 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiMIIRL: Lightweight Multiple-Intent Inverse Reinforcement Learning
Paper and Code
Jun 03, 2021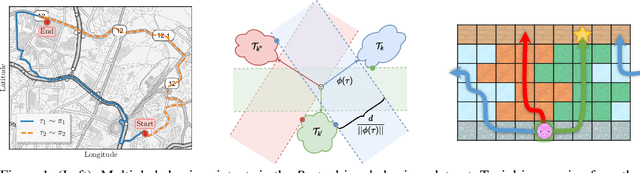
Multiple-Intent Inverse Reinforcement Learning (MI-IRL) seeks to find a reward function ensemble to rationalize demonstrations of different but unlabelled intents. Within the popular expectation maximization (EM) framework for learning probabilistic MI-IRL models, we present a warm-start strategy based on up-front clustering of the demonstrations in feature space. Our theoretical analysis shows that this warm-start solution produces a near-optimal reward ensemble, provided the behavior modes satisfy mild separation conditions. We also propose a MI-IRL performance metric that generalizes the popular Expected Value Difference measure to directly assesses learned rewards against the ground-truth reward ensemble. Our metric elegantly addresses the difficulty of pairing up learned and ground truth rewards via a min-cost flow formulation, and is efficiently computable. We also develop a MI-IRL benchmark problem that allows for more comprehensive algorithmic evaluations. On this problem, we find our MI-IRL warm-start strategy helps avoid poor quality local minima reward ensembles, resulting in a significant improvement in behavior clustering. Our extensive sensitivity analysis demonstrates that the quality of the learned reward ensembles is improved under various settings, including cases where our theoretical assumptions do not necessarily hold. Finally, we demonstrate the effectiveness of our methods by discovering distinct driving styles in a large real-world dataset of driver GPS trajectories.