 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Actor-Critic with Cross-Entropy Policy Optimization
Dec 21, 2021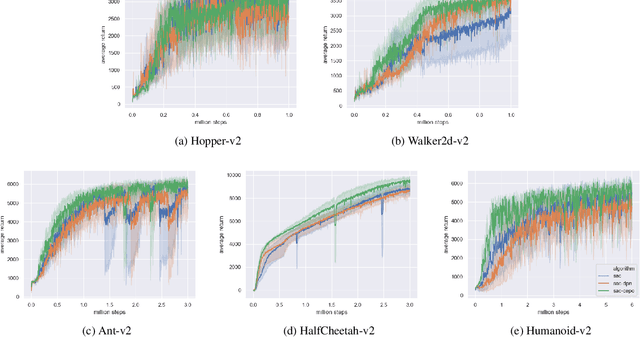

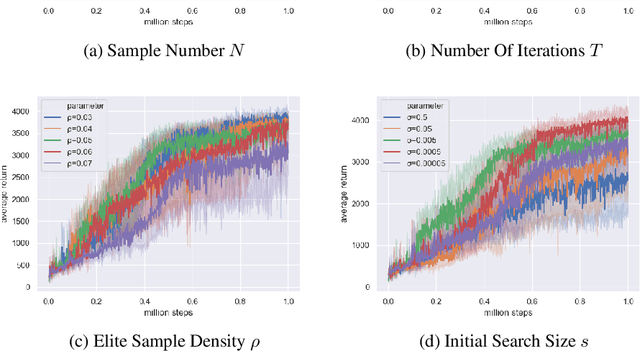

Soft Actor-Critic (SAC) is one of the state-of-the-art off-policy reinforcement learning (RL) algorithms that is within the maximum entropy based RL framework. SAC is demonstrated to perform very well in a list of continous control tasks with good stability and robustness. SAC learns a stochastic Gaussian policy that can maximize a trade-off between total expected reward and the policy entropy. To update the policy, SAC minimizes the KL-Divergence between the current policy density and the soft value function density. Reparameterization trick is then used to obtain the approximate gradient of this divergence. In this paper, we propose Soft Actor-Critic with Cross-Entropy Policy Optimization (SAC-CEPO), which uses Cross-Entropy Method (CEM) to optimize the policy network of SAC. The initial idea is to use CEM to iteratively sample the closest distribution towards the soft value function density and uses the resultant distribution as a target to update the policy network. For the purpose of reducing the computational complexity, we also introduce a decoupled policy structure that decouples the Gaussian policy into one policy that learns the mean and one other policy that learns the deviation such that only the mean policy is trained by CEM. We show that this decoupled policy structure does converge to a optimal and we also demonstrate by experiments that SAC-CEPO achieves competitive performance against the original SAC.
LiMIIRL: Lightweight Multiple-Intent Inverse Reinforcement Learning
