 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscerning What Matters: A Multi-Dimensional Assessment of Moral Competence in LLMs
Jun 16, 2025Moral competence is the ability to act in accordance with moral principles. As large language models (LLMs) are increasingly deployed in situations demanding moral competence, there is increasing interest in evaluating this ability empirically. We review existing literature and identify three significant shortcoming: (i) Over-reliance on prepackaged moral scenarios with explicitly highlighted moral features; (ii) Focus on verdict prediction rather than moral reasoning; and (iii) Inadequate testing of models' (in)ability to recognize when additional information is needed. Grounded in philosophical research on moral skill, we then introduce a novel method for assessing moral competence in LLMs. Our approach moves beyond simple verdict comparisons to evaluate five dimensions of moral competence: identifying morally relevant features, weighting their importance, assigning moral reasons to these features, synthesizing coherent moral judgments, and recognizing information gaps. We conduct two experiments comparing six leading LLMs against non-expert humans and professional philosophers. In our first experiment using ethical vignettes standard to existing work, LLMs generally outperformed non-expert humans across multiple dimensions of moral reasoning. However, our second experiment, featuring novel scenarios designed to test moral sensitivity by embedding relevant features among irrelevant details, revealed a striking reversal: several LLMs performed significantly worse than humans. Our findings suggest that current evaluations may substantially overestimate LLMs' moral reasoning capabilities by eliminating the task of discerning moral relevance from noisy information, which we take to be a prerequisite for genuine moral skill. This work provides a more nuanced framework for assessing AI moral competence and highlights important directions for improving moral competence in advanced AI systems.
Measuring Misogyny in Natural Language Generation: Preliminary Results from a Case Study on two Reddit Communities
Dec 06, 2023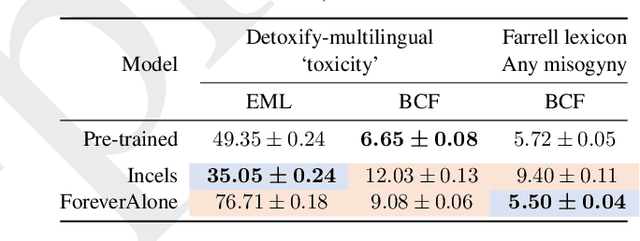
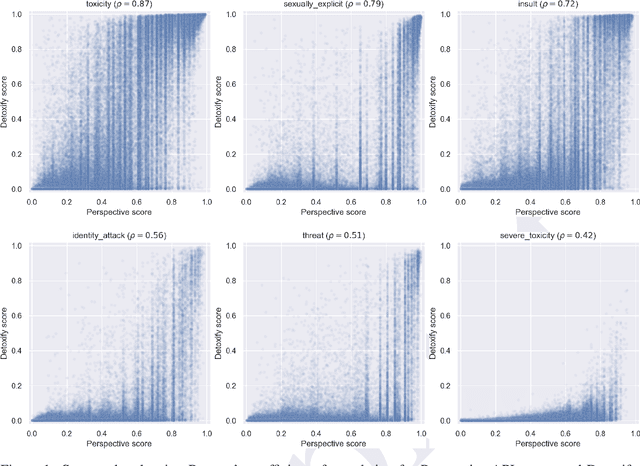


Generic `toxicity' classifiers continue to be used for evaluating the potential for harm in natural language generation, despite mounting evidence of their shortcomings. We consider the challenge of measuring misogyny in natural language generation, and argue that generic `toxicity' classifiers are inadequate for this task. We use data from two well-characterised `Incel' communities on Reddit that differ primarily in their degrees of misogyny to construct a pair of training corpora which we use to fine-tune two language models. We show that an open source `toxicity' classifier is unable to distinguish meaningfully between generations from these models. We contrast this with a misogyny-specific lexicon recently proposed by feminist subject-matter experts, demonstrating that, despite the limitations of simple lexicon-based approaches, this shows promise as a benchmark to evaluate language models for misogyny, and that it is sensitive enough to reveal the known differences in these Reddit communities. Our preliminary findings highlight the limitations of a generic approach to evaluating harms, and further emphasise the need for careful benchmark design and selection in natural language evaluation.
