 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Graph Few-shot Class Incremental Learning
Nov 11, 2024



Node classification with Graph Neural Networks (GNN) under a fixed set of labels is well known in contrast to Graph Few-Shot Class Incremental Learning (GFSCIL), which involves learning a GNN classifier as graph nodes and classes growing over time sporadically. We introduce inductive GFSCIL that continually learns novel classes with newly emerging nodes while maintaining performance on old classes without accessing previous data. This addresses the practical concern of transductive GFSCIL, which requires storing the entire graph with historical data. Compared to the transductive GFSCIL, the inductive setting exacerbates catastrophic forgetting due to inaccessible previous data during incremental training, in addition to overfitting issue caused by label sparsity. Thus, we propose a novel method, called Topology-based class Augmentation and Prototype calibration (TAP). To be specific, it first creates a triple-branch multi-topology class augmentation method to enhance model generalization ability. As each incremental session receives a disjoint subgraph with nodes of novel classes, the multi-topology class augmentation method helps replicate such a setting in the base session to boost backbone versatility. In incremental learning, given the limited number of novel class samples, we propose an iterative prototype calibration to improve the separation of class prototypes. Furthermore, as backbone fine-tuning poses the feature distribution drift, prototypes of old classes start failing over time, we propose the prototype shift method for old classes to compensate for the drift. We showcase the proposed method on four datasets.
Robust Loss Functions for Training Decision Trees with Noisy Labels
Dec 20, 2023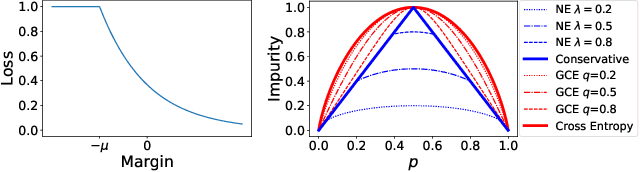


We consider training decision trees using noisily labeled data, focusing on loss functions that can lead to robust learning algorithms. Our contributions are threefold. First, we offer novel theoretical insights on the robustness of many existing loss functions in the context of decision tree learning. We show that some of the losses belong to a class of what we call conservative losses, and the conservative losses lead to an early stopping behavior during training and noise-tolerant predictions during testing. Second, we introduce a framework for constructing robust loss functions, called distribution losses. These losses apply percentile-based penalties based on an assumed margin distribution, and they naturally allow adapting to different noise rates via a robustness parameter. In particular, we introduce a new loss called the negative exponential loss, which leads to an efficient greedy impurity-reduction learning algorithm. Lastly, our experiments on multiple datasets and noise settings validate our theoretical insight and the effectiveness of our adaptive negative exponential loss.
Fast Controllable Diffusion Models for Undersampled MRI Reconstruction
Dec 01, 2023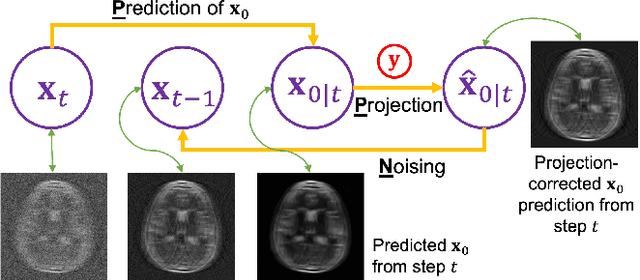



Supervised deep learning methods have shown promise in undersampled Magnetic Resonance Imaging (MRI) reconstruction, but their requirement for paired data limits their generalizability to the diverse MRI acquisition parameters. Recently, unsupervised controllable generative diffusion models have been applied to undersampled MRI reconstruction, without paired data or model retraining for different MRI acquisitions. However, diffusion models are generally slow in sampling and state-of-the-art acceleration techniques can lead to sub-optimal results when directly applied to the controllable generation process. This study introduces a new algorithm called Predictor-Projector-Noisor (PPN), which enhances and accelerates controllable generation of diffusion models for undersampled MRI reconstruction. Our results demonstrate that PPN produces high-fidelity MR images that conform to undersampled k-space measurements with significantly shorter reconstruction time than other controllable sampling methods. In addition, the unsupervised PPN accelerated diffusion models are adaptable to different MRI acquisition parameters, making them more practical for clinical use than supervised learning techniques.