Jun 03, 2021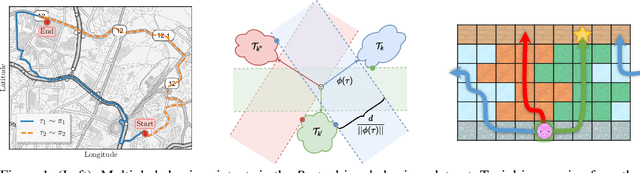
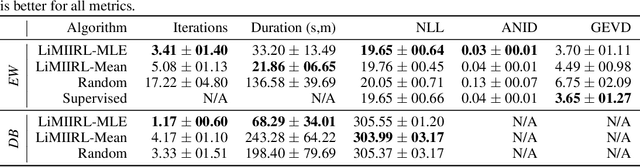
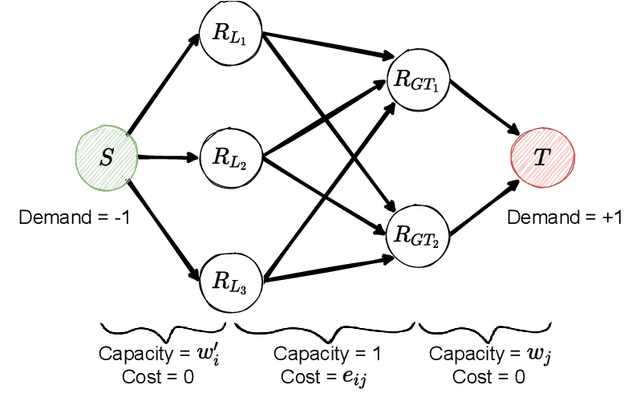
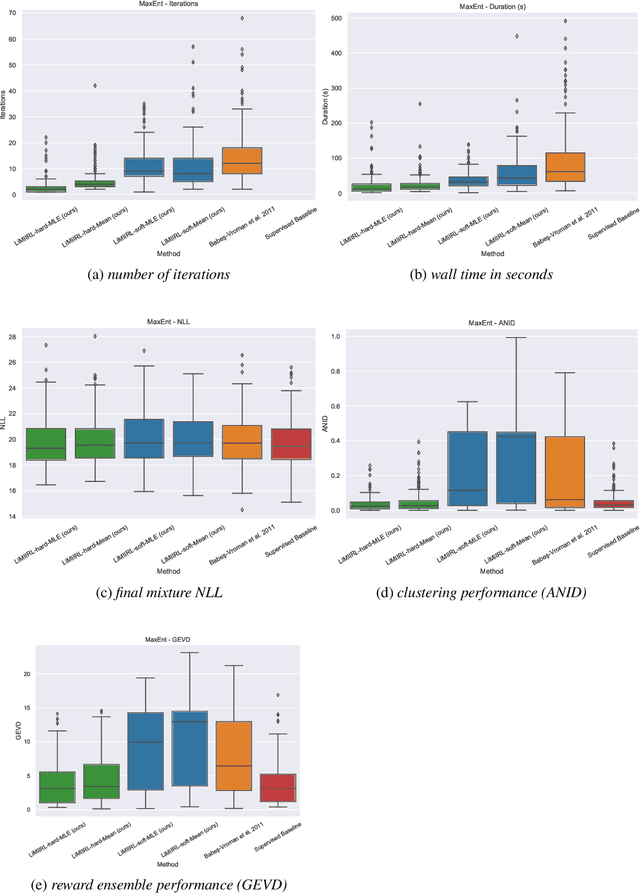
Multiple-Intent Inverse Reinforcement Learning (MI-IRL) seeks to find a reward function ensemble to rationalize demonstrations of different but unlabelled intents. Within the popular expectation maximization (EM) framework for learning probabilistic MI-IRL models, we present a warm-start strategy based on up-front clustering of the demonstrations in feature space. Our theoretical analysis shows that this warm-start solution produces a near-optimal reward ensemble, provided the behavior modes satisfy mild separation conditions. We also propose a MI-IRL performance metric that generalizes the popular Expected Value Difference measure to directly assesses learned rewards against the ground-truth reward ensemble. Our metric elegantly addresses the difficulty of pairing up learned and ground truth rewards via a min-cost flow formulation, and is efficiently computable. We also develop a MI-IRL benchmark problem that allows for more comprehensive algorithmic evaluations. On this problem, we find our MI-IRL warm-start strategy helps avoid poor quality local minima reward ensembles, resulting in a significant improvement in behavior clustering. Our extensive sensitivity analysis demonstrates that the quality of the learned reward ensembles is improved under various settings, including cases where our theoretical assumptions do not necessarily hold. Finally, we demonstrate the effectiveness of our methods by discovering distinct driving styles in a large real-world dataset of driver GPS trajectories.
