problems, capturing the stochastic effects of actions and the limited information available through noisy observations. POMDP solving could benefit tremendously from massive parallelization of today's hardware, but parallelizing POMDP solvers has been challenging. They rely on interleaving numerical optimization over actions with the estimation of their values, which creates dependencies and synchronization bottlenecks between parallel processes that can quickly offset the benefits of parallelization. In this paper, we propose Vectorized Online POMDP Planner (VOPP), a novel parallel online solver that leverages a recent POMDP formulation that analytically solves part of the optimization component, leaving only the estimation of expectations for numerical computation. VOPP represents all data structures related to planning as a collection of tensors and implements all planning steps as fully vectorized computations over this representation. The result is a massively parallel solver with no dependencies and synchronization bottlenecks between parallel computations. Experimental results indicate that VOPP is at least 20X more efficient in computing near-optimal solutions compared to an existing state-of-the-art parallel online solver.
Partially Observable Reference Policy Programming: Solving POMDPs Sans Numerical Optimisation
Jul 16, 2025This paper proposes Partially Observable Reference Policy Programming, a novel anytime online approximate POMDP solver which samples meaningful future histories very deeply while simultaneously forcing a gradual policy update. We provide theoretical guarantees for the algorithm's underlying scheme which say that the performance loss is bounded by the average of the sampling approximation errors rather than the usual maximum, a crucial requirement given the sampling sparsity of online planning. Empirical evaluations on two large-scale problems with dynamically evolving environments -- including a helicopter emergency scenario in the Corsica region requiring approximately 150 planning steps -- corroborate the theoretical results and indicate that our solver considerably outperforms current online benchmarks.
Scaling Long-Horizon Online POMDP Planning via Rapid State Space Sampling
Nov 11, 2024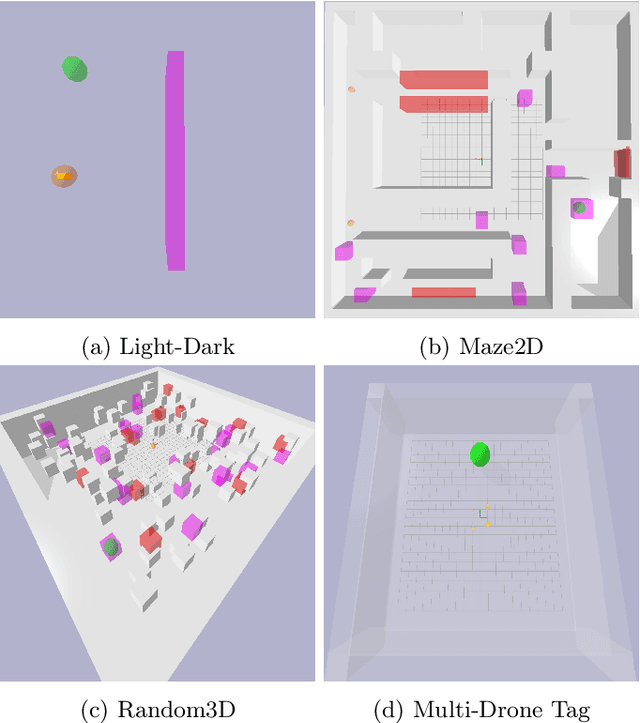
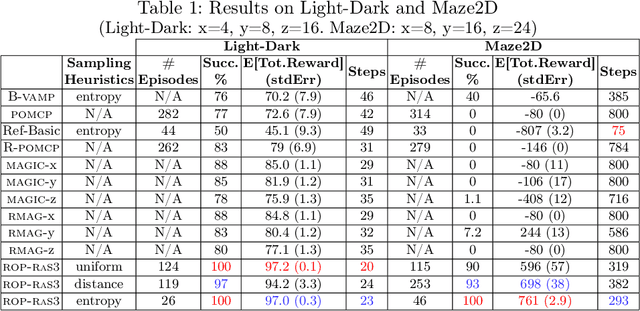
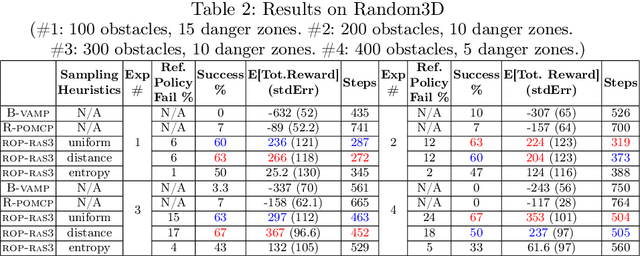
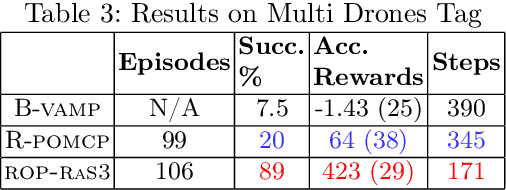
Partially Observable Markov Decision Processes (POMDPs) are a general and principled framework for motion planning under uncertainty. Despite tremendous improvement in the scalability of POMDP solvers, long-horizon POMDPs (e.g., $\geq15$ steps) remain difficult to solve. This paper proposes a new approximate online POMDP solver, called Reference-Based Online POMDP Planning via Rapid State Space Sampling (ROP-RaS3). ROP-RaS3 uses novel extremely fast sampling-based motion planning techniques to sample the state space and generate a diverse set of macro actions online which are then used to bias belief-space sampling and infer high-quality policies without requiring exhaustive enumeration of the action space -- a fundamental constraint for modern online POMDP solvers. ROP-RaS3 is evaluated on various long-horizon POMDPs, including on a problem with a planning horizon of more than 100 steps and a problem with a 15-dimensional state space that requires more than 20 look ahead steps. In all of these problems, ROP-RaS3 substantially outperforms other state-of-the-art methods by up to multiple folds.