A Surprisingly Simple Continuous-Action POMDP Solver: Lazy Cross-Entropy Search Over Policy Trees
May 14, 2023



The Partially Observable Markov Decision Process (POMDP) provides a principled framework for decision making in stochastic partially observable environments. However, computing good solutions for problems with continuous action spaces remains challenging. To ease this challenge, we propose a simple online POMDP solver, called Lazy Cross-Entropy Search Over Policy Trees (LCEOPT). At each planning step, our method uses a lazy Cross-Entropy method to search the space of policy trees, which provide a simple policy representation. Specifically, we maintain a distribution on promising finite-horizon policy trees. The distribution is iteratively updated by sampling policies, evaluating them via Monte Carlo simulation, and refitting them to the top-performing ones. Our method is lazy in the sense that it exploits the policy tree representation to avoid redundant computations in policy sampling, evaluation, and distribution update. This leads to computational savings of up to two orders of magnitude. Our LCEOPT is surprisingly simple as compared to existing state-of-the-art methods, yet empirically outperforms them on several continuous-action POMDP problems, particularly for problems with higher-dimensional action spaces.
Adaptive Discretization using Voronoi Trees for Continuous POMDPs
Feb 21, 2023



Solving continuous Partially Observable Markov Decision Processes (POMDPs) is challenging, particularly for high-dimensional continuous action spaces. To alleviate this difficulty, we propose a new sampling-based online POMDP solver, called Adaptive Discretization using Voronoi Trees (ADVT). It uses Monte Carlo Tree Search in combination with an adaptive discretization of the action space as well as optimistic optimization to efficiently sample high-dimensional continuous action spaces and compute the best action to perform. Specifically, we adaptively discretize the action space for each sampled belief using a hierarchical partition called Voronoi tree, which is a Binary Space Partitioning that implicitly maintains the partition of a cell as the Voronoi diagram of two points sampled from the cell. ADVT uses the estimated diameters of the cells to form an upper-confidence bound on the action value function within the cell, guiding the Monte Carlo Tree Search expansion and further discretization of the action space. This enables ADVT to better exploit local information with respect to the action value function, allowing faster identification of the most promising regions in the action space, compared to existing solvers. Voronoi trees keep the cost of partitioning and estimating the diameter of each cell low, even in high-dimensional spaces where many sampled points are required to cover the space well. ADVT additionally handles continuous observation spaces, by adopting an observation progressive widening strategy, along with a weighted particle representation of beliefs. Experimental results indicate that ADVT scales substantially better to high-dimensional continuous action spaces, compared to state-of-the-art methods.