Revisiting Maximum Entropy Inverse Reinforcement Learning: New Perspectives and Algorithms
Dec 01, 2020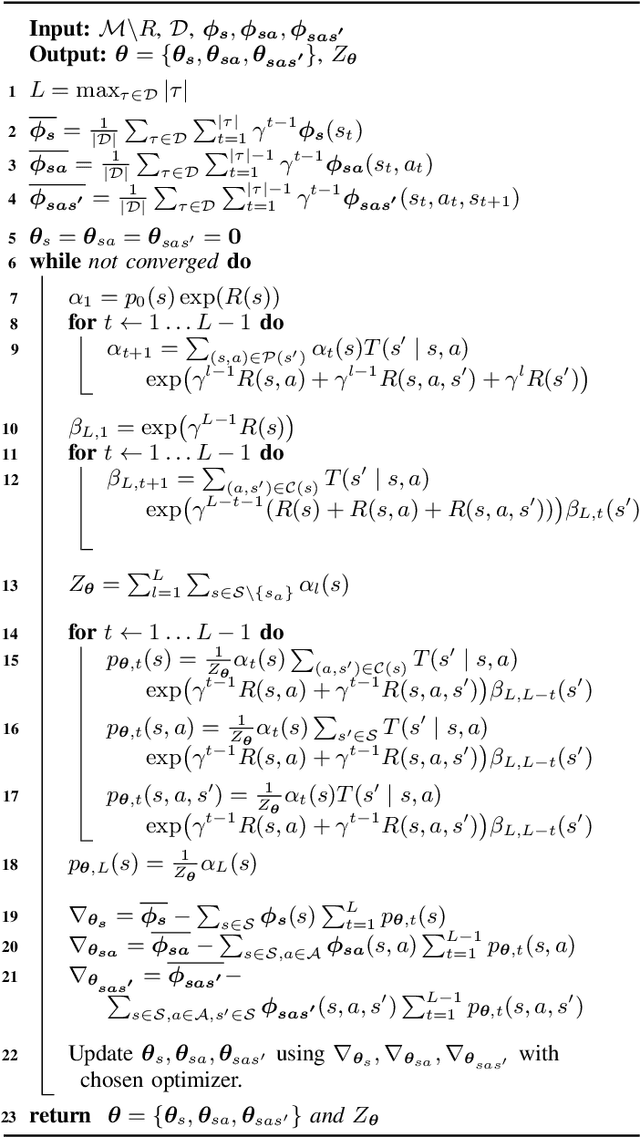
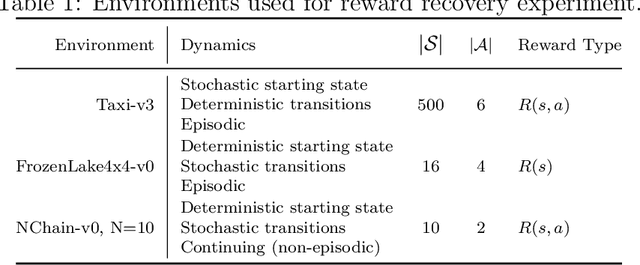
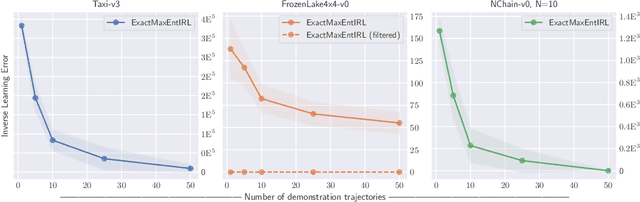
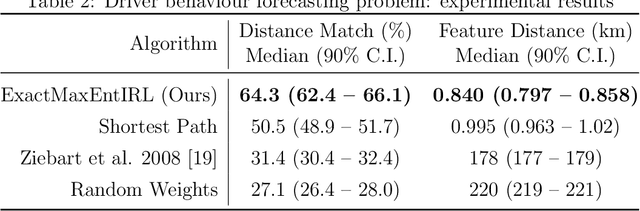
We provide new perspectives and inference algorithms for Maximum Entropy (MaxEnt) Inverse Reinforcement Learning (IRL), which provides a principled method to find a most non-committal reward function consistent with given expert demonstrations, among many consistent reward functions. We first present a generalized MaxEnt formulation based on minimizing a KL-divergence instead of maximizing an entropy. This improves the previous heuristic derivation of the MaxEnt IRL model (for stochastic MDPs), allows a unified view of MaxEnt IRL and Relative Entropy IRL, and leads to a model-free learning algorithm for the MaxEnt IRL model. Second, a careful review of existing inference algorithms and implementations showed that they approximately compute the marginals required for learning the model. We provide examples to illustrate this, and present an efficient and exact inference algorithm. Our algorithm can handle variable length demonstrations; in addition, while a basic version takes time quadratic in the maximum demonstration length L, an improved version of this algorithm reduces this to linear using a padding trick. Experiments show that our exact algorithm improves reward learning as compared to the approximate ones. Furthermore, our algorithm scales up to a large, real-world dataset involving driver behaviour forecasting. We provide an optimized implementation compatible with the OpenAI Gym interface. Our new insight and algorithms could possibly lead to further interest and exploration of the original MaxEnt IRL model.