Combining a Meta-Policy and Monte-Carlo Planning for Scalable Type-Based Reasoning in Partially Observable Environments
Jun 09, 2023The design of autonomous agents that can interact effectively with other agents without prior coordination is a core problem in multi-agent systems. Type-based reasoning methods achieve this by maintaining a belief over a set of potential behaviours for the other agents. However, current methods are limited in that they assume full observability of the state and actions of the other agent or do not scale efficiently to larger problems with longer planning horizons. Addressing these limitations, we propose Partially Observable Type-based Meta Monte-Carlo Planning (POTMMCP) - an online Monte-Carlo Tree Search based planning method for type-based reasoning in large partially observable environments. POTMMCP incorporates a novel meta-policy for guiding search and evaluating beliefs, allowing it to search more effectively to longer horizons using less planning time. We show that our method converges to the optimal solution in the limit and empirically demonstrate that it effectively adapts online to diverse sets of other agents across a range of environments. Comparisons with the state-of-the art method on problems with up to $10^{14}$ states and $10^8$ observations indicate that POTMMCP is able to compute better solutions significantly faster.
A Surprisingly Simple Continuous-Action POMDP Solver: Lazy Cross-Entropy Search Over Policy Trees
May 14, 2023



The Partially Observable Markov Decision Process (POMDP) provides a principled framework for decision making in stochastic partially observable environments. However, computing good solutions for problems with continuous action spaces remains challenging. To ease this challenge, we propose a simple online POMDP solver, called Lazy Cross-Entropy Search Over Policy Trees (LCEOPT). At each planning step, our method uses a lazy Cross-Entropy method to search the space of policy trees, which provide a simple policy representation. Specifically, we maintain a distribution on promising finite-horizon policy trees. The distribution is iteratively updated by sampling policies, evaluating them via Monte Carlo simulation, and refitting them to the top-performing ones. Our method is lazy in the sense that it exploits the policy tree representation to avoid redundant computations in policy sampling, evaluation, and distribution update. This leads to computational savings of up to two orders of magnitude. Our LCEOPT is surprisingly simple as compared to existing state-of-the-art methods, yet empirically outperforms them on several continuous-action POMDP problems, particularly for problems with higher-dimensional action spaces.
Adaptive Discretization using Voronoi Trees for Continuous POMDPs
Feb 21, 2023



Solving continuous Partially Observable Markov Decision Processes (POMDPs) is challenging, particularly for high-dimensional continuous action spaces. To alleviate this difficulty, we propose a new sampling-based online POMDP solver, called Adaptive Discretization using Voronoi Trees (ADVT). It uses Monte Carlo Tree Search in combination with an adaptive discretization of the action space as well as optimistic optimization to efficiently sample high-dimensional continuous action spaces and compute the best action to perform. Specifically, we adaptively discretize the action space for each sampled belief using a hierarchical partition called Voronoi tree, which is a Binary Space Partitioning that implicitly maintains the partition of a cell as the Voronoi diagram of two points sampled from the cell. ADVT uses the estimated diameters of the cells to form an upper-confidence bound on the action value function within the cell, guiding the Monte Carlo Tree Search expansion and further discretization of the action space. This enables ADVT to better exploit local information with respect to the action value function, allowing faster identification of the most promising regions in the action space, compared to existing solvers. Voronoi trees keep the cost of partitioning and estimating the diameter of each cell low, even in high-dimensional spaces where many sampled points are required to cover the space well. ADVT additionally handles continuous observation spaces, by adopting an observation progressive widening strategy, along with a weighted particle representation of beliefs. Experimental results indicate that ADVT scales substantially better to high-dimensional continuous action spaces, compared to state-of-the-art methods.