Positive-Unlabeled Learning using Random Forests via Recursive Greedy Risk Minimization
Oct 16, 2022
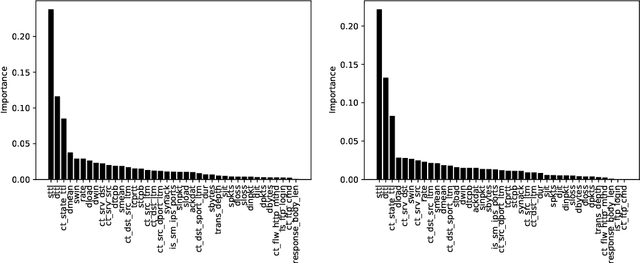
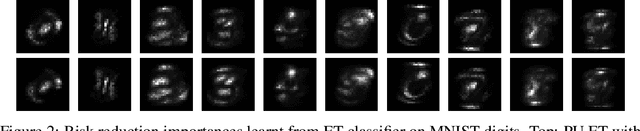
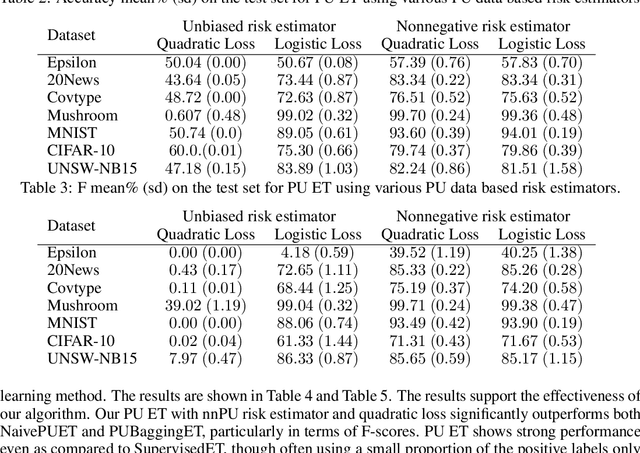
The need to learn from positive and unlabeled data, or PU learning, arises in many applications and has attracted increasing interest. While random forests are known to perform well on many tasks with positive and negative data, recent PU algorithms are generally based on deep neural networks, and the potential of tree-based PU learning is under-explored. In this paper, we propose new random forest algorithms for PU-learning. Key to our approach is a new interpretation of decision tree algorithms for positive and negative data as \emph{recursive greedy risk minimization algorithms}. We extend this perspective to the PU setting to develop new decision tree learning algorithms that directly minimizes PU-data based estimators for the expected risk. This allows us to develop an efficient PU random forest algorithm, PU extra trees. Our approach features three desirable properties: it is robust to the choice of the loss function in the sense that various loss functions lead to the same decision trees; it requires little hyperparameter tuning as compared to neural network based PU learning; it supports a feature importance that directly measures a feature's contribution to risk minimization. Our algorithms demonstrate strong performance on several datasets. Our code is available at \url{https://github.com/puetpaper/PUExtraTrees}.
Adaptive Discretization using Voronoi Trees for Continuous-Action POMDPs
Sep 13, 2022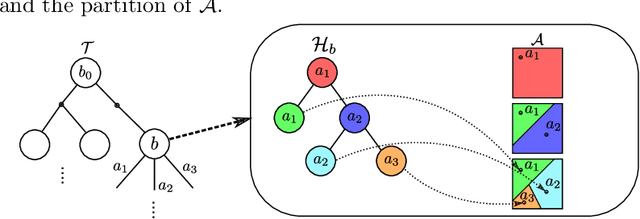
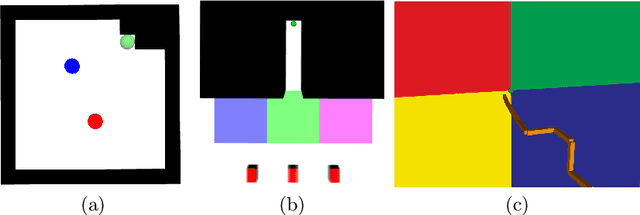
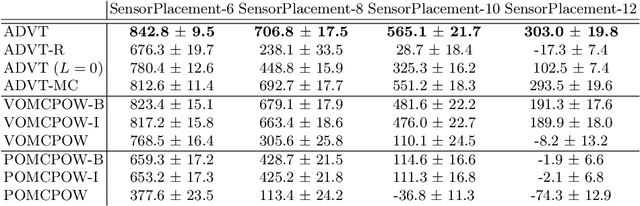
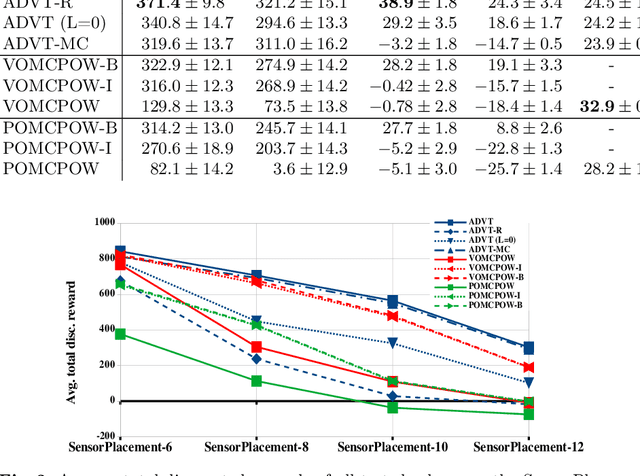
Solving Partially Observable Markov Decision Processes (POMDPs) with continuous actions is challenging, particularly for high-dimensional action spaces. To alleviate this difficulty, we propose a new sampling-based online POMDP solver, called Adaptive Discretization using Voronoi Trees (ADVT). It uses Monte Carlo Tree Search in combination with an adaptive discretization of the action space as well as optimistic optimization