 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Misogyny in Natural Language Generation: Preliminary Results from a Case Study on two Reddit Communities
Paper and Code
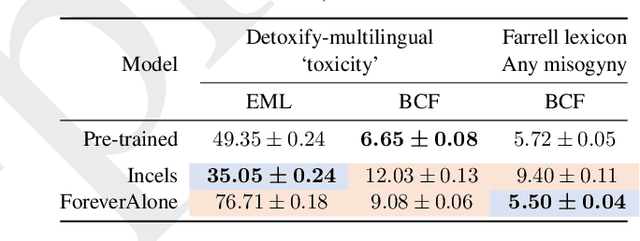
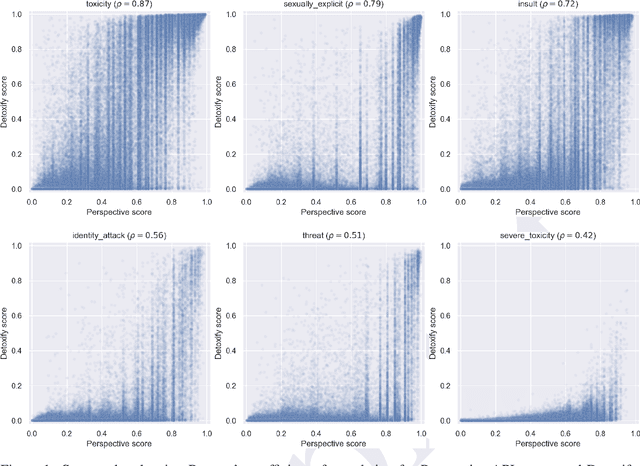


Generic `toxicity' classifiers continue to be used for evaluating the potential for harm in natural language generation, despite mounting evidence of their shortcomings. We consider the challenge of measuring misogyny in natural language generation, and argue that generic `toxicity' classifiers are inadequate for this task. We use data from two well-characterised `Incel' communities on Reddit that differ primarily in their degrees of misogyny to construct a pair of training corpora which we use to fine-tune two language models. We show that an open source `toxicity' classifier is unable to distinguish meaningfully between generations from these models. We contrast this with a misogyny-specific lexicon recently proposed by feminist subject-matter experts, demonstrating that, despite the limitations of simple lexicon-based approaches, this shows promise as a benchmark to evaluate language models for misogyny, and that it is sensitive enough to reveal the known differences in these Reddit communities. Our preliminary findings highlight the limitations of a generic approach to evaluating harms, and further emphasise the need for careful benchmark design and selection in natural language evaluation.