LiMIIRL: Lightweight Multiple-Intent Inverse Reinforcement Learning
Jun 03, 2021
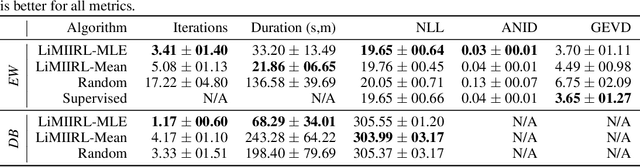
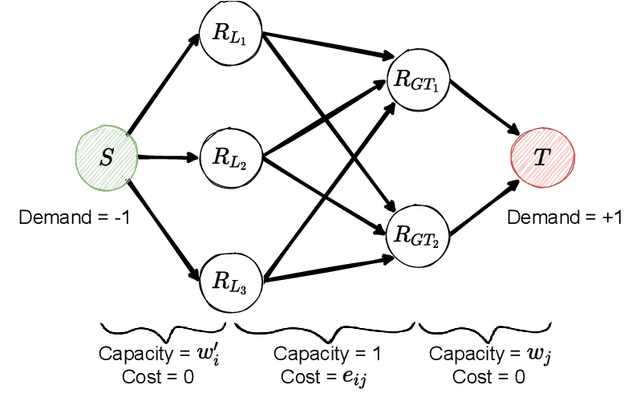
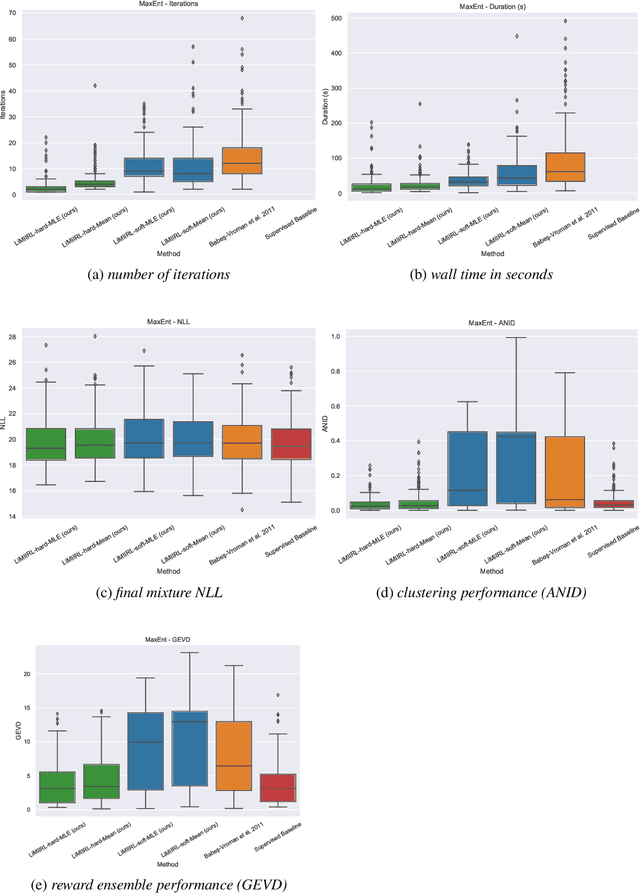
Multiple-Intent Inverse Reinforcement Learning (MI-IRL) seeks to find a reward function ensemble to rationalize demonstrations of different but unlabelled intents. Within the popular expectation maximization (EM) framework for learning probabilistic MI-IRL models, we present a warm-start strategy based on up-front clustering of the demonstrations in feature space. Our theoretical analysis shows that this warm-start solution produces a near-optimal reward ensemble, provided the behavior modes satisfy mild separation conditions. We also propose a MI-IRL performance metric that generalizes the popular Expected Value Difference measure to directly assesses learned rewards against the ground-truth reward ensemble. Our metric elegantly addresses the difficulty of pairing up learned and ground truth rewards via a min-cost flow formulation, and is efficiently computable. We also develop a MI-IRL benchmark problem that allows for more comprehensive algorithmic evaluations. On this problem, we find our MI-IRL warm-start strategy helps avoid poor quality local minima reward ensembles, resulting in a significant improvement in behavior clustering. Our extensive sensitivity analysis demonstrates that the quality of the learned reward ensembles is improved under various settings, including cases where our theoretical assumptions do not necessarily hold. Finally, we demonstrate the effectiveness of our methods by discovering distinct driving styles in a large real-world dataset of driver GPS trajectories.