to efficiently sample high-dimensional continuous action spaces and compute the best action to perform. Specifically, we adaptively discretize the action space for each sampled belief using a hierarchical partition which we call a Voronoi tree. A Voronoi tree is a Binary Space Partitioning (BSP) that implicitly maintains the partition of a cell as the Voronoi diagram of two points sampled from the cell. This partitioning strategy keeps the cost of partitioning and estimating the size of each cell low, even in high-dimensional spaces where many sampled points are required to cover the space well. ADVT uses the estimated sizes of the cells to form an upper-confidence bound of the action values of the cell, and in turn uses the upper-confidence bound to guide the Monte Carlo Tree Search expansion and further discretization of the action space. This strategy enables ADVT to better exploit local information in the action space, leading to an action space discretization that is more adaptive, and hence more efficient in computing good POMDP solutions, compared to existing solvers. Experiments on simulations of four types of benchmark problems indicate that ADVT outperforms and scales substantially better to high-dimensional continuous action spaces, compared to state-of-the-art continuous action POMDP solvers.
A Boosting Algorithm for Positive-Unlabeled Learning
May 19, 2022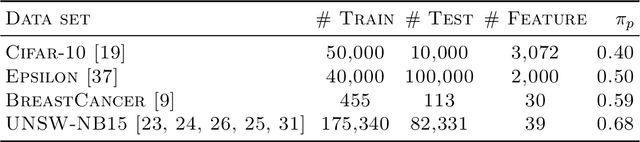
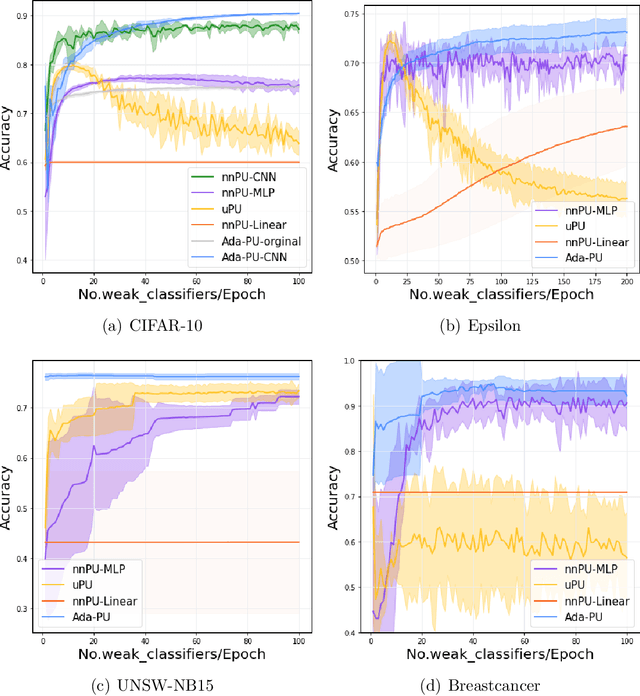

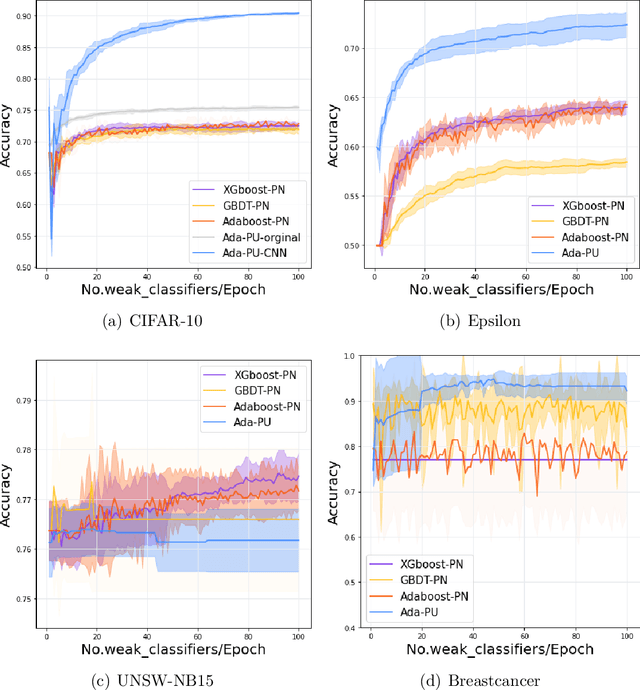
Positive-unlabeled (PU) learning deals with binary classification problems when only positive (P) and unlabeled (U) data are available. A lot of PU methods based on linear models and neural networks have been proposed; however, there still lacks study on how the theoretically sound boosting-style algorithms could work with P and U data. Considering that in some scenarios when neural networks cannot perform as good as boosting algorithms even with fully-supervised data, we propose a novel boosting algorithm for PU learning: Ada-PU, which compares against neural networks. Ada-PU follows the general procedure of AdaBoost while two different distributions of P data are maintained and updated. After a weak classifier is learned on the newly updated distribution, the corresponding combining weight for the final ensemble is estimated using only PU data. We demonstrated that with a smaller set of base classifiers, the proposed method is guaranteed to keep the theoretical properties of boosting algorithm. In experiments, we showed that Ada-PU outperforms neural networks on benchmark PU datasets. We also study a real-world dataset UNSW-NB15 in cyber security and demonstrated that Ada-PU has superior performance for malicious activities detection.
LiMIIRL: Lightweight Multiple-Intent Inverse Reinforcement Learning
Jun 03, 2021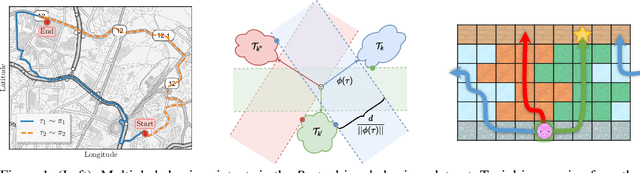
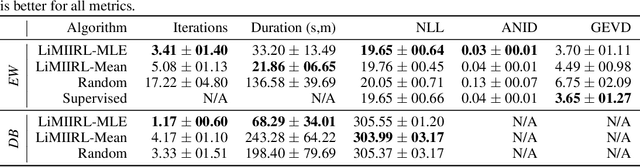
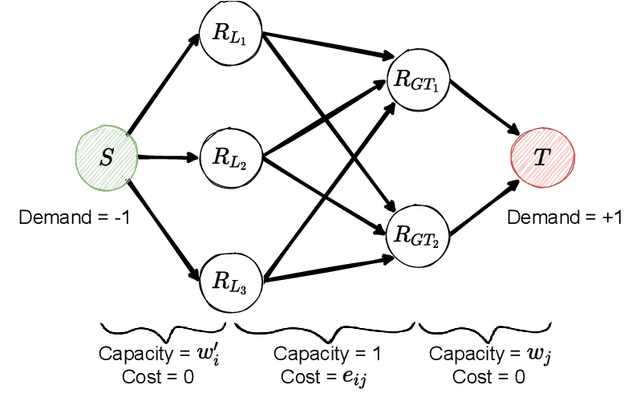
Multiple-Intent Inverse Reinforcement Learning (MI-IRL) seeks to find a reward function ensemble to rationalize demonstrations of different but unlabelled intents. Within the popular expectation maximization (EM) framework for learning probabilistic MI-IRL models, we present a warm-start strategy based on up-front clustering of the demonstrations in feature space. Our theoretical analysis shows that this warm-start solution produces a near-optimal reward ensemble, provided the behavior modes satisfy mild separation conditions. We also propose a MI-IRL performance metric that generalizes the popular Expected Value Difference measure to directly assesses learned rewards against the ground-truth reward ensemble. Our metric elegantly addresses the difficulty of pairing up learned and ground truth rewards via a min-cost flow formulation, and is efficiently computable. We also develop a MI-IRL benchmark problem that allows for more comprehensive algorithmic evaluations. On this problem, we find our MI-IRL warm-start strategy helps avoid poor quality local minima reward ensembles, resulting in a significant improvement in behavior clustering. Our extensive sensitivity analysis demonstrates that the quality of the learned reward ensembles is improved under various settings, including cases where our theoretical assumptions do not necessarily hold. Finally, we demonstrate the effectiveness of our methods by discovering distinct driving styles in a large real-world dataset of driver GPS trajectories.
Revisiting Maximum Entropy Inverse Reinforcement Learning: New Perspectives and Algorithms
Dec 01, 2020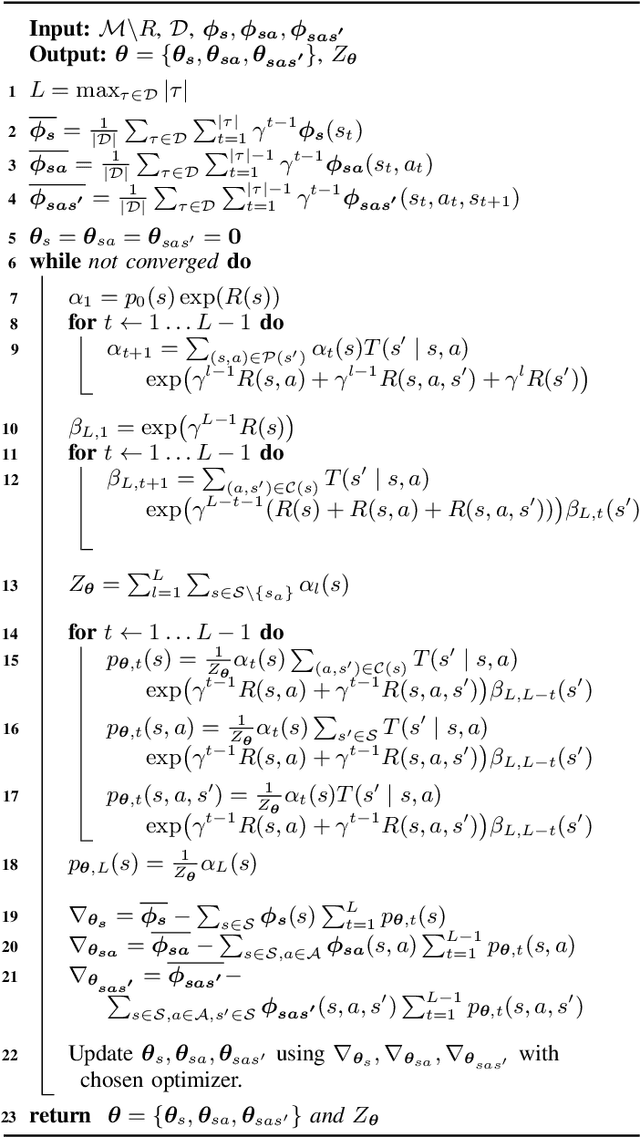
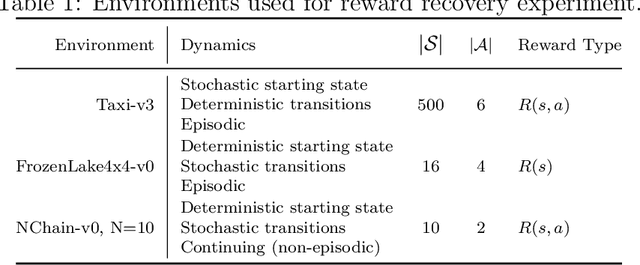
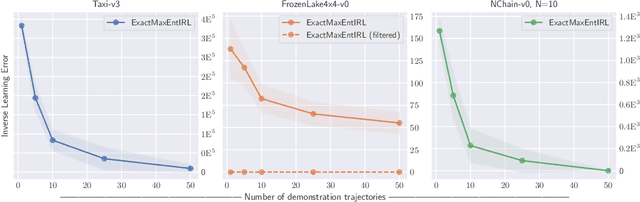
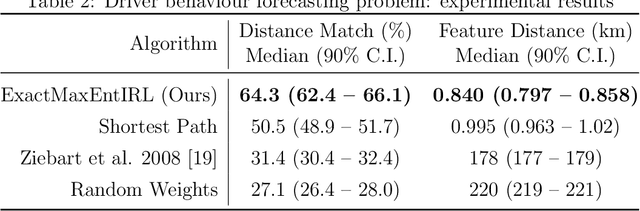
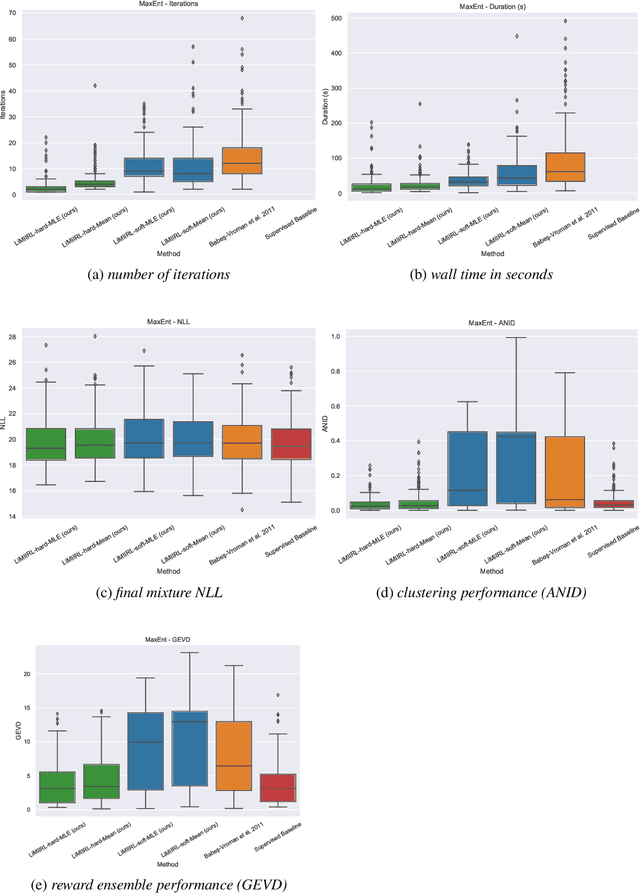
We provide new perspectives and inference algorithms for Maximum Entropy (MaxEnt) Inverse Reinforcement Learning (IRL), which provides a principled method to find a most non-committal reward function consistent with given expert demonstrations, among many consistent reward functions. We first present a generalized MaxEnt formulation based on minimizing a KL-divergence instead of maximizing an entropy. This improves the previous heuristic derivation of the MaxEnt IRL model (for stochastic MDPs), allows a unified view of MaxEnt IRL and Relative Entropy IRL, and leads to a model-free learning algorithm for the MaxEnt IRL model. Second, a careful review of existing inference algorithms and implementations showed that they approximately compute the marginals required for learning the model. We provide examples to illustrate this, and present an efficient and exact inference algorithm. Our algorithm can handle variable length demonstrations; in addition, while a basic version takes time quadratic in the maximum demonstration length L, an improved version of this algorithm reduces this to linear using a padding trick. Experiments show that our exact algorithm improves reward learning as compared to the approximate ones. Furthermore, our algorithm scales up to a large, real-world dataset involving driver behaviour forecasting. We provide an optimized implementation compatible with the OpenAI Gym interface. Our new insight and algorithms could possibly lead to further interest and exploration of the original MaxEnt IRL model.