 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Misogyny in Natural Language Generation: Preliminary Results from a Case Study on two Reddit Communities
Dec 06, 2023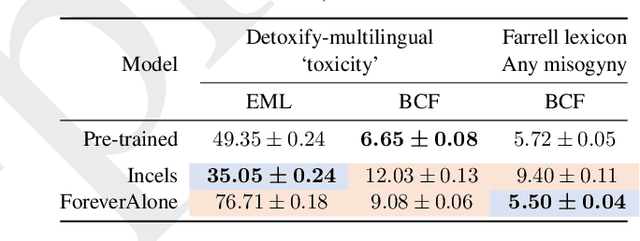
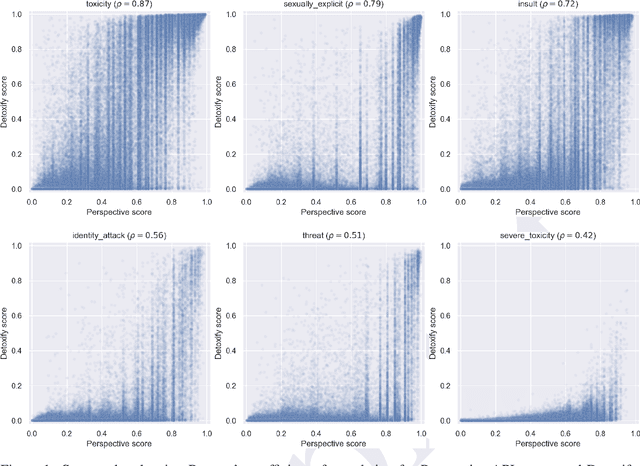


Generic `toxicity' classifiers continue to be used for evaluating the potential for harm in natural language generation, despite mounting evidence of their shortcomings. We consider the challenge of measuring misogyny in natural language generation, and argue that generic `toxicity' classifiers are inadequate for this task. We use data from two well-characterised `Incel' communities on Reddit that differ primarily in their degrees of misogyny to construct a pair of training corpora which we use to fine-tune two language models. We show that an open source `toxicity' classifier is unable to distinguish meaningfully between generations from these models. We contrast this with a misogyny-specific lexicon recently proposed by feminist subject-matter experts, demonstrating that, despite the limitations of simple lexicon-based approaches, this shows promise as a benchmark to evaluate language models for misogyny, and that it is sensitive enough to reveal the known differences in these Reddit communities. Our preliminary findings highlight the limitations of a generic approach to evaluating harms, and further emphasise the need for careful benchmark design and selection in natural language evaluation.
Misogynistic Tweet Detection: Modelling CNN with Small Datasets
Aug 28, 2020
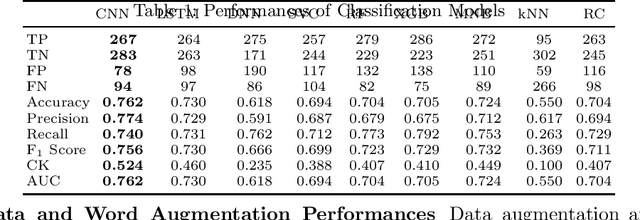

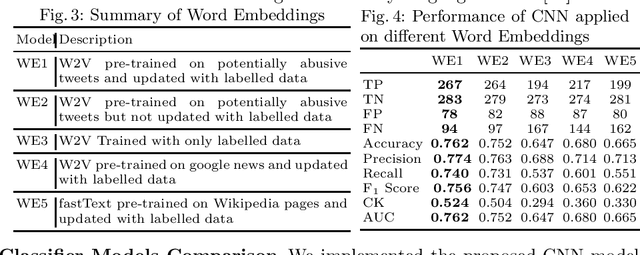
Online abuse directed towards women on the social media platform Twitter has attracted considerable attention in recent years. An automated method to effectively identify misogynistic abuse could improve our understanding of the patterns, driving factors, and effectiveness of responses associated with abusive tweets over a sustained time period. However, training a neural network (NN) model with a small set of labelled data to detect misogynistic tweets is difficult. This is partly due to the complex nature of tweets which contain misogynistic content, and the vast number of parameters needed to be learned in a NN model. We have conducted a series of experiments to investigate how to train a NN model to detect misogynistic tweets effectively. In particular, we have customised and regularised a Convolutional Neural Network (CNN) architecture and shown that the word vectors pre-trained on a task-specific domain can be used to train a CNN model effectively when a small set of labelled data is available. A CNN model trained in this way yields an improved accuracy over the state-of-the-art models.