Revisiting Maximum Entropy Inverse Reinforcement Learning: New Perspectives and Algorithms
Dec 01, 2020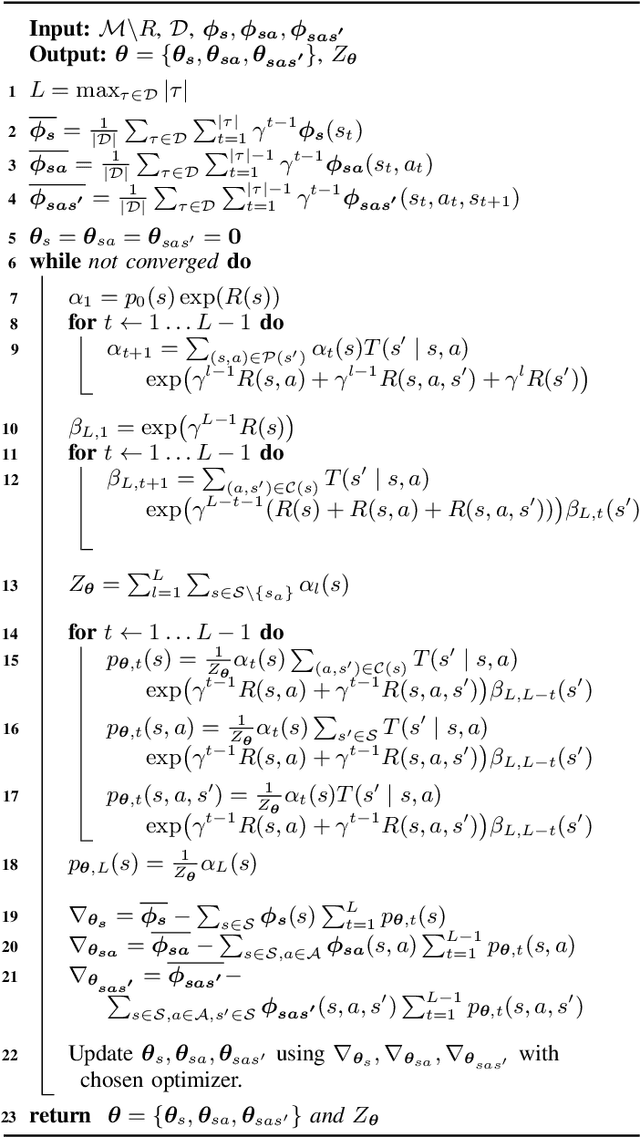
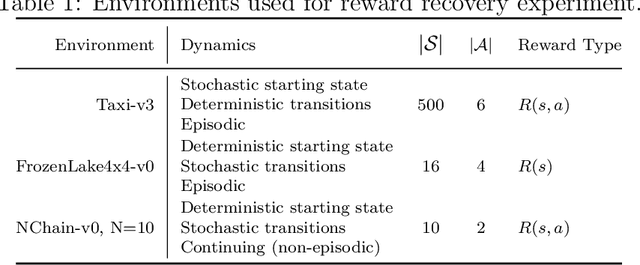
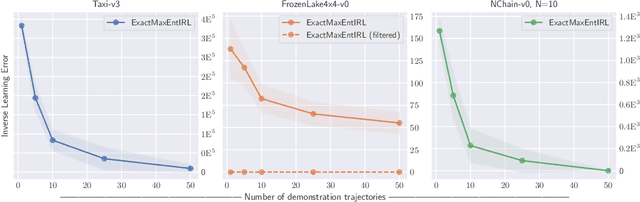
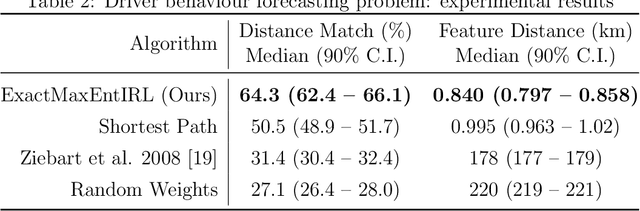
We provide new perspectives and inference algorithms for Maximum Entropy (MaxEnt) Inverse Reinforcement Learning (IRL), which provides a principled method to find a most non-committal reward function consistent with given expert demonstrations, among many consistent reward functions. We first present a generalized MaxEnt formulation based on minimizing a KL-divergence instead of maximizing an entropy. This improves the previous heuristic derivation of the MaxEnt IRL model (for stochastic MDPs), allows a unified view of MaxEnt IRL and Relative Entropy IRL, and leads to a model-free learning algorithm for the MaxEnt IRL model. Second, a careful review of existing inference algorithms and implementations showed that they approximately compute the marginals required for learning the model. We provide examples to illustrate this, and present an efficient and exact inference algorithm. Our algorithm can handle variable length demonstrations; in addition, while a basic version takes time quadratic in the maximum demonstration length L, an improved version of this algorithm reduces this to linear using a padding trick. Experiments show that our exact algorithm improves reward learning as compared to the approximate ones. Furthermore, our algorithm scales up to a large, real-world dataset involving driver behaviour forecasting. We provide an optimized implementation compatible with the OpenAI Gym interface. Our new insight and algorithms could possibly lead to further interest and exploration of the original MaxEnt IRL model.