Adaptive Discretization using Voronoi Trees for Continuous-Action POMDPs
Sep 13, 2022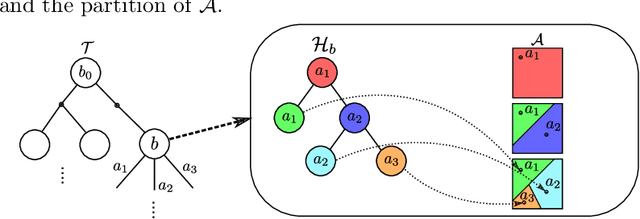
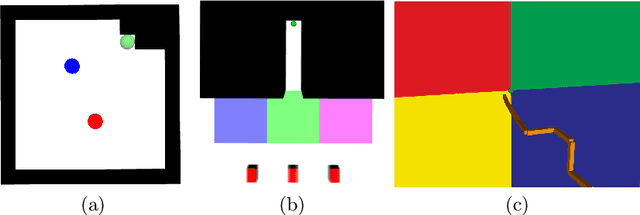
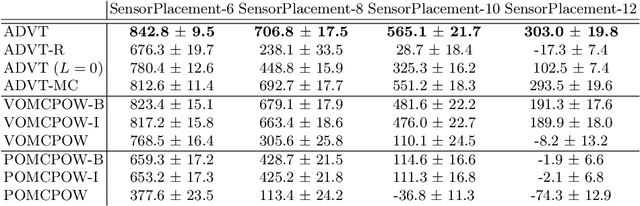
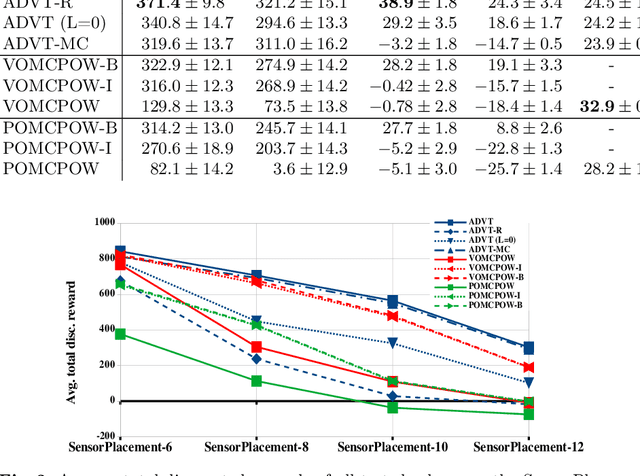
Solving Partially Observable Markov Decision Processes (POMDPs) with continuous actions is challenging, particularly for high-dimensional action spaces. To alleviate this difficulty, we propose a new sampling-based online POMDP solver, called Adaptive Discretization using Voronoi Trees (ADVT). It uses Monte Carlo Tree Search in combination with an adaptive discretization of the action space as well as optimistic optimization to efficiently sample high-dimensional continuous action spaces and compute the best action to perform. Specifically, we adaptively discretize the action space for each sampled belief using a hierarchical partition which we call a Voronoi tree. A Voronoi tree is a Binary Space Partitioning (BSP) that implicitly maintains the partition of a cell as the Voronoi diagram of two points sampled from the cell. This partitioning strategy keeps the cost of partitioning and estimating the size of each cell low, even in high-dimensional spaces where many sampled points are required to cover the space well. ADVT uses the estimated sizes of the cells to form an upper-confidence bound of the action values of the cell, and in turn uses the upper-confidence bound to guide the Monte Carlo Tree Search expansion and further discretization of the action space. This strategy enables ADVT to better exploit local information in the action space, leading to an action space discretization that is more adaptive, and hence more efficient in computing good POMDP solutions, compared to existing solvers. Experiments on simulations of four types of benchmark problems indicate that ADVT outperforms and scales substantially better to high-dimensional continuous action spaces, compared to state-of-the-art continuous action POMDP solvers.
Partially Observable Markov Decision Processes and Robotics
Jul 15, 2021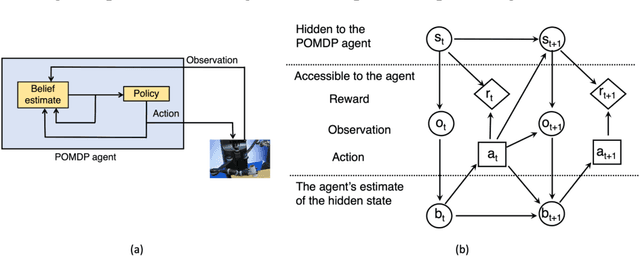

Planning under uncertainty is critical to robotics. The Partially Observable Markov Decision Process (POMDP) is a mathematical framework for such planning problems. It is powerful due to its careful quantification of the non-deterministic effects of actions and partial observability of the states. But precisely because of this, POMDP is notorious for its high computational complexity and deemed impractical for robotics. However, since early 2000, POMDPs solving capabilities have advanced tremendously, thanks to sampling-based approximate solvers. Although these solvers do not generate the optimal solution, they can compute good POMDP solutions that significantly improve the robustness of robotics systems within reasonable computational resources, thereby making POMDPs practical for many realistic robotics problems. This paper presents a review of POMDPs, emphasizing computational issues that have hindered its practicality in robotics and ideas in sampling-based solvers that have alleviated such difficulties, together with lessons learned from applying POMDPs to physical robots.