 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorized Online POMDP Planning
Oct 31, 2025Planning under partial observability is an essential capability of autonomous robots. The Partially Observable Markov Decision Process (POMDP) provides a powerful framework for planning under partial observability problems, capturing the stochastic effects of actions and the limited information available through noisy observations. POMDP solving could benefit tremendously from massive parallelization of today's hardware, but parallelizing POMDP solvers has been challenging. They rely on interleaving numerical optimization over actions with the estimation of their values, which creates dependencies and synchronization bottlenecks between parallel processes that can quickly offset the benefits of parallelization. In this paper, we propose Vectorized Online POMDP Planner (VOPP), a novel parallel online solver that leverages a recent POMDP formulation that analytically solves part of the optimization component, leaving only the estimation of expectations for numerical computation. VOPP represents all data structures related to planning as a collection of tensors and implements all planning steps as fully vectorized computations over this representation. The result is a massively parallel solver with no dependencies and synchronization bottlenecks between parallel computations. Experimental results indicate that VOPP is at least 20X more efficient in computing near-optimal solutions compared to an existing state-of-the-art parallel online solver.
A Surprisingly Simple Continuous-Action POMDP Solver: Lazy Cross-Entropy Search Over Policy Trees
May 14, 2023



The Partially Observable Markov Decision Process (POMDP) provides a principled framework for decision making in stochastic partially observable environments. However, computing good solutions for problems with continuous action spaces remains challenging. To ease this challenge, we propose a simple online POMDP solver, called Lazy Cross-Entropy Search Over Policy Trees (LCEOPT). At each planning step, our method uses a lazy Cross-Entropy method to search the space of policy trees, which provide a simple policy representation. Specifically, we maintain a distribution on promising finite-horizon policy trees. The distribution is iteratively updated by sampling policies, evaluating them via Monte Carlo simulation, and refitting them to the top-performing ones. Our method is lazy in the sense that it exploits the policy tree representation to avoid redundant computations in policy sampling, evaluation, and distribution update. This leads to computational savings of up to two orders of magnitude. Our LCEOPT is surprisingly simple as compared to existing state-of-the-art methods, yet empirically outperforms them on several continuous-action POMDP problems, particularly for problems with higher-dimensional action spaces.
A Flow-Based Generative Model for Rare-Event Simulation
May 13, 2023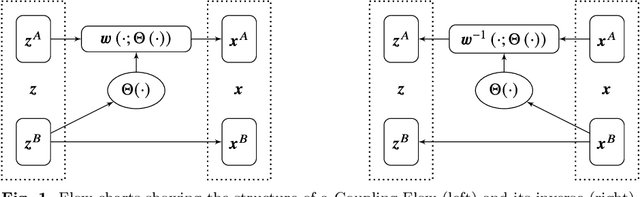
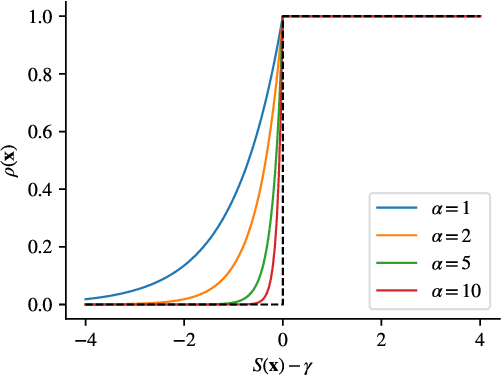


Solving decision problems in complex, stochastic environments is often achieved by estimating the expected outcome of decisions via Monte Carlo sampling. However, sampling may overlook rare, but important events, which can severely impact the decision making process. We present a method in which a Normalizing Flow generative model is trained to simulate samples directly from a conditional distribution given that a rare event occurs. By utilizing Coupling Flows, our model can, in principle, approximate any sampling distribution arbitrarily well. By combining the approximation method with Importance Sampling, highly accurate estimates of complicated integrals and expectations can be obtained. We include several examples to demonstrate how the method can be used for efficient sampling and estimation, even in high-dimensional and rare-event settings. We illustrate that by simulating directly from a rare-event distribution significant insight can be gained into the way rare events happen.
Adaptive Discretization using Voronoi Trees for Continuous POMDPs
Feb 21, 2023



Solving continuous Partially Observable Markov Decision Processes (POMDPs) is challenging, particularly for high-dimensional continuous action spaces. To alleviate this difficulty, we propose a new sampling-based online POMDP solver, called Adaptive Discretization using Voronoi Trees (ADVT). It uses Monte Carlo Tree Search in combination with an adaptive discretization of the action space as well as optimistic optimization to efficiently sample high-dimensional continuous action spaces and compute the best action to perform. Specifically, we adaptively discretize the action space for each sampled belief using a hierarchical partition called Voronoi tree, which is a Binary Space Partitioning that implicitly maintains the partition of a cell as the Voronoi diagram of two points sampled from the cell. ADVT uses the estimated diameters of the cells to form an upper-confidence bound on the action value function within the cell, guiding the Monte Carlo Tree Search expansion and further discretization of the action space. This enables ADVT to better exploit local information with respect to the action value function, allowing faster identification of the most promising regions in the action space, compared to existing solvers. Voronoi trees keep the cost of partitioning and estimating the diameter of each cell low, even in high-dimensional spaces where many sampled points are required to cover the space well. ADVT additionally handles continuous observation spaces, by adopting an observation progressive widening strategy, along with a weighted particle representation of beliefs. Experimental results indicate that ADVT scales substantially better to high-dimensional continuous action spaces, compared to state-of-the-art methods.
Adaptive Discretization using Voronoi Trees for Continuous-Action POMDPs
Sep 13, 2022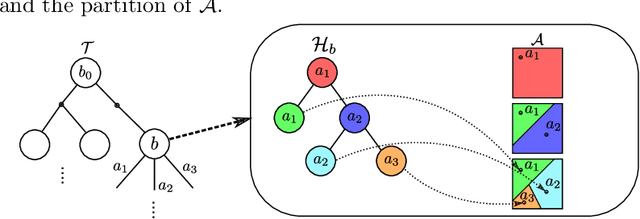
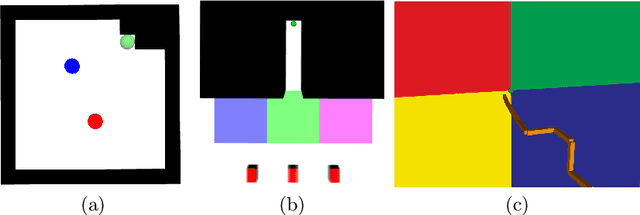
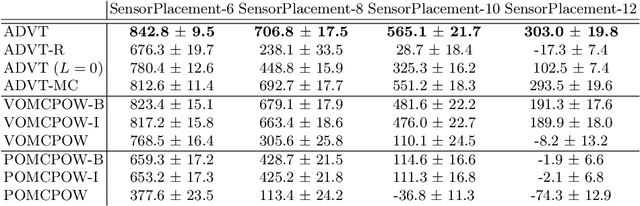
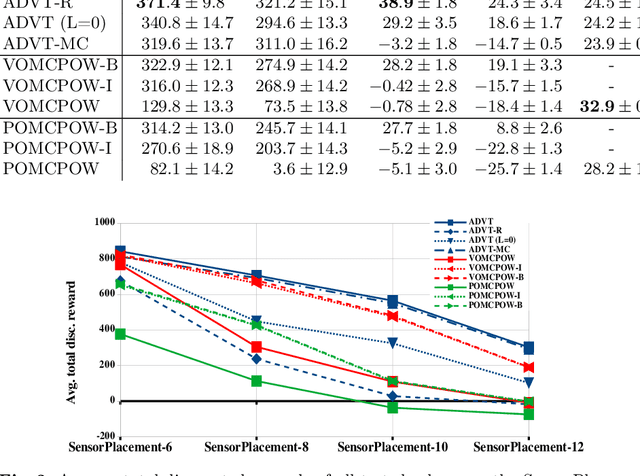
Solving Partially Observable Markov Decision Processes (POMDPs) with continuous actions is challenging, particularly for high-dimensional action spaces. To alleviate this difficulty, we propose a new sampling-based online POMDP solver, called Adaptive Discretization using Voronoi Trees (ADVT). It uses Monte Carlo Tree Search in combination with an adaptive discretization of the action space as well as optimistic optimization to efficiently sample high-dimensional continuous action spaces and compute the best action to perform. Specifically, we adaptively discretize the action space for each sampled belief using a hierarchical partition which we call a Voronoi tree. A Voronoi tree is a Binary Space Partitioning (BSP) that implicitly maintains the partition of a cell as the Voronoi diagram of two points sampled from the cell. This partitioning strategy keeps the cost of partitioning and estimating the size of each cell low, even in high-dimensional spaces where many sampled points are required to cover the space well. ADVT uses the estimated sizes of the cells to form an upper-confidence bound of the action values of the cell, and in turn uses the upper-confidence bound to guide the Monte Carlo Tree Search expansion and further discretization of the action space. This strategy enables ADVT to better exploit local information in the action space, leading to an action space discretization that is more adaptive, and hence more efficient in computing good POMDP solutions, compared to existing solvers. Experiments on simulations of four types of benchmark problems indicate that ADVT outperforms and scales substantially better to high-dimensional continuous action spaces, compared to state-of-the-art continuous action POMDP solvers.
An On-Line POMDP Solver for Continuous Observation Spaces
Nov 04, 2020

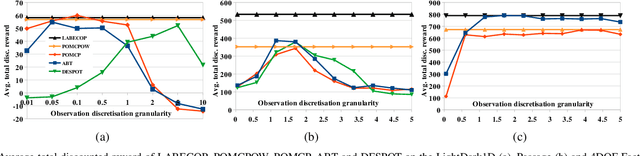

Planning under partial obervability is essential for autonomous robots. A principled way to address such planning problems is the Partially Observable Markov Decision Process (POMDP). Although solving POMDPs is computationally intractable, substantial advancements have been achieved in developing approximate POMDP solvers in the past two decades. However, computing robust solutions for problems with continuous observation spaces remains challenging. Most on-line solvers rely on discretising the observation space or artificially limiting the number of observations that are considered during planning to compute tractable policies. In this paper we propose a new on-line POMDP solver, called Lazy Belief Extraction for Continuous POMDPs (LABECOP), that combines methods from Monte-Carlo-Tree-Search and particle filtering to construct a policy reprentation which doesn't require discretised observation spaces and avoids limiting the number of observations considered during planning. Experiments on three different problems involving continuous observation spaces indicate that LABECOP performs similar or better than state-of-the-art POMDP solvers.
Non-Linearity Measure for POMDP-based Motion Planning
May 29, 2020
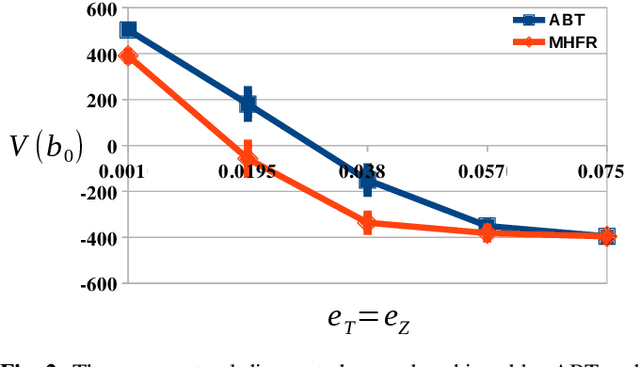

Motion planning under uncertainty is essential for reliable robot operation. Despite substantial advances over the past decade, the problem remains difficult for systems with complex dynamics. Most state-of-the-art methods perform search that relies on a large number of forward simulations. For systems with complex dynamics, this generally require costly numerical integrations which significantly slows down the planning process. Linearization-based methods have been proposed that can alleviate the above problem. However, it is not clear how linearization affects the quality of the generated motion strategy, and when such simplifications are admissible. We propose a non-linearity measure, called Statistical-distance-based Non-linearity Measure (SNM), that can identify where linearization is beneficial and where it should be avoided. We show that when the problem is framed as the Partially Observable Markov Decision Process, the value difference between the optimal strategy for the original model and the linearized model can be upper bounded by a function linear in SNM. Comparisons with an existing measure on various scenarios indicate that SNM is more suitable in estimating the effectiveness of linearization-based solvers. To test the applicability of SNM in motion planning, we propose a simple on-line planner that uses SNM as a heuristic to switch between a general and a linearization-based solver. Results on a car-like robot with second order dynamics and 4-DOFs and 7-DOFs torque-controlled manipulators indicate that SNM can appropriately decide if and when a linearization-based solver should be used.
Multilevel Monte-Carlo for Solving POMDPs Online
Jul 23, 2019
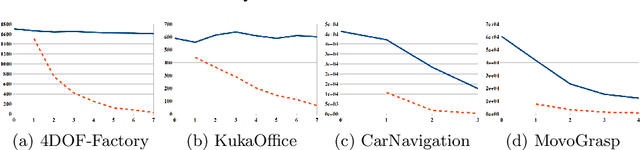
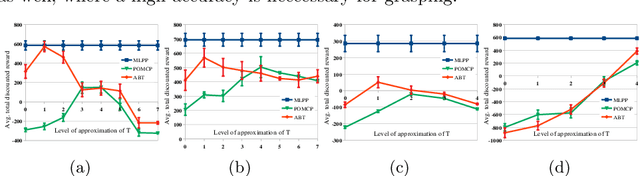
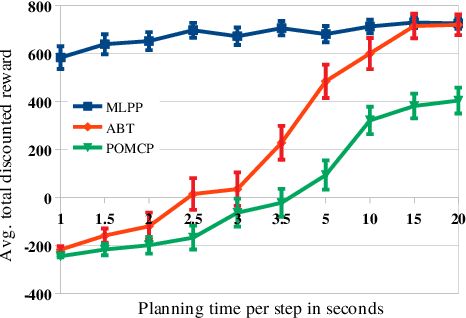
Planning under partial obervability is essential for autonomous robots. A principled way to address such planning problems is the Partially Observable Markov Decision Process (POMDP). Although solving POMDPs is computationally intractable, substantial advancements have been achieved in developing approximate POMDP solvers in the past two decades. However, computing robust solutions for systems with complex dynamics remain challenging. Most on-line solvers rely on a large number of forward-simulations and standard Monte-Carlo methods to compute the expected outcomes of actions the robot can perform. For systems with complex dynamics, e.g., those with non-linear dynamics that admit no closed form solution, even a single forward simulation can be prohibitively expensive. Of course, this issue exacerbates for problems with long planning horizons. This paper aims to alleviate the above difficulty. To this end, we propose a new on-line POMDP solver, called Multilevel POMDP Planner (MLPP), that combines the commonly known Monte-Carlo-Tree-Search with the concept of Multilevel Monte-Carlo to speed-up our capability in generating approximately optimal solutions for POMDPs with complex dynamics. Experiments on four different problems of POMDP-based torque control, navigation and grasping indicate that MLPP substantially outperforms state-of-the-art POMDP